简介
Learning both Weights and Connections for Efficient Neural Networks 是 Song Han 在Stanford大学2016年的时候发表的一篇关于网络如何减少参数的论文。
Abstract
神经网络对计算和存储的要求都很高,使得他们一般很难部署到嵌入式系统中。而且,常规的网络在训练之前他的结构都是固定的,所以导致的结果就是训练的时候不能实时的优化结构。为了处理这一限制,我们提出了一种方法来 大幅度减少神经网络对存储和计算的需求,同时还不会影响网络的精确度。我们的方法使用三步来剪掉网络中多余的连接。首先,我们将网络训练,使得它能学习到哪些连接是重要的。第二步,我们剪掉那些不重要的连接。 最后,我们重新训练我们的网络来微调那些保存下来的连接。在ImageNet数据集上,我们的方法能将AlexNet的参数数量减少49倍,从61 million 减少到 6.7 million,而且还没有精度的损失。同样的实验用在VGG-16上,参数减少了13倍, 从138 million 较少到了 10.3 million,同样没有损失精度。
Introduction
在计算机视觉,语音识别,自然语言处理中,神经网络已经无处不在。将卷积神经网络应用到计算机视觉中,已经发展了很长时间了。在1998年Lecun等人设计了一个用来识别手写字的网络模型LeNet-5,该模型的参数少于1M, 2012年的时候 Krizhevsky 设计了一个网络模型,赢得了当年的 ImageNet 数据集分类任务的比赛,该模型的参数只有60M,等。
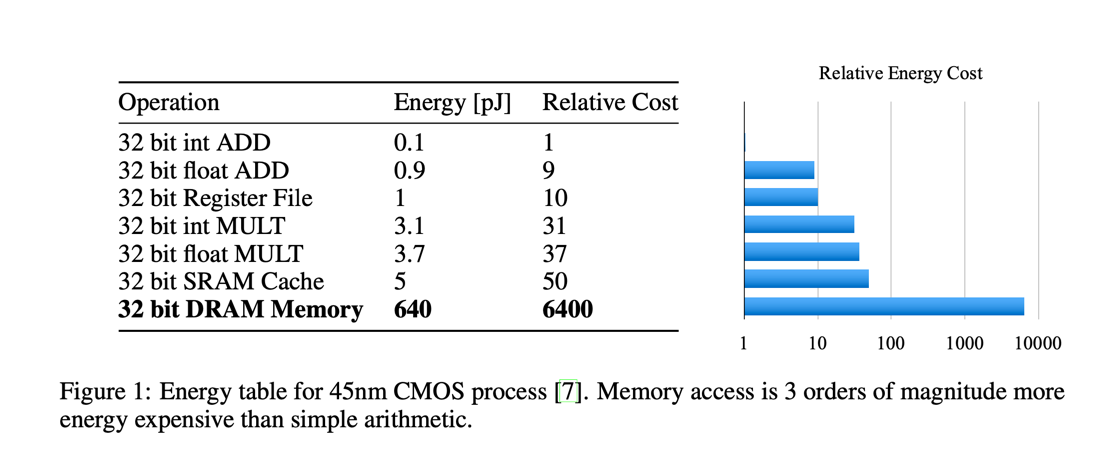
虽然这些大规模的神经网络很强大,但是他们需要相当大的保存,缓存,和计算资源。对于嵌入式的手机而言,这些必须的资源是无法满足的。图1显示了在 45nm CMOS 处理器上的这些基本的算法在
耗能和存储上的消耗。从这些数据中我们可以看到,每一层上的能量的消耗主要在内存的访问上,范围从32 bits的 on-chip SRAM中耗能5pJ到64 bits的off-chip DRAM中耗能640pJ。
大型的网络并不适合在 on-chip 上存储,因此需要更昂贵的 DRAM 来存储。运行连接数有1 billion的一个网络,例如,在20Hz的频率下,只是对于 DRAM 就需要 (20Hz)(1G)(640pJ) = 12.8W
的能耗,已经超出了普通手机的能量范围。我们对网络进行剪枝的目的就是为了减少运行大规模网络所需要的能量消耗,可以使他们能实时的运行在手机上。通过剪枝后的模型,使得整合了DNN的手机程序依然能够方便的存储和转换到手机上。
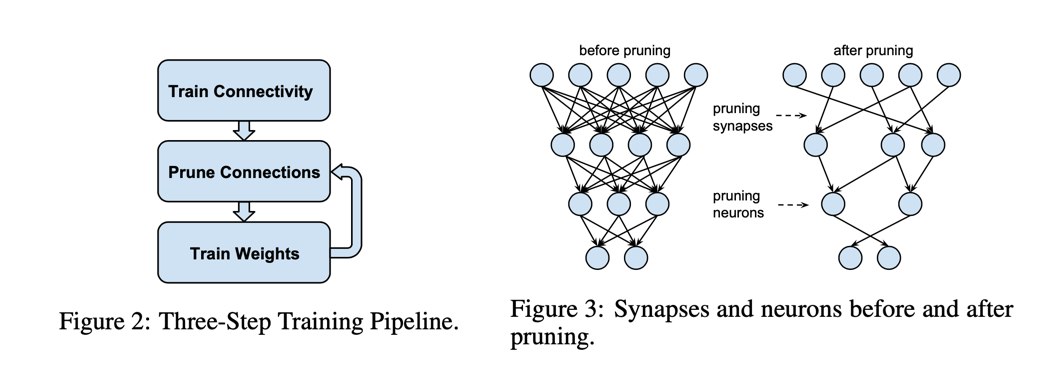
为了达到这个目标,我们提出了一个手动给网络连接剪枝同时还保持原始精确度的方法。在初次阶段的训练之后,我们移除掉网络连接中所有权重小于指定阈值的连接。这个剪枝操作将密集的全连接层转换为稀疏的层。 第一阶段训练的网络拓扑 - 训练哪些连接是重要的,移除掉那些不重要的连接。然后我们重新训练稀疏网络,从而保留下来的网络,能够补偿那些被移走掉的网络。在剪枝和重新训练阶段,可能会重复进行,从而进一步 减少网络的复杂度。在效果方面,该训练过程训练权重以外还训练连接,这与哺乳动物的大脑很像。在儿童的前几个月大脑发育突触,然后就来将很少使用的连接慢慢的剪掉,最终形成了成人的价值观。
Related Work
神经网络通常都是参数过剩的,对于深度学习模型更是这样。这就导致了运算和存储上的浪费。以下有几种方法来移除参数过剩:Vanhoucke 等人使用 8-bit 的固定点的激活函数来实现。Denton等人开发了一种 线性结构的网络模型,来发现参数的合适的低置估计,并保持与原始模型的误差在1%以内。Gong等人也提出了一种相同精度误差的方法,该方法通过向量量化来压缩深度转换。这些近似和量化的方法 与网络剪枝都不一样,并且他们还可以组合起来使用,从而达到更好的效果。
还有一些方法尝试通过使用全局平均池化操作来代替全连接层从而达到降低网络参数的作用。采用该方法的 Network in Network 和 GoogLenet 网络结构都在多个基准数据集上取得了 state-of-the-art 的效果。 然而在迁移学习中,例如,将 ImageNet 数据集上训练出来的特征,仅仅只是通过微调全连接层,就重新应用到新的任务中,使用该方法就不行了。Szegedy 在他的论文中指出了这个问题,并激励他们在网络的最开始的部分添加一个线性层,使得网络能够进行迁移学习。
网络剪枝能同时减少网络的复杂性和过拟合,在早期人们使用偏置权重延迟的方法来进行剪枝操作。Optimal Brain Damage方法和Optimal Brain Surgeon方法都是基于损失函数的海瑟矩阵来减少连接数从而进行剪枝 操作,并且还建议这种方式的剪枝比类似于权重延迟的基于幅度的剪枝效果要好。但是这种方法的后续操作需要更多的计算资源。
HashedNets 是最近的一项通过使用hash的方法来随机的给权重分组到hash的buckets中,从而减少模型大小的技术。这种方法的结果是在相同的hash的buckets中的所有连接,共享单一的参数值。 这项技术有可能受益与网络剪枝。Shi等人和Weinberger等人指出,稀疏性能减少hash的冲突,从而使得特征的hash操作更加有效率。HashedNets可能可以通过与剪枝一起来达到更好的参数保存。
Learning Connections in Addition to Weights
我们的剪枝方法采用了三个步骤来进行剪枝操作,如图2中展示的那样,一开始的步骤是通过训练一个常规网络来学习网络的连接性。然而更传统的训练不同,我们并不是学习网络权重的最终值,而是学习哪些网络的连接更重要。
第二步就是剪掉那些重要性低的连接,权重中所有的重要性低于指定阈值的连接都会被从网络中删除掉,从而将密集的网络转换成稀疏的网络,就像图3展示的那样。最后就是对剩余的稀疏网络进行重新训练,得到最终的权重的值。
这一步至关重要,如果一个网络剪枝之后,没有重新训练,那么它的精确度就会受到很大的影响。
Regularization
选择一个正确的 Regularization 对剪枝和重新训练都会有影响。使用\(L_1\)正则化会惩罚非0的参数,导致最终中有很多参数在 0 附近。这使得剪枝之后精确度更好,而重新训练之后确不会精确度更好。 然而对于\(L_2\)正则化而言,剩下的连接也没有\(L_2\)正则化好,重新训练之后,精确度也很低。总的来说,\(L_2\)正则化对于剪枝能有最好的结果。
Dropout Ratio Adjustment
Dropout 方法在神经网络中被广泛用于去过拟合,在本文的方法中的重新训练也使用了它。然而,在重新训练的过程中,Dropout的丢失率需要根据模型中通道的容量来做适当的调整。在Dropout方法中,当模型在 训练的时候每一个参数都有一定的概率被丢失。但是在模型用于应用推理的时候,又被加回来。在剪枝操作中,通过剪枝操作,一些参数被永久的删除,以后也不会再被加回来。当参数变得稀疏之后, 分类器将会选择信息量最大的预测器,从而使得预测的误差范围变小,这会减少过拟合的发生。当剪枝操作已经减少了模型的容量之后,重新训练的时候的Dropout丢失率就应该设置得小一些。
假设\(C_i\)表示第\(i\)层网络的连接数,\(C_{io}\)表示原始的网络中的\(C_i\),\(C_{ir}\)表示重新训练之后的网络中的\(C_i\),\(N_i\)表示第\(i\)层网络中的神经元的个数, 因为神经元中有dropout的存在,且从 公式(1) 可以看到\(C_i\)随着\(N_i\)的二次方的变化而变化,于是在参数剪枝之后, dropout的丢失率为如 公式(2) 所示,其中\(D_o\)表示原始的丢失率,\(D_r\)表示重新训练之后的丢失率。
\[C_i = N_i N_{i-1}\] \[D_r = D_o \sqrt{\frac{C_{ir}}{C_{io}}}\]Local Pruning and Parameter Co-adaptation
在重新训练的时候,初使权重最好是使用剪枝之后剩下来的连接中的权重,而不是使用重新初始化的权重。因为在CNN中包含脆弱的共同适应的特征,所以当网络在初始训练的时候,梯度下降就可以找到好的方案,但是在重新初始化一些层,再从新 训练他们的时候,就不会有这个效果。所以当我们重新训练剪枝之后的层的时候,我们必须使用剪枝之后剩余的参数作为训练参数而不是从新初始化参数。
当我们使用剩余的参数当作初始化参数后在重新开始训练剪枝之后的层时候,我们只需要很少的运算,因为我们的反向传播不需要到整个网络中。而且,当神经网络很深的时候,更容易出现梯度爆炸的问题, 这使得剪枝之后出现的问题很难修复。为了解决这个问题,我们的做法是在对全连接层剪枝之后固定住卷积层,只是重新训练全连接层,对卷积层也一样。
Iterative Pruning
学习优质的连接是一个重复迭代的过程。剪枝之后再重新训练算是一个迭代。多次迭代之后我们就可以找到最小的连接数,迭代剪枝相对于单次剪枝在AlexNet上能提升剪枝率5到9倍。每一次的迭代都是通过贪婪算法获得最好的连接。 我们也实验过使用基于参数绝对值的概率的方法来进行参数剪枝,但是最后的效果很差。
Pruning Neurons
在对连接进行剪枝之后,输入为0的连接或者输出为0的连接的神经元,可能就会被安全的剪掉。这个剪切或者会通过一个剪掉的神经元从而进一步移除掉整个连接。在重新训练环节,会自动的使那些被剪掉的神经元拥有为0的输入连接和为0的输出 连接。这时由于梯度下降和和正则化导致的。一个拥有为0的输入(或者为0的输出)的神经元,是不会对最终的损失值有贡献的,从而使得梯度在输入连接或者输出连接的地方为0。只有正则项会导致 权重为0,所以被剪掉的神经元在重新训练的时候会被自动的移除掉。
后续 2022-03-22
上面的方法是设置一个阈值,然后将网络的参数中,大于阈值的参数裁剪掉,从而实现压缩网络。下面这篇文章的主要想法是通过计算参数的重要性来判断是否需要将该参数裁剪掉。
PRUNING CONVOLUTIONAL NEURAL NETWORKS FOR RESOURCE EFFICIENT INFERENCE 首先介绍了它剪枝的流程,流程如下,
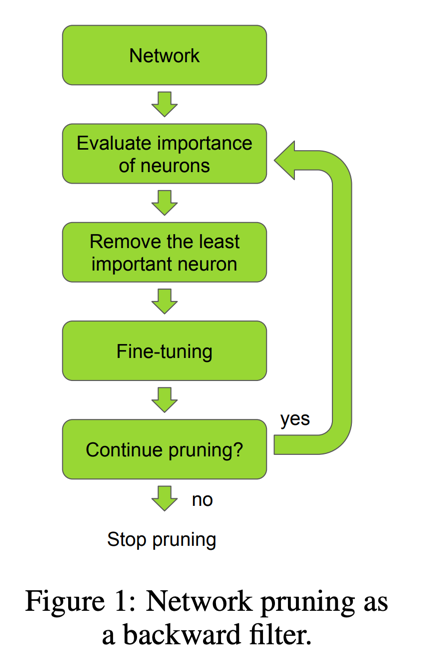 其实与其他的剪枝流程一样,
只是判断是否需要将某个参数剪掉的依据不一样,本文使用的是计算参数的重要性,然后就介绍了几种不同的方法来计算参数的重要性,分别是:
其实与其他的剪枝流程一样,
只是判断是否需要将某个参数剪掉的依据不一样,本文使用的是计算参数的重要性,然后就介绍了几种不同的方法来计算参数的重要性,分别是:
1 ORACLE PRUNIN
| 这个方法是直接比较选择不同的参数,计算它们最终对损失的影响,从而来判断哪些参数更加重要。其中有两个不同的方法,1)是:oracle-los , 直接计算$$C(D | W^\prime) - C(D | W)\(, 2)是: oracle-abs ,直接计算\)|C(D | W^\prime) - C(D | W)|$$ |
2 Minimum weight
| 这个方法是直接计算卷积核的范数,如二范数,$$\Theta(w) = \frac{1}{ | w | }\sum_i\omega_i^2\(,其中\) | w | $$指的是权重矢量化之后的维度。 |
3 Activatio
这个方法指的是在权重经过了激活函数之后,再来计算它的重要性,计算重要性的方法和方法1相同。
4 Mutual information
| 这个方法指的是计算权重对相同的输入和输出他们信息熵的增益,计算方法为:$$IG(y | x) = H(x) + H(y) - H(x,y)\(,其中\)H(x)$$指的是x的熵。 |
5 Taylor expansion
这个方法首先假定我们已经有一个剪枝过后的权重参数\(W^{\prime}\),这个时候我们计算他与原来的参数W对损失的变化,也就是\(\nabla C(h_i)|C(D|w^{\prime}) - C(D|w)|\),
其中\(h_i\)指的是每一层输出。对于每一层的输出,有\(\nabla C(h_i)|C(D , h_i=0) - C(D , h_i)|\),即计算每一层剪枝之前和之后损失的变化。我们利用泰勒公式:
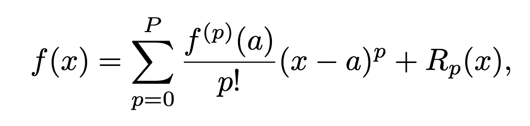 就可以得到:
就可以得到:
 通常\(R_1(h_i = 0)\)可以省略
通常\(R_1(h_i = 0)\)可以省略
最终我们就可以得到在剪枝前后在\(h_i\)处的变化。
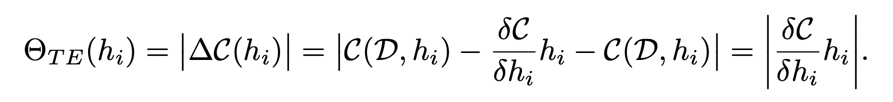
这样我们就可以简单的从反向传播中来就算每一层参数的重要性。
本文由 louis 创作,采用 知识共享署名4.0 国际许可协议进行许可
github 地址 https://github.com/7568/7568.github.io
最后编辑时间为:2022-10-28