引言
在机器学习中,有各种个样的损失函数,不同的损失函数对于不同的任务通常会有不同的效果,而且在有些任务中,大家会使用多个损失函数联合起来,一起训练网络。 本文将搜集一些以前人们设计出来的损失函数。
L1 Loss
对于一个 Batch Size 为 N 的样本,首先我们计算输入\(x\)和目标\(y\)中每个元素的绝对误差,方法如下:
\[\ell(x, y) = L = \{l_1,\dots,l_N\}^\top, \quad l_n = \left| x_n - y_n \right|\]然后我们对 N 个绝对误差可以选择求和或者取平均,这样就得到了一个 Batch 的L1 Loss。
\[\ell(x, y) = \begin{cases} \operatorname{mean}(L), & \text{if reduction} = \text{'mean';}\\ \operatorname{sum}(L), & \text{if reduction} = \text{'sum'.} \end{cases}\]L1 Loss 通常比较适用于回归任务,也可以用于分类任务。L1 Loss 的缺点是在0的位置不可导。L1 Loss 的函数图会与 SmoothL1 Loss 和 L2 Loss 放在 L2 Loss 部分一起做对比。
SmoothL1 Loss
SmoothL1 Loss 是在 L1 Loss 进行的修改,使得 L1 Loss 的在 0 的位置变得可导。
对于一个 Batch Size 为 N 的样本,首先我们还是要的到输入\(x\)和目标\(y\)中每个元素的误差。
\[\ell(x, y) = L = \{l_1,\dots,l_N\}^\top\]计算误差的方法如下:
\[l_{i} = \begin{cases} 0.5 (x_i - y_i)^2/beta, & \text{if } |x_i - y_i| < beta \\ |x_i - y_i| - 0.5 * beta, & \text{otherwise } \end{cases}\]然后我们对 N 个误差可以选择求和或者取平均,这样就得到了一个 Batch L1 Loss。
\[\ell(x, y) = \begin{cases} \operatorname{mean}(L), & \text{if reduction} = \text{'mean';}\\ \operatorname{sum}(L), & \text{if reduction} = \text{'sum'.} \end{cases}\]SmoothL1 Loss 是 L1 Loss 的改进版本,通常在使用 L1 Loss 的地方都能使用 SmoothL1 Loss ,对于不同的任务,他们俩应该是会有稍微的不同。 SmoothL1 Loss 的函数图会与 L1 Loss 和 L2 Loss 放在 L2 Loss 部分一起做对比。
L2 Loss(MSELoss)
L2 Loss 与 L1 Loss 其实是很相近的,不同点是 L1 Loss 计算的是两个元素的绝对距离,而 L2 Loss 计算的是两个元素的均方误差。 对于一个 Batch Size 为 N 的样本,计算方式如下:
\[\ell(x, y) = L = \{l_1,\dots,l_N\}^\top, \quad l_n = \left( x_n - y_n \right)^2\]然后我们对 N 个误差可以选择求和或者取平均,这样就得到了一个 L2 Loss。
\[\ell(x, y) = \begin{cases} \operatorname{mean}(L), & \text{if reduction} = \text{'mean';}\\ \operatorname{sum}(L), & \text{if reduction} = \text{'sum'.} \end{cases}\]通常 L2 Loss ,L1 Loss 和 SmoothL1 Loss,他们的适用范围是一样的。我们在实际的深度学习任务中,可以都尝试以下这三个方法,比较他们之间的差别,从而可以得到当前任务合适的 Loss。
L2 Loss ,L1 Loss 和 SmoothL1 Loss 他们的对比图如下:
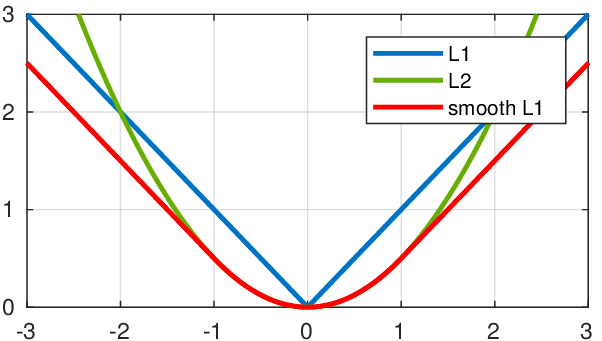
CrossEntropy Loss
CrossEntropy Loss 也叫交叉熵损失函数。该损失函数通常用于深度学习中的分类任务。比如分类任务的类别为\(C\),那么我们可以将类别用\(class = [0,1,...,C-1]\)来标志类别。
对于一个样本,假设经过神经网络之后,得到的输出为\(x\),则\(x\)的内容应该是这样的:\(x=[x_1,x_2,\dots,x_{c-1}]\),其中\(x_i\)指的是输入样本为第\(i-1\)类的概率。 那么计算\(x\)的交叉熵损失为:
\[\text{loss}(x, class) = -\log\left(\frac{\exp(x[class])}{\sum_j \exp(x[j])}\right) = -x[class] + \log\left(\sum_j \exp(x[j])\right)\]而对于 Batch Size 为 N 的输入,假设得到的输出为\(x\),实际的类别为\(y\),CrossEntropy Loss 的计算方式如下:
\[\ell(x, y) = L = \{l_1,\dots,l_N\}^\top, \quad l_n = -w_{yn}\log\frac{exp(x_{n,y_n})}{\sum_{c=1}^C exp(x_{n,c})}*1{\{y_n \neq ignore\_index\}}\]其中\(ignore\_index\)指的是不计算损失的类别。\(w_{yn}\)指的是手动设置的每个类别的权重,我个人猜想应该是对于一些分布不均匀的数据,可能会用得到。
然后我们对 N 个结果可以选择求和或者取平均,这样就得到了一个 CrossEntropy Loss。
\[\ell(x, y) = \begin{cases} \sum_{n=1}^N \frac{1}{\sum_{n=1}^{N}w_{yn}}*1{\{y_n \neq ignore\_index\}} , & \text{if reduction} = \text{'mean';}\\ \sum_{n=1}^N l_n, & \text{if reduction} = \text{'sum'.} \end{cases}\]NLL Loss
NLL Loss 为 negative log likelihood loss 的缩写,基本上只用于分类任务。一般在使用 NLL Loss 时候,网络的最后一层通常为 LogSoftmax 。 NLL Loss 计算方式如下:
\[\ell(x, y) = L = \{l_1,\dots,l_N\}^\top, \quad l_n = -w_{yn}log(x_{n,y_n}), w_c = weight[c]*1{\{c \neq ignore\_index\}}\]通俗的解释就是对于一个分类任务,我们的网络经过了最后一层的 LogSoftmax 输出,得到预测为正确的那一类的概率为\(p\),那么此时该预测的损失就为\(-log(p)\)。
对于一个 batch ,计算该 batch 的 NLL Loss 为:
\[\ell(x, y) = \begin{cases} \sum_{n=1}^N \frac{1}{\sum_{n=1}^{N}w_{yn}}*l_n , & \text{if reduction} = \text{'mean';}\\ \sum_{n=1}^N l_n, & \text{if reduction} = \text{'sum'.} \end{cases}\]本内容还参考于Lj Miranda 的 blog 内容 。
PoissonNLL Loss
PoissonNLL Loss 是一个专项的损失,只有当我们确定我们要预测的结果服从泊松分布的时候,才能使用该 loss,一般用于回归任务中。
KLDiv Loss
KLDiv Loss 指的是 The Kullback-Leibler divergence loss measure。在统计学中 Kullback-Leibler divergence 用于测量两个 概率分布的差异。通常用于回归任务中输出为空间连续分布的任务。KLDiv Loss 可表达为如下:
\[l(x,y) = L = \{ l_1,\dots,l_N \}, \quad l_n = y_n \cdot \left( \log y_n - x_n \right)\]对于一个 batch 的损失的计算为:
\[\ell(x, y) = \begin{cases} \operatorname{mean}(L), & \text{if reduction} = \text{'mean';} \\ \operatorname{sum}(L), & \text{if reduction} = \text{'sum'.} \end{cases}\]BCE Loss
BCE Loss 指的是 Binary Cross Entropy Loss,即二元交叉熵损失。一般只用于二分类任务中。BCE Loss 可表达为如下:
\[\ell(x, y) = L = \{l_1,\dots,l_N\}^\top, \quad l_n = - w_n \left[ y_n \cdot \log x_n + (1 - y_n) \cdot \log (1 - x_n) \right],\]其中 \(y_n \in {0,1}\)。
对于一个 batch 的损失的计算为:
\[\ell(x, y) = \begin{cases} \operatorname{mean}(L), & \text{if reduction} = \text{'mean';}\\ \operatorname{sum}(L), & \text{if reduction} = \text{'sum'.} \end{cases}\]BCEWithLogits Loss
对于二分类任务,通常我们在网络的最后一层接 sigmoid 激活函数,然后我们使用过 BCE Loss 损失函数来计算损失,从而进行反向跟新参数。BCEWithLogits Loss 的思想是我们的网络的最后一层 不用 sigmoid 激活函数,而是直接输出,然后将 sigmoid 激活函数放到损失函数中。所以 BCEWithLogits Loss 是在损失函数中结合了 BCE Loss 和 sigmoid 激活函数。计算公式如下:
\[\ell(x, y) = L = \{l_1,\dots,l_N\}^\top, \quad l_n = - w_n \left[ y_n \cdot \log \sigma(x_n) + (1 - y_n) \cdot \log (1 - \sigma(x_n)) \right],\]其中 \(y_n \in {0,1}\)。
对于一个 batch 的损失的计算为:
\[\ell(x, y) = \begin{cases} \operatorname{mean}(L), & \text{if reduction} = \text{'mean';}\\ \operatorname{sum}(L), & \text{if reduction} = \text{'sum'.} \end{cases}\]HingeEmbedding Loss
对于目标输出为 1 和 -1 的二分类问题,计算预测输出与目标输出之间的相似性或者是差异性,就可以用到 HingeEmbedding Loss,计算公式如下:
\[L = \{l_1,\dots,l_N\}^\top , l_n = \begin{cases} x_n, & \text{if}\; y_n = 1,\\ \max \{0, \Delta - x_n\}, & \text{if}\; y_n = -1, \end{cases}\]其中\(\Delta\)为手动指定的边界值,在 pytorch 中默认为 1。
对于一个 batch 的损失的计算为:
\[\ell(x, y) = \begin{cases} \operatorname{mean}(L), & \text{if reduction} = \text{'mean';}\\ \operatorname{sum}(L), & \text{if reduction} = \text{'sum'.} \end{cases}\]MultiMargin Loss
MultiMargin Loss 通常适用于单个样本只属于某一类的多分类任务。中文名叫多分类合页损失函数。该损失的计算公式如下:
\[\text{loss}(x, y) = \frac{\sum_i \max(0, \text{margin} - x[y] + x[i]))^p}{\text{x.size}(0)}\]通常 \(p\)为1或者2。
其中 \(x \in \left\{0, \; \cdots , \; \text{x.size}(0) - 1\right\} i \neq y\)
MultiLabelMargin Loss
MultiLabelMargin Loss 通常适用于单个样本属于多个分类的多分类任务。计算公式如下:
\[\text{loss}(x, y) = \sum_{ij}\frac{\max(0, 1 - (x[y[j]] - x[i]))}{\text{x.size}(0)}\]其中 \(x \in \left\{0, \; \cdots , \; \text{x.size}(0) - 1\right\} , y \in \left\{0, \; \cdots , \; \text{y.size}(0) - 1\right\} , 0 \leq y[j] \leq \text{x.size}(0)-1 , i \neq y[j]\)
SoftMargin Loss
软边界是相对于硬边界而言的,在硬边界中,预测错误有损失,预测正确没有损失,而在软边界中,预测正确和错误都有损失。
SoftMarginLoss 的适用范围是二分类问题,且目标的分类标签为 1 和 -1 。计算公式如下:
\[\text{loss}(x, y) = \sum_i \frac{\log(1 + \exp(-y[i]*x[i]))}{\text{x.nelement}()}\]其中\(\text{x.nelement}()\)为 batch 的 size。
如果一个样本的预测分类为正确,那么损失\(loss = \frac{\log(1 + frac{1}{e})}{\text{x.nelement}()}\) ,如果为错误,那么损失\(loss = \frac{\log(1 + e)}{\text{x.nelement}()}\), 显然 \(\log(1 + e) > \log(1 + \frac{1}{e})\),也就是说不管预测是否是正确,都会有损失,但是预测错误的话,损失会更大。在有些情况下可以试试该方法,可能会有好的效果。
MultiLabelSoftMargin Loss
MultiLabelSoftMargin Loss 适用于多标签的分类任务。与 MultiLabelMargin Loss 相对应。对一个样本的计算公式如下:
\[loss(x, y) = - \frac{1}{C} * \sum_i y[i] * \log((1 + \exp(-x[i]))^{-1}) + (1-y[i]) * \log\left(\frac{\exp(-x[i])}{(1 + \exp(-x[i]))}\right)\]其中 \(i \in \left\{0, \; \cdots , \; \text{x.nElement}() - 1\right\}\) ,\(y[i] \in \left\{0, \; 1\right\}\)
对于一个样本,\(x\)是一个\(C\)维的向量,每个元素维0或者1,表示该样本是否属于该分类。\(y\)是与\(x\)维度一样的向量。
CosineEmbedding Loss
当我们要比较两个输入\(x_1 , x_2\)是否相似或者不相似的时候,我们就可以使用该 loss 函数,比如我们要比较两张图像是否是同一个人,我们在通过了卷积之后,得到两张图像的特征,通过该函数就可以比较两个特征是否是同一个人的特征。 计算公式如下:
\[\text{loss}(x, y) = \begin{cases} 1 - \cos(x_1, x_2), & \text{if } y = 1 \\ \max(0, \cos(x_1, x_2) - \text{margin}), & \text{if } y = -1 \end{cases}\]其中 \(\text{margin}\) 是手动设置的值,一般可以通过 grid 搜索来得到最优值。
MarginRanking Loss
当我们要比较两个输入\(x_1 , x_2\)大小关系的时候,我们可以使用该 loss,计算公式如下:
\[\text{loss}(x, y) = \max(0, -y * (x1 - x2) + \text{margin})\]如果\(y=1\)则应该\(x_1 > x_2\),否则就应该\(x_1 < x_2\)。\(\text{margin}\)为手动设置的值。
TripletMargin Loss
TripletMargin Loss 适用于比较三个输入\(x_1 , x_2 , x_3\),比如我们的预期目标是\(x_1>x_2\),和 \(x_1 > x_3\),那么我们就可以用以下的表达式来计算 loss
\[L(x_1, x_2, x_3) = \max \{d(x_1, x_2) - d(x_1, x_3) + {\rm margin}, 0\}\]其中\(d(x_i, y_i) = \left\lVert {\bf x}_i - {\bf y}_i \right\rVert_p\)
CTC Loss
CTC Loss 表示 The Connectionist Temporal Classification loss。在对于连续性数据进行神经网络训练的时候,我们通常会将连续性的数据进行切片,然后将切片后的数据放入到神经网络中,比如一段音频数据, 我们先按照固定长度的时间,将音频数据切分成一段一段的小片段,然后我们将小片段先放进到CNN中,获得每个小片段的特征,然后将特征放入到RNN或者别的带记忆功能的网络中,进行encoder,得到编码之后的 数据,最后我们将编码之后的数据进行据测,得出该音频数据对于的文字内容。那么在对音频数据进行切片的时候,就会出现比如 hello 的发音,其中的 o 的音被切成了好多个小片段,以至于最终进行预测的时候,可能就预测成了hellooooo,该结果显然是 错误的,于是我们就可以使用 CTC loss,CTC loss 中会使用一种叫做 beam search 的方法,来去除掉冗余的结果,从而使得结果正确。
更多关于 CTC Loss 的内容请参考:
An Intuitive Explanation of Connectionist Temporal Classification
本文由 louis 创作,采用 知识共享署名4.0 国际许可协议进行许可
github 地址 https://github.com/7568/7568.github.io
最后编辑时间为:2022-10-28