本文大部分内容来自于 vdumoulin/conv_arithmetic
Convolution arithmetic
A technical report on convolution arithmetic in the context of deep learning.
The code and the images of this tutorial are free to use as regulated by the licence and subject to proper attribution:
- [1] Vincent Dumoulin, Francesco Visin - A guide to convolution arithmetic for deep learning (BibTeX)
Convolution animations
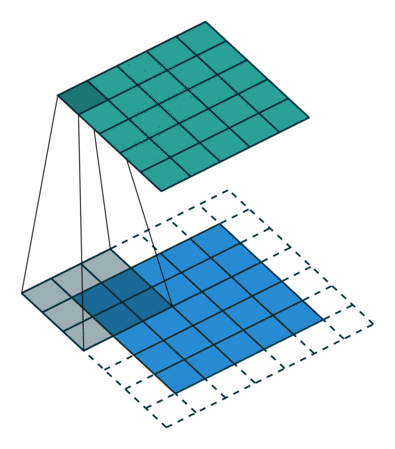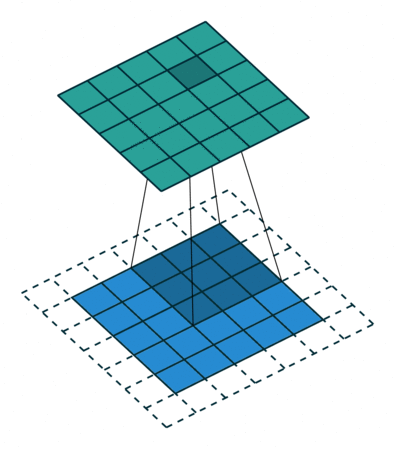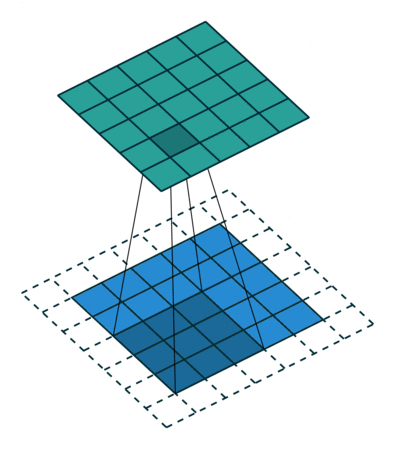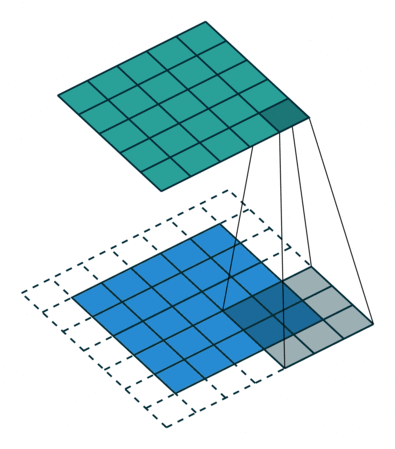
N.B.: 蓝色的 maps 是输入, 蓝绿色的 maps 是输出.(正常的卷积操作)
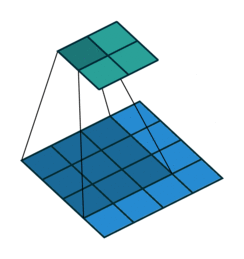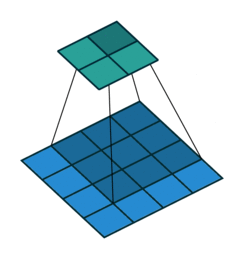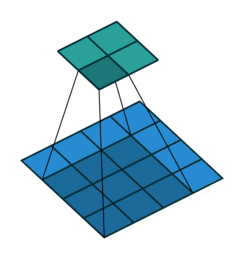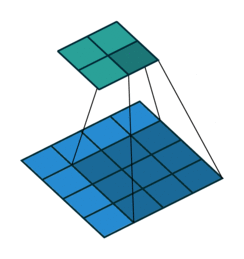 |
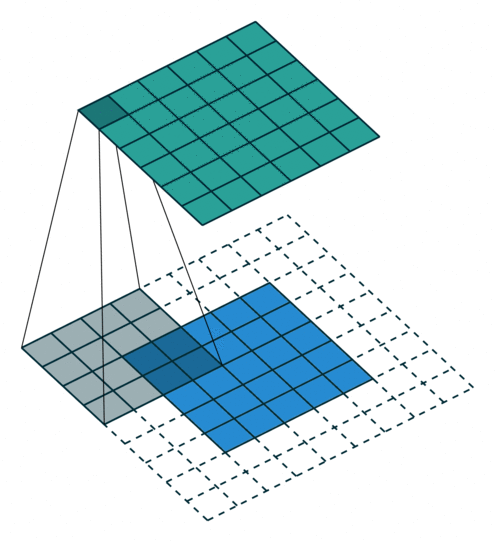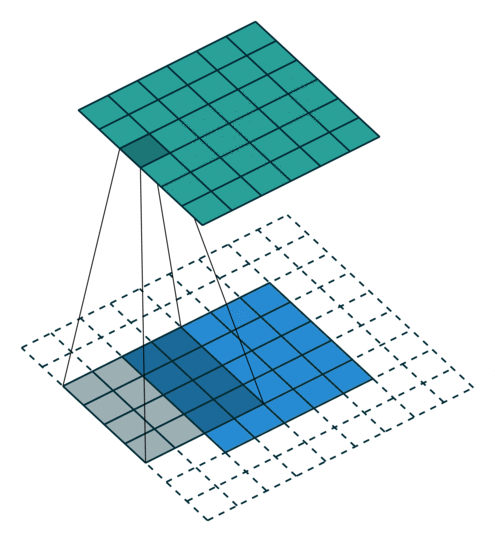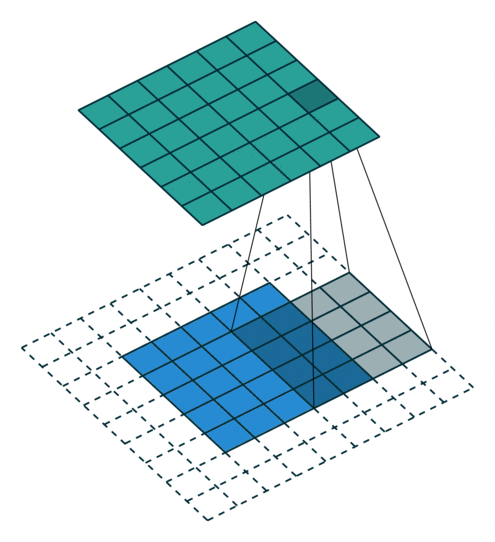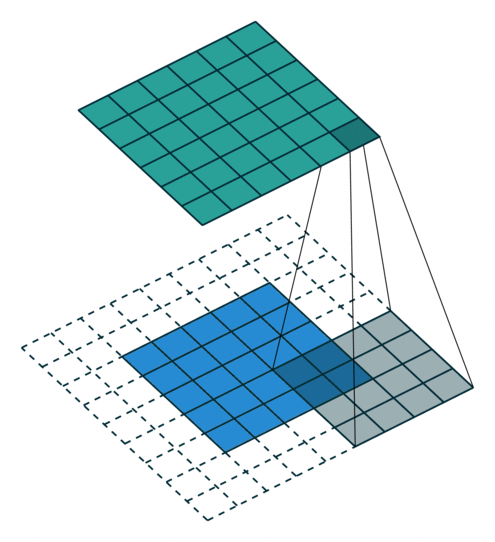 |
 |
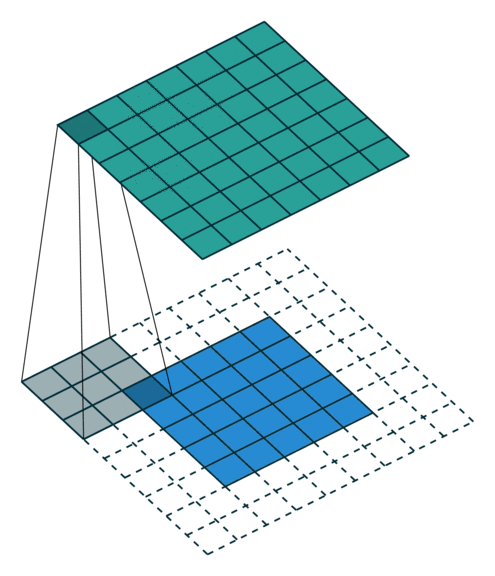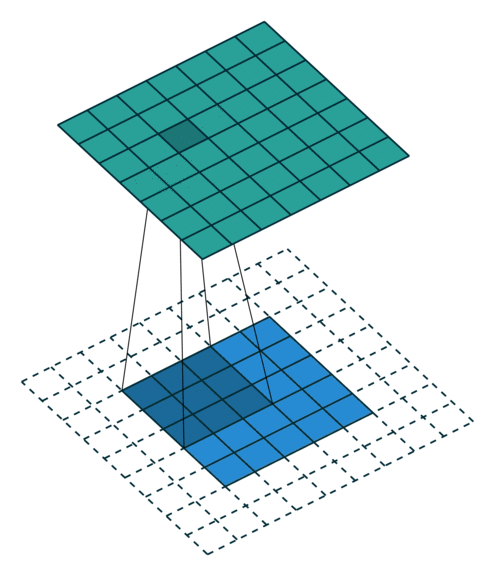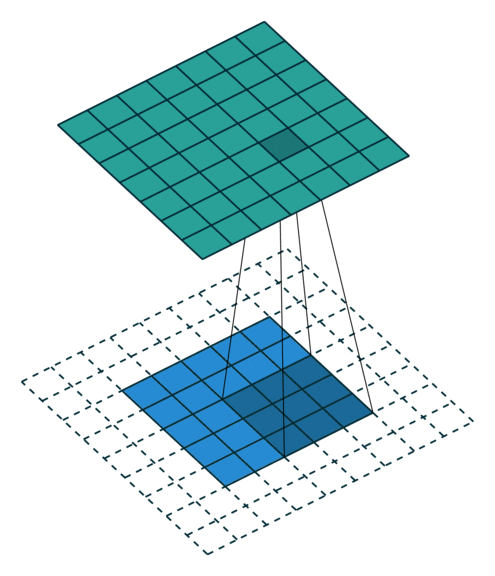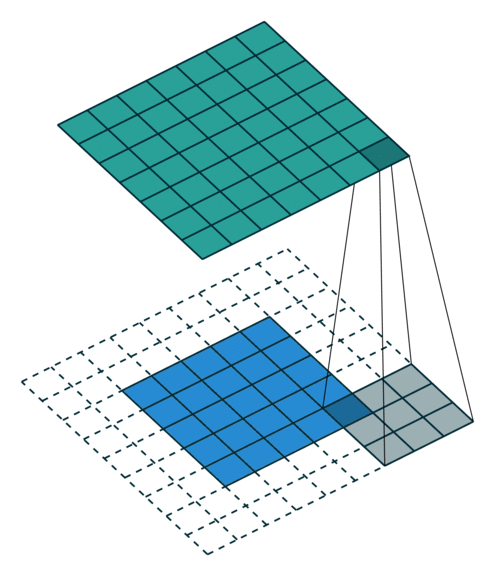 |
| No padding, no strides | Arbitrary padding, no strides | Half padding, no strides | Full padding, no strides |
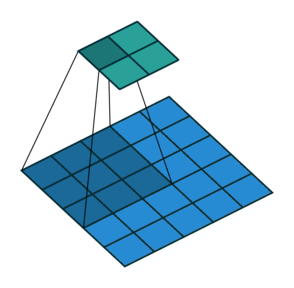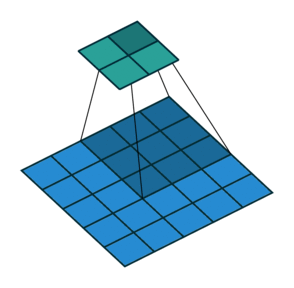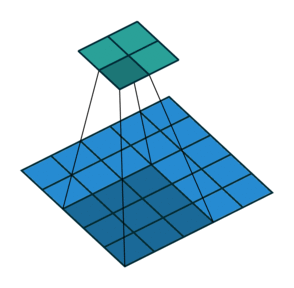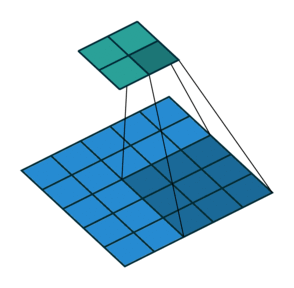 |
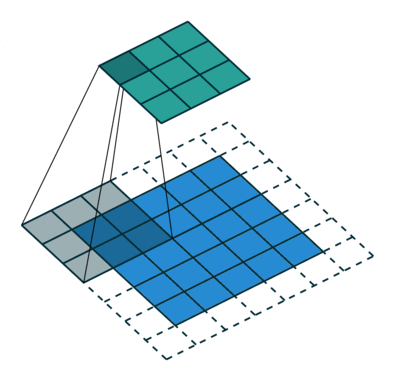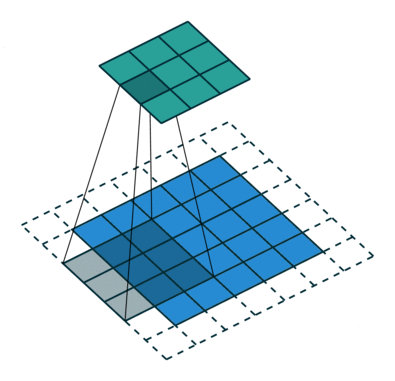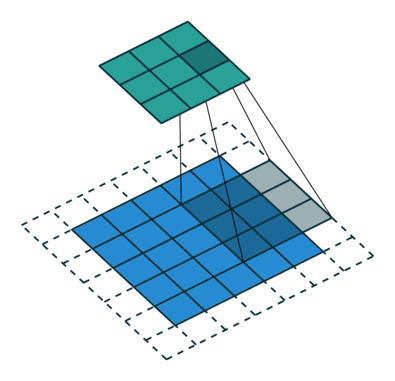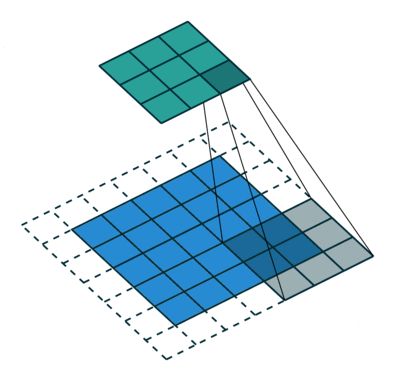 |
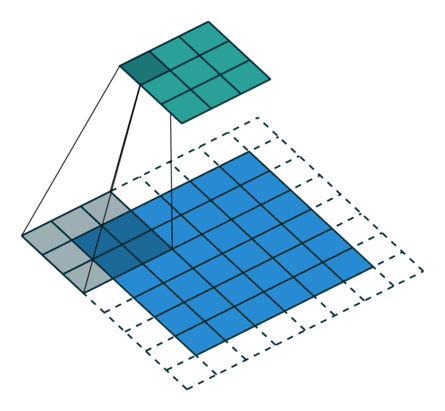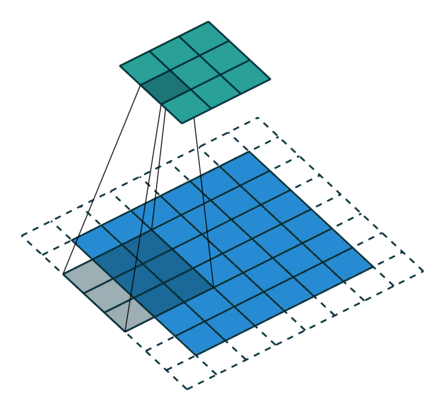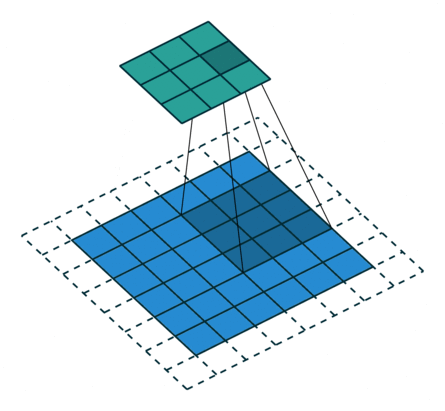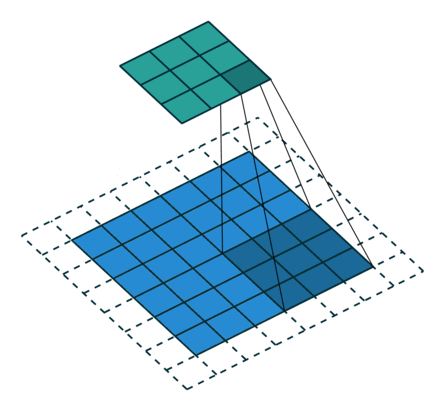 |
|
| No padding, strides | Padding, strides | Padding, strides (odd) |
Transposed convolution animations
N.B.: 蓝色的 maps 是输入, 蓝绿色的 maps 是输出. (转置卷积)
| No padding, no strides, transposed | Arbitrary padding, no strides, transposed | Half padding, no strides, transposed | Full padding, no strides, transposed |
| No padding, strides, transposed | Padding, strides, transposed | Padding, strides, transposed (odd) |
按照dive into deep learning 中的描述,转置卷积相对于普通卷积的区别就是,普通卷积是在一次卷积中,卷积核乘以相应大小的输入之后,会相加,最后变成一个输出,而转置卷积则是卷积核与输入中的一个值相乘,得到一个与卷积核大小一致的输出。
 一次反卷积计算中,0先跟kernel相乘,得到[[0,0],[0,0]],变成 2x2 的矩阵,并没有再相加为一个数,如如果是普通卷积操作,就会再相加成一个数
一次反卷积计算中,0先跟kernel相乘,得到[[0,0],[0,0]],变成 2x2 的矩阵,并没有再相加为一个数,如如果是普通卷积操作,就会再相加成一个数
下面是带步长的转置卷积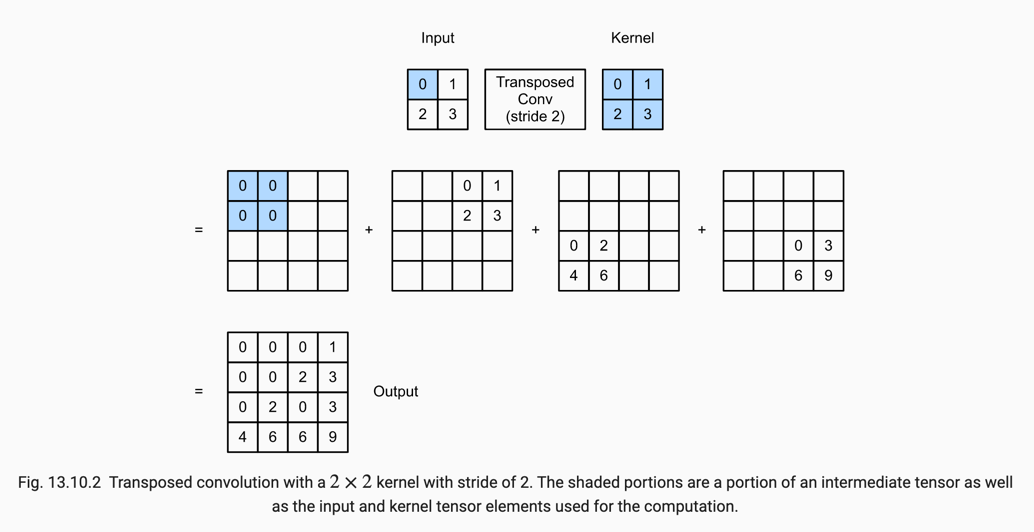
转置卷积通常也叫做反卷积,因为,普通的卷积操作,为了将卷积操作转换成矩阵相乘,在计算机中处理的时候是这个样子的 ( 图片来自于机器人博士 【图解】卷积和反卷积过程Convolution&Deconvolution )
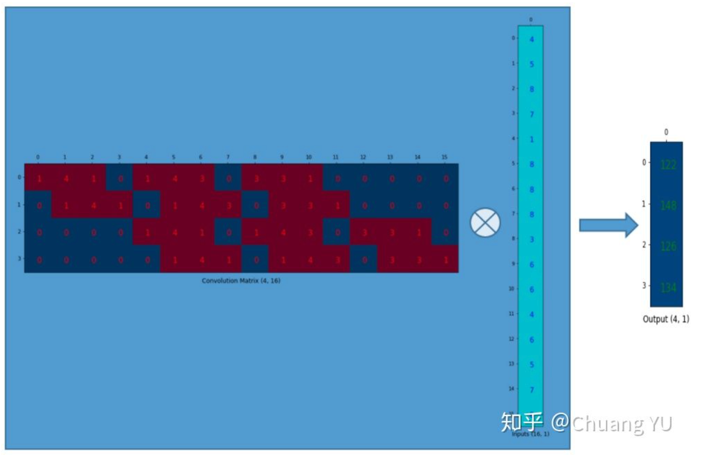
而在计算机计算转置卷积的时候,在计算机中处理的时候是这个样子的 ( 图片来自于机器人博士 【图解】卷积和反卷积过程Convolution&Deconvolution )
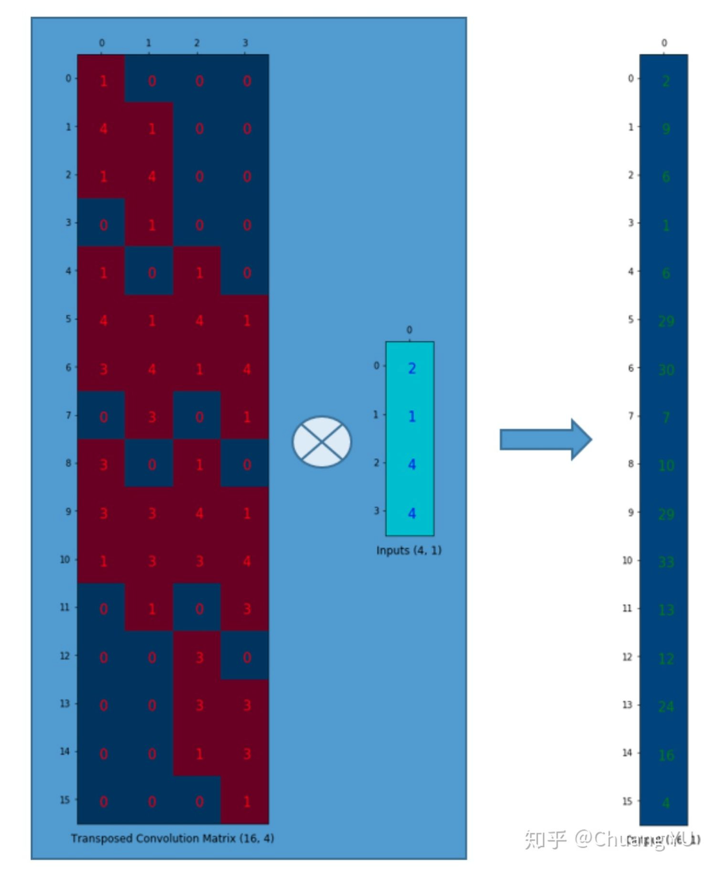 所以称转置卷积也叫反卷积。
所以称转置卷积也叫反卷积。
转置卷积通常能够使得输出变大,也就是常说的上采样,在U型网络中常常被用到,在pytorch中,上采样的方法还有 torch.nn.Upsample ,torch.nn.ReflectionPad2d 等 torch.nn.Upsample 通常我们可以理解为将每个元素进行重复,或者是重复之后按照特定规则做一下变换 例如下面就是简单的重复,参数不同,变换的规则不一样
input = torch.arange(1, 5, dtype=torch.float32).view(1, 1, 2, 2)
input
tensor([[[[ 1., 2.],
[ 3., 4.]]]])
m = nn.Upsample(scale_factor=2, mode='nearest')
m(input)
tensor([[[[ 1., 1., 2., 2.],
[ 1., 1., 2., 2.],
[ 3., 3., 4., 4.],
[ 3., 3., 4., 4.]]]])
torch.nn.ReflectionPad2d 指的是将输入添加padding,但是不是添加0,而是添加输入的镜像,效果如下:
m = nn.ReflectionPad2d(2)
input = torch.arange(9, dtype=torch.float).reshape(1, 1, 3, 3)
input
tensor([[[[0., 1., 2.],
[3., 4., 5.],
[6., 7., 8.]]]])
m(input)
tensor([[[[8., 7., 6., 7., 8., 7., 6.],
[5., 4., 3., 4., 5., 4., 3.],
[2., 1.,'0','1','2', 1., 0.],
[5., 4.,'3','4','5', 4., 3.],
[8., 7.,'6','7','8', 7., 6.],
[5., 4., 3., 4., 5., 4., 3.],
[2., 1., 0., 1., 2., 1., 0.]]]])
# 加上引号的部分是输入的值,其余的部分是padding的值,可以看到padding的值都是输入的镜像
Dilated convolution animations
N.B.: 蓝色的 maps 是输入, 蓝绿色的 maps 是输出. (Dilated: 膨胀的;扩张的)
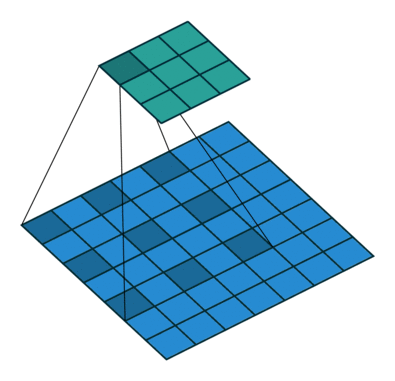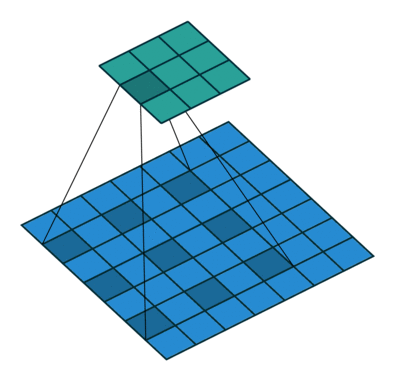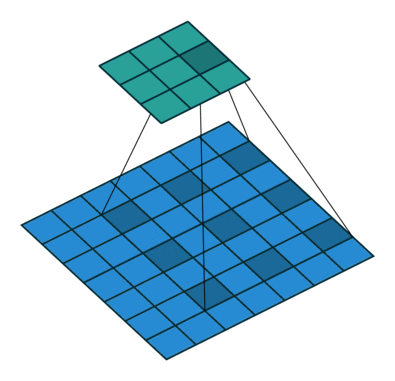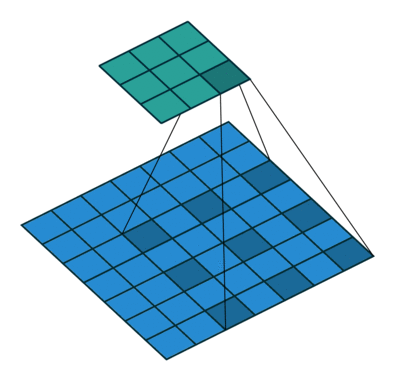 |
| No padding, no stride, dilation |
Partial Convolution
_N.B.: 偏置卷积 偏置卷积是 NVIDIA 公司的团队在2018年提出来的一种填充机制(padding scheme)。对于我们通常需要padding的大多数任务,换成 Partial Convolution ,都会有一些提升效果。 而且也没有过多的增加多少计算复杂度。
我们将会使用如下的图来解释 Partial Convolution 的基本原理
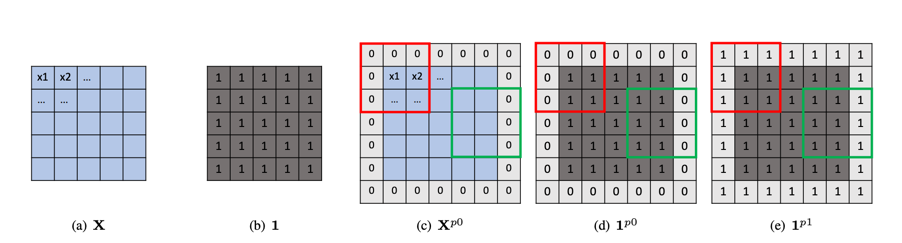
在图中(a)是我们的输入,(b)为跟(a)相同维度,值全为1的矩阵,(c)为将(a)进行用0进行填充一个单位的矩阵,(d)为将(b)进行用1进行填充的一个单位矩阵, (e)为将(b)进行用1进行填充一个单位的矩阵。其中红色框和绿色框指我们的卷积操作时候的卷积框。
对于常规的padding为0的卷积操作,比如图中的(c),我们计算卷积的方法为: \(W^T X_{(i\to i+k,j\to j+k)}^{p0}+b\) ,我们卷积核计算之后,计算的结果只与蓝色部位有关,而padding只是用来保持输出维度的, Partial Convolution 的思想是让padding也能够动态的学习,让卷积之后的结果也能依赖于padding,所以 Partial Convolution 中计算卷积时候,是这样计算的 \(W^T X_{(i\to i+k,j\to j+k)}^{p0} \frac{ {\left\Vert 1_{(i\to i+k,j\to j+k)}^{p1} \right\Vert }_1} { {\left\Vert 1_{(i\to i+k,j\to j+k)}^{p0} \right\Vert}_1}+b\) 这样操作的好处就是,在处理边缘的地方,以往常规的补0的 padding 之后的卷积操作,不考虑边缘,而现在相当于我们把卷积框内不填充的地方的值延伸到原来填充0的地方。 看起来这样似乎合理一些,因为对于一张图像,在小范围像素内通常像素的值是非常接近的。这个方法在普通的视觉任务中可能作用不大,但是在类似 Inpainting 的视觉任务中有比较好的效果。
本文由 louis 创作,采用 知识共享署名4.0 国际许可协议进行许可
github 地址 https://github.com/7568/7568.github.io
最后编辑时间为:2022-10-28