模型介绍
FFDNet: Toward a Fast and Flexible Solution for CNN based Image Denoising 是Kai Zhang, Wangmeng Zuo, Senior Member, IEEE, and Lei Zhang, Fellow, IEEE 等人在2018年发表的一篇关于图像去燥的文章 该文章在合成的高斯白噪声(AWGN)的图像上的去燥效果很好。本文将大概介绍一下这篇文章中具体使用的方法和代码的实现。
首先,它不是一个我们常用的U型网络,也没有使用到res_block,而这两个结构通常会被用到图像处理的任务中,在这篇文章 中,有人给FFDNet做了对比实验,发现其实加上参差块,去燥的效果是有提升的,但是幅度很小。
下图是FFDNet的整体结构:
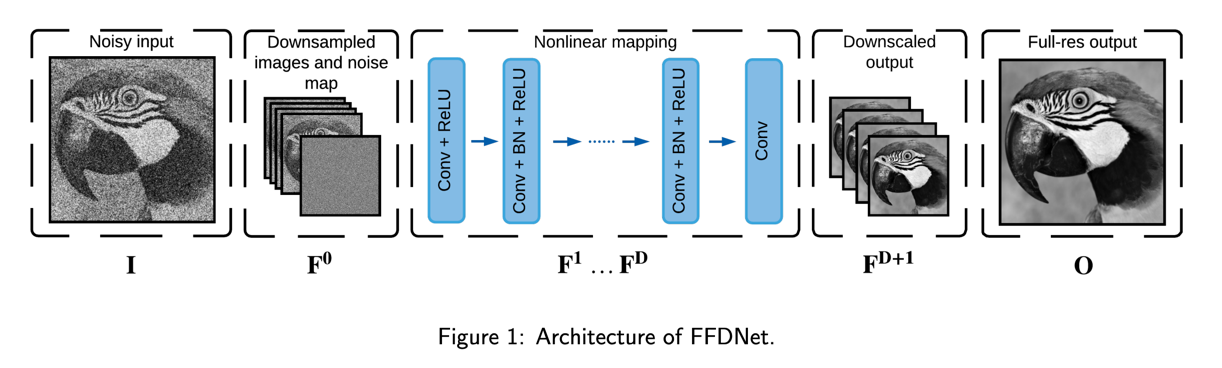
从图中我们可以看到有一个特别的地方,就是在输入到神经网络之前,原始的噪声图像有做一个处理,该处理的过程如下:(假设图像的维度为(c,w,h))
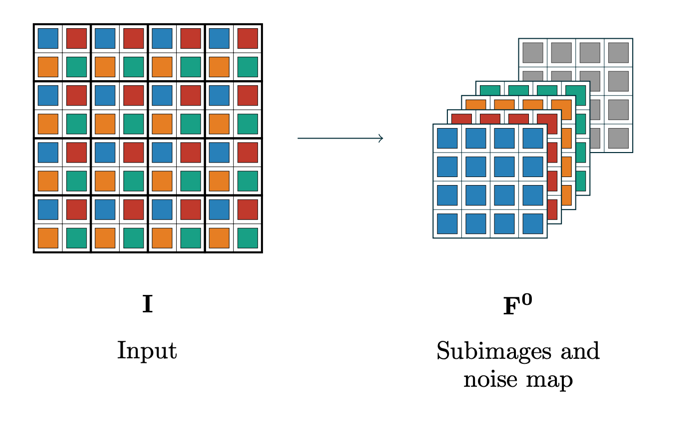
- 将图像中相邻的四个像素分成一个组,那么原始图像在某一个通道中,就被分成了 \(\lfloor w/4 \times h/4 \rfloor\) 个组,多余的部分舍弃掉。
- 将所有组中位置相同的像素提取出来,组成一个新的通道,于是原来c个通道就变成了 4\(\times\)c 个通道。
- 然后将4*c个通道的图像在拼接上噪声图,一起放入神经网络中
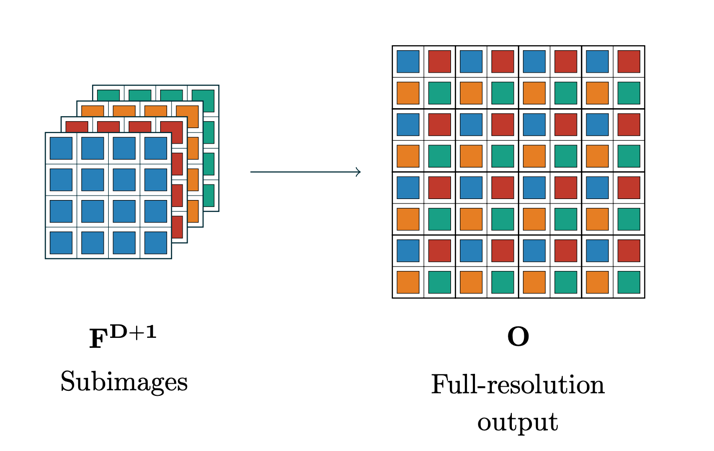
- 最后输出的通道数也为4 \(\times\) c,然后按照1的逆操作,将 4 \(\times\) c 个通道的图像,转换成c个通道的图像
步骤1的示意图如下:
步骤4的示意图如下:
实验过程
pytorch 版本的训练代码可以在这个地址下载 An Analysis and Implementation of the FFDNet Image Denoising Method ,里面还包含有一篇关于FFDNet的分析论文。
FFDNet使用的训练数据集为Waterloo Exploration Database ,和 BSD400 ,Waterloo Exploration Database数据集中有4744张图像彩色图像,BSD400是400张黑白图像。 FFDNet论文中的做法是随机的从这4744+400张图像切出 128\(\times\)8000 张小图,其中黑白小图的大小为 70\(\times\)70 ,彩色图像的大小为 50\(\times\)50 。 噪声范围为 \(\sigma \in [0, 75]\) ,均匀的从中随机选择。还使用了 rotation 和 flip 方法进行数据增强。
FFDNet训练时学习率在前50个epochs中是1e−3,然后在50-60个epochs中,将学习率调整为1e−4,剩下的epochs,学习率设置为 1e−6,总共训练了80个epochs。
FFDNet使用的验证集有两种,分别为黑白图像数据集和彩色图像数据集,BSD68和Set12用来进行黑白图像的去燥验证,CBSD68和 Kodak24 用来进行彩色图像的去燥验证
在 这里 也有很多数据集可以下载
所有实验所需的数据集都可以在xinntao / BasicSR 和 cszn / DnCNN 中找到下载地址。
在 An Analysis and Implementation of the FFDNet Image Denoising Method 的代码中,我们可以看到有 prepare_patches.py 、train.py 和 test_ffdnet_ipol.py 。
数据预处理
我们通过 prepare_patches.py 文件来进行训练数据的预处理,在 prepare_patches.py 中,有一个判断参数 args.gray 所以我认为 FFDNet 的实验是将彩色图像和黑白图像单独训练,单独验证的。该问题我在github上向作者提问过了,但到目前还没有得到回复。
所以接下来我们的实验只针对彩色图像进行训练。
首先我们将 args.gray 参数改成 False , 然后将 args.trainset_dir 参数设置为 Waterloo Exploration Database 数据集的存放路径,将 args.valset_dir 参数设置为 Kodak24 数据集的存放路径。
在 dataset.py 文件中有个 prepare_data 方法,这个方法就是专门进行数据准备工作的。该方法整体的工作流程为:
- 在
dataset.py文件所在的目录创建两个文件,分别为 ‘train_rgb.h5’ 和 ‘val_rgb.h5’ , 分别用来存放处理过的训练文件和验证文件。 - 遍历训练集中的所有图像,将他们分别按 [1, 0.9, 0.8, 0.7] 进行缩放,就得到了4张图像,对每一张图像进行归一化,再从图像中进行
img_to_patches操作,就是从图像中获得patchs, 获得 patchs 的方式很简单,就是从图像左上角开始,框处一个 70 x 70 的小图(训练时我们将 patchs 的大小设置为了 70 x 70 ),将来每一个 patch 将会被送进神经网络当作一张图像进行训练。 当得到一个patch之后,再将 patch 的框右移动一个 stride 的距离,得到第二个 patch 的,并依次下去,当一横排弄完了,就将 patch 的框向下移动一个 stride 的距离,依次下去。 - 在得到patchs之后,我们再将每个patch进行 data_augmentation 操作,即数据增强操作。data_augmentation 中分别有’不做任何操作’,’上下返转’,’逆时针90度旋转’,’逆时针90度旋转再上下返转’,’逆时针180度旋转’,’逆时针180度旋转再上下返转’,’逆时针270度旋转’,’逆时针270度旋转再上下返转’,共8种操作。当我们进行数据增强的时候,我们随机的挑出一个进行处理。
- 将每一个patch依次存放到 ‘train_rgb.h5’ 中。存放的格式为key-value的机构,这一点我有点奇怪,为什么不直接将 patchs 转换成 numpy,然后以数组的方式存放到 ‘train_rgb.h5’ 中。
- 将验证集中的所有图像进行归一化,然后存放到 ‘val_rgb.h5’ 中。只进行了归一化,没有任何其他操作。
以下是我的配置参数:
parser = argparse.ArgumentParser(description=\
"Building the training patch database")
parser.add_argument("--gray", action='store_true',default=False,\
help='prepare grayscale database instead of RGB')
# Preprocessing parameters patch的长和宽
parser.add_argument("--patch_size", "--p", type=int, default=70, \
help="Patch size")
parser.add_argument("--stride", "--s", type=int, default=40, \
help="Size of stride")
parser.add_argument("--max_number_patches", "--m", type=int, default=None, \
help="Maximum number of patches")
parser.add_argument("--aug_times", "--a", type=int, default=1, \
help="How many times to perform data augmentation")
# Dirs
parser.add_argument("--trainset_dir", type=str, default=None, \
help='path of trainset')
parser.add_argument("--valset_dir", type=str, default=None, \
help='path of validation set')
最终得到的 ‘train_rgb.h5’ 大小为82G。总共有1474229个patch。
我们进行数据预处理的目的是为了将来进行训练的时候,不用每个迭代都进行数据预处理依次,增加训练的速度。
接下来我们开始FFDNet的训练。
开始训练
在 train.py 中,我们有两个 ‘Dataset’ 的class,他们负责训练数据和测试数据的读取。由于我们是按照原论文,每个迭代128*8000个patch,所以我们将 __len__方法中的 return len(self.keys) 改成 return 128*8000 ,
然后我们在 __getitem__ 方法中添加 ` if index==0: random.shuffle(self.keys)` ,这样每一个epoche使用的数据就都不一样了。
训练图像的噪声是在每一次训练的时候加上去的。噪声代码如下:
# inputs: noise and noisy image
img_train = data
noise = torch.zeros(img_train.size())
# 先从 0到75之间分别均匀的取出 noise.size()[0] 个整数
stdn = np.random.uniform(args.noiseIntL[0], args.noiseIntL[1], \
size=noise.size()[0])
for nx in range(noise.size()[0]):
sizen = noise[0, :, :, :].size()
# 先随机生成一个 sizen 大小的 噪声,然后进行归一化处理,归一化中的方差就是噪声的程度。
noise[nx, :, :, :] = torch.FloatTensor(sizen). \
normal_(mean=0, std=stdn[nx])
imgn_train = img_train + noise
在 An Analysis and Implementation of the FFDNet Image Denoising Method 的代码中,需要在记录日志的地方,将 ‘loss.data[0]’改成’loss.item()’ 。还会有几个地方会因为方法的过期,导致报 “UserWarning” ,这个可以不用管。
然后就可以开始训练了。
DnCNN介绍
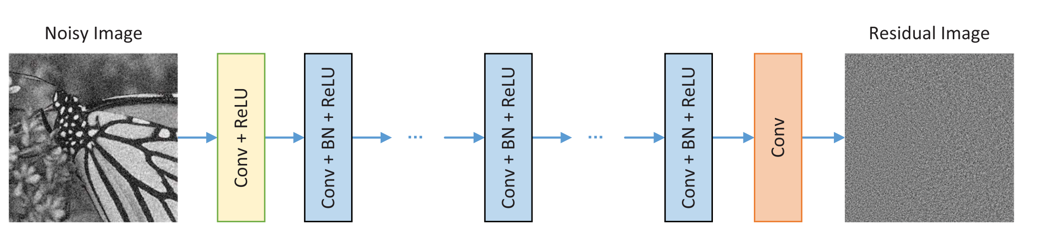
FFDNet 是在 DnCNN 的基础上进行修改得到的, DnCNN 的思想是使用一个带残差、BN、和ReLU结构的神经网络来从噪声图像中获取噪声,这样将噪声图像减去噪声就可以得到一张干净的图像了。
DnCNN 的结构如下图所示:
修改代码
NOTE 最新更新 :本文使用的原始代码是从 An Analysis and Implementation of the FFDNet Image Denoising Method 下载的,经过几天的调试,代码终于跑起来了,但是发现个问题,该地址中的模型 看上去并不是原始的FFDNet的模型,因为我们到它模型输出的是噪声,并不是输出的干净的图像。我也是调试了几天才发现的,中间有很长时间在下载数据集。 但是大部分代码都是可用的,所以我决定修改该代码,修改完成后我将会上传到github上。
查看代码可以发现,其实模型的结构还是FFDNet的,只是计算损失的时候使用了noise,所以只需要将损失函数修改以下就可以了。
本文由 louis 创作,采用 知识共享署名4.0 国际许可协议进行许可
github 地址 https://github.com/7568/7568.github.io
最后编辑时间为:2022-10-28