简介
Deep Learning with Limited Numerical Precision 是 IBM T. J. Watson Research Center 发表的一篇关于网络如何提升神经网络训练速度的论文。
Abstract
大规模的神经网络常常受限于可用的计算资源。我们在神经网络训练的时候,研究它的数据表示和计算在低精度时候的效果。在低精度固定点的计算环境中,我们观察到舍入策略在训练中对于决定网络的 走向起到了关键作用。我们的结果显示深度网络能够在使用随机舍入的时候,仅仅使用16字节的宽度的固定点来进行数字表示,也能很好的进行训练。
Introduction
在很大程度上,深度学习技术的成功取决于底层硬件平台的快速执行能力,这些有监督的复杂网络使用大量的带标签数据。这些能力能够让我们快速的评估不同网络的结构, 和通过空间搜索来得到模型的参数。所以最近出现的人们感兴趣于的部署在大规模的对于训练神经网络而专门设计的大规模计算架构。例如CPU并行和GPU并行。
于此同时, 有一些研究指出神经网络的结构和学习算法天生对错误具有容忍性,于是使得他们与传统的那些工作不一样,他们需要高的动态范围的计算精度和数据表示。很高兴在之前的研究中 有人指出对于错误率的估计的统计分析中得出,在学习中使用高精度的计算不是必要的。而且,也有研究指出在训练的时候添加噪声能提高训练的准确度。除了部署使用异步版本的随机 梯度下降来减少网络的拥堵之外,当前的 SOTA 的大规模深度神经网络系统都没有充分的重视他们工作中的对错误的容忍性。这些系统通过整合为常规目的设计的硬件,而这些 硬件是为了迎合传统的工作的。这些往往会导致不必要的资源的消耗。
在本文中我们认为是否有可能使用算法层面上多错误的容忍性来释放底层硬件的限制。从而得到一个硬件软件互补的一个系统,从而能够显著的提升模型过的性能和资源利用率。 当我们使用低级的硬件组来执行估计,那些非决定性的计算,和这些由硬件生成的错误暴露到计算栈的算法层面,可能对开发该系统至关重要。而且低级的硬件中的 改变需要介绍到那些服务于程序模型的行为中来,以至于这些好处能够在应用层面被轻易的吸收,而不会明显的降低软件再开发的开销。
为了达到这种交叉层的联合设计,我们第一步要探究的是对神经网络使用低精度的固定点的算法,而在这种使用低精度的固定点的算法的时候,我们使用一个经过特别设计的精度舍弃方法。 使用固定点算法的动机有两个,第一,通常使用固定点单元会比浮点引擎的计算更加节约资源,而且也更快,而且硬件模型也更小,使得可以为其他的硬件腾出更多的地方。 第二,低精度的数据表示能减少存储空间,从而使得对于给定的内存,能够处理更大的模型。总的来说能大大提升数据层面的并行。
我们研究的关键就是神经网络能够使用低精度的固定点算法来进行训练,其中一个前提是进行固定点操作的时候使用随机精度舍去算法。我们将该方法在多个数据集上进行测试,都取得了不错的效果。
Related Work
在实现神经网络的硬件中,数据表示和计算单元的精度在设计选择中起到了决定性作用。不意外的是,一个好的文章会聚焦于量化这种选择对网络性能的影响,但是现在大量的研究都聚焦于 网络前向环节的实现,假设网络是通过高精度计算而离线训练而来的。而且还有一些之前的研究聚焦于数据表示。之前有研究表明在大多数情况下,使用8 - 16 bit的对于反向传播是大大够用的。 还有研究标明,在网络的权重更新的时候,使用随机精度舍去会进一步减少基于梯度的技术的学习算法对精确度的要求。虽然之前对于神经网络的限制精度训练的研究取得了不错的效果, 但是我们通常认为神经网络通常的限制在经典的多层感知中的单个隐藏层或者是几个隐藏单元。而现在的SOTA的网络模型都超过了百万的参数,所以我们需要重新来评估计算精度受限制的神经网络的影响。
当前有一篇文章提出一个对于神经网络的硬件加速器,该加速器使用固定点计算单元,但是他们发现必须使用32-bit的固定点表示,在训练神经网络的时候才能收敛。与之相反的是,我们的研究标明, 其实在网络的训练中,在固定点计算中,使用随机精度舍去是可以仅仅使用16-bit的固定点的。据我们了解到,我们第一个提出在使用低精度固定点算法训练神经网络训练的时候使用随机精度舍弃。
Limited Precision Arithmetic
神经网络的训练,标准的实现是在反向传播的时候使用 32-bit 的浮点型数据来表示真实数据。我们取而代之的是用固定点数来表示:[QI.QF],其中 QI 和 QF 分别表示一个数的整数部分和小数部分。 一个数的整数部分的长度 (IL) 加上小数部分的长度 (FL) ,就得到了用来表示一个数的位数。IL + FL 表示一个数字的长度WL。在本文中我们使用 <IL, FL>来表示固定点。IL (FL) 分别表示固定点中整数的长度和小数的长度。 我们还用 \(\epsilon\) 来表示给定的固定点格式的数据的最小正数。因此 <IL, FL> 固定点类型限制的精度为 FL 个 bit。能表达的数据的范围是 \([-2^{IL - 1} , 2^{IL - 1} -2^{-FL} ]\) , 并定义\(\epsilon\) = \(2^{-FL}\)
Rounding Modes
我们使用精度舍弃模型将一个高精度的数字用低精度的形式来表达。给定一个数我们要将它转换成 <IL, FL> 格式的固定点类型,其中我们定义 \(\lfloor x \rfloor\) 为这个数的最大整数, 再加上 \(\epsilon (=2^{-FL})\) ,得到的结果会小于或者等于x。我们考虑了一下两种精度舍弃的方案: . 就近舍弃原则 \(Round(x,<IL, FL>) =\begin{cases} \lfloor x \rfloor & \quad \text{if } \lfloor x \rfloor \leq x \leq \lfloor x \rfloor + \frac{\epsilon}{2} \\ \lfloor x \rfloor +\epsilon & \quad \text{if } \lfloor x \rfloor + \frac{\epsilon}{2} < x \leq \lfloor x \rfloor + \epsilon \end{cases}\) . 随机舍弃原则 \(Round(x,<IL, FL>) =\begin{cases} \lfloor x \rfloor & \quad \text{w.p. } 1-\frac{x-\lfloor x \rfloor}{\epsilon} \\ \lfloor x \rfloor +\epsilon & \quad \text{w.p. } \frac{x-\lfloor x \rfloor}{\epsilon} \end{cases}\)
相比较于就近舍弃原则,随机舍弃原则是一个无偏的方案,而且期望也是0。
所以我们如果想使用<IL, FL> 的方式来表示一个数x,就可以表示成如下: \(Convert(x,<IL, FL>) = \begin{cases} -2^{IL-1} & \quad \text{if } x \leq -2^{IL-1} \\ 2^{IL-1} - 2^{-FL} & \quad \text{if } x \geq 2^{IL-1} - 2^{-FL} \\ Round(x,<IL, FL>) \quad \text{otherwise } \end{cases}\)
Multiply and accumulate (MACC) operation
对于两个d维的向量\mathbf{a} , \mathbf{b},我们要把他们表示成固定点格式<IL, FL>, 我们定义\(c_0 = a . b\) 位 a,b的内积。我们将\(c_0\)也表示成 \(<\tilde{IL} , \tilde{IF}>\)的格式。我们将计算\(c_0\)分成两部分:
-
计算\(z = \sum_{i=1}^{d}{a_i}{b_i}\)
其中 \(a_i\)和\(b_i\)相乘后得到<2 ∗ IL, 2 ∗ FL>格式的固定点数据。\(z\)可以想象成一个临时的固定点注册器,有足够的宽度来防止溢出和避免丢失精度。 \(z\)在最坏情况下的长度为\(log_2{d} + 2WL\),而且最坏的情况发生的概率极低。只有当\(a_i\)和\(b_i\)都同时超出了<IL,FL>的范围的时候才会发生。
2 转换 \(c_0=Convert(z , <\tilde{IL} , \tilde{IF}>)\)
其实这一步就是将 \(z\) 转成<\tilde{IL} , \tilde{IF}>的格式,进行精度舍弃。
采用这两步有几个好处,首先它很好的模仿了硬件实现向量内积的操作。第二在所有的加法操作之后才调用精度舍弃操作,能大大减少硬件的过载。最后使用这种方法能在CPU 或者GPU上很好的模拟固定点的计算。
后续
基于上面的论文,sharan 等人提出了另一项研究结果 MIXED PRECISION TRAINING 。将固定点模型扩展到了更大的模型上,而且实用性更强。
不过与上面论文中的方法不同的是MIXED PRECISION TRAINING中全程使用固定点算法来降低精度,包括网络训练过程中的前向和反向过程。 而且没有参数需要调整,最后几乎不损失神经网络的预测性能。
接下来我们讲述一下MIXED PRECISION TRAINING的实现细节。
IMPLEMENTATION
我们介绍一种用FP16来训练神经网络的技术,与使用FP32训练的网络有相同的精度。我们的整个操作成员包括:单精度的主要权重,更新操作,损失缩放,将FP16操作后的结果 加到FP32中。
FP32 MASTER COPY OF WEIGHTS
在混合精度的训练中,权重,激活函数和梯度都存储成 FP16 的格式,为了能够达到 FP32 的精度,我们在每一步梯度优化的操作中拷贝一个 FP32 格式的主分支权重,并维护和更新它。 在每一次叠戴的前向和反向中,我们将主权重拷贝成 FP16 精度,对于 FP32 精度网络的训练,我们减少了一半的存储和带宽。
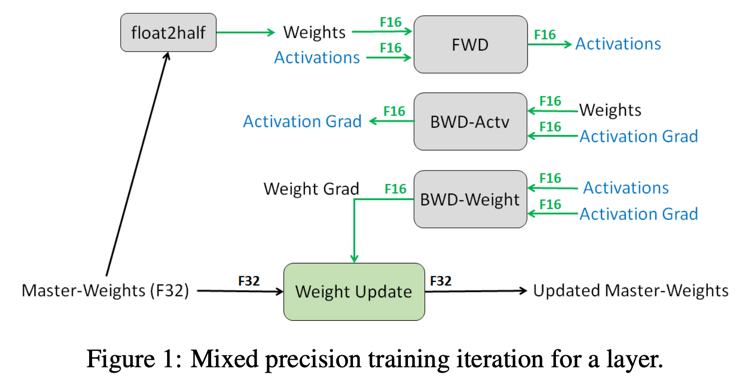
虽然对FP32的主权重不具有普适性,有两种原因使得很多网络都需要它。一个解释是在梯度更新的时候,如果使用FP16,会导致每次跟新太小,在FP16中,所有小于\(2_{-24}\)的数据都会变成0, 在优化的过程中。那些小的梯度乘以学习率,就会变成0,从而对模型精度造成不厉的影响。在模型参数更新的时候使用一个单精度拷贝就可以解决这个问题。
另一个解释是每次更新太大,这这个情况中,使用FP16,如果梯度乘以学习率太大,导致FP16不能表达这个数,可能就会使得结果为0。
虽然维护一个多加的权重会导致存储需求增大一倍,但是相对于整个训练时候所需的存储来说是很小的。因为对于神经网络的训练而言,存储消耗主要集中在激活函数的操作中, 因为在网络的训练过程中,每一层的激活操作都会被保存下来,便于反向的时候重复利用。在单精度中,激活函数的存储需求减半,使得整个网络对存储的需求几乎减半。
LOSS SCALING
FP16所能表达的数据有限,而在网络的实际训练中,大部分的激活函数的梯度值都很小,小于FP16所能表达的范围。我们使用损失缩放的方法从而避免这种现象的发生。
在进行缩放的时候,我们需要选择缩放因子。对于缩放因子的选择,最简单的方法就是选择一个固定的缩放因子,只要它不会导致最终更新的时候更新值大于FP16所能表达的最大值。
ARITHMETIC PRECISION
总的来说神经网络中的算法分成3类,分别是向量点乘,降维,逐点操作。在减少精度的算法中需要对这三个分别进行处理。为了保证模型的精度,我们发现使用FP6格式表示的向量在 点乘的时候需要先转换FP32格式,然后再在存入内存之前转换成FP16格式。
对于大规模的降维(比如将向量中的所有元素相加)就必须使用FP32的格式。这些操作往往都是在批量归一化层和softmax层。对于所有层的数据,对内存的读和写的操作都是使用的FP16格式, 只是在进行计算的时候才使用FP32的格式。这样并不会降低整个训练的过程,
对于逐点操作,例如非线性变换,或者矩阵逐点相乘,是受内存的带宽的限制。由于算法的精度不会影响这些操作的速度,FP16和FP32都可以使用。
本文由 louis 创作,采用 知识共享署名4.0 国际许可协议进行许可
github 地址 https://github.com/7568/7568.github.io
最后编辑时间为:2022-10-28