剪枝策略包括求二阶导数,求二阶偏导数,指定阈值,指定剪切比例,但是又有论文发现,其实重要的不是将哪些值剪掉,而是那些值所在的位置,也就是说我们剪枝之后 剩下的参数其实可以不要,重新初始化一个参数,再重新训练,也是可以得到一样的结果的。如果我们只是为了得到裁剪的比例,然后我们从每一层中,随机的裁剪, 重新初始化参数,再训练,是不是也能有同样的效果呢?如是比例是重要的,那么我们是不是可以设计一个得到比例的方式?
(structured pruning) Anwar et al. (2015) describe structured pruning in convolutional layers at the level of feature maps and kernels, as well as strided sparsity to prune with regularity within kernels.
(unstructured pruning) Han et al. (2015) introduce a simpler approach by fine-tuning with a strong \(\ell_2\) regularization term and dropping parameters with values below a predefined threshold. Such unstructured pruning is very effective for network compression, and this approach demonstrates good performance for intra-kernel pruning. But compression may not translate directly to faster inference since modern hardware exploits regularities in computation for high throughput. So specialized hardware may be needed for efficient inference of a network with intra-kernel sparsity (Han et al., 2016).This approach also requires long fine-tuning times that may exceed the original network training by a factor of 3 or larger.
Group sparsity based regularization of network parameters was proposed to penalize unimportant parameters (Wen et al., 2016; Zhou et al., 2016; Alvarez & Salzmann, 2016; Lebedev & Lempitsky, 2016). Regularization-based pruning techniques require per layer sensitivity analysis which adds extra computations
combining parameters with correlated weights (Srinivas & Babu, 2015), reducing precision (Gupta et al., 2015; Rastegari et al., 2016) or tensor decomposition (Kim et al., 2015).
(https://arxiv.org/pdf/1611.06440.pdf) propose a new scheme for iteratively pruning deep convolutional neural networks ,and in its iterative procedure they only remove unimportant parameters leaving others untouched
A Survey of Model Compression and Acceleration for Deep Neural Networks 中指出深度压缩总共可以分成4类,分别是 (1)参数剪枝和量化 (parameter pruning and quantization) , (2)低秩分解(low-rank factorization),(3)转换或者压缩卷积核(transferred/compact convolutional filters) , (4)知识蒸馏(knowledge distillation. )
参数剪枝:设计一个策略(如设置一个阈值,或者通过一个方法来计算参数的重要性),让网络中的连接数变少,即将原来训练好的参数,一部分变成0,这样网络参数就变得稀疏,从而使用稀疏矩阵的方法来保存参数。
参数量化:(1)将原来高精度的网络参数用低精度的字节长度来表示,例如原来是32位bit,现在换成16位,就能节约参数所需的存储空间,甚至有人直接使用2位的bit来表示参数。 (2)在训练的时候将参数矩阵设计成方便存储的特殊结构,从而实现减少参数所需的存储空间。例如设置一个斜对角线矩阵结构作为参数矩阵的结构。
低秩分解:使用矩阵分解的思想将已经训练好了的参数进行分解,如svd分解。这样就可以使用一个参数较少的矩阵来代替原来的矩阵。
转换或者压缩卷积核:这种方法是一种常见的方法,例如利用卷积操作代替全连接,或者使用较小的卷积核来代替较大的卷积核,或者maxpooling,或者使用别的卷积方法。
知识蒸馏:首先我们使用常规方法获得一个模型,称为老师模型,这个模型的训练数据是标记好了的数据,然后我们再设计一个小的模型,称为学生模型,使用未标记的数据来进行训练。对于一个未标记的数据,分别经过老师模型和学生模型,使用老师模型来对数据进行标记,从而得到损失,进行训练。
idea : 在Do Deep Nets Really Need to be Deep?这篇论文中说使用一个训练好了的老师模型来训练学生模型,得到的结果最终学生模型比老师模型效果要好。但是这篇 论文中的学生模型使用的是更宽的模型。我们可以使用Learning both Weights and Connections for Efficient Neural Networks这篇论文里面的方法来获得学生模型,即将剪枝之后的模型当作学生模型。在原论文中剪枝之后的模型通常 精度与原始模型一样,如果我们在retrain剪枝模型的时候,使用一个老师模型来训练,就可能获得一个更好的效果。
Recent Advances in Efficient Computation of Deep Convolutional Neural Networks
这篇论文也是一篇关于深度网络压缩的综述性论文。里面分别介绍了6种网络压缩和加速的类型,分别是:网络剪枝(network pruning) , 低秩近似( low-rank approximation),网络量化(network
quantization),老师学生网络(teacher-student networks),紧凑型网络设计(compact network design)和硬件加速器(Hardware Accelerator)。
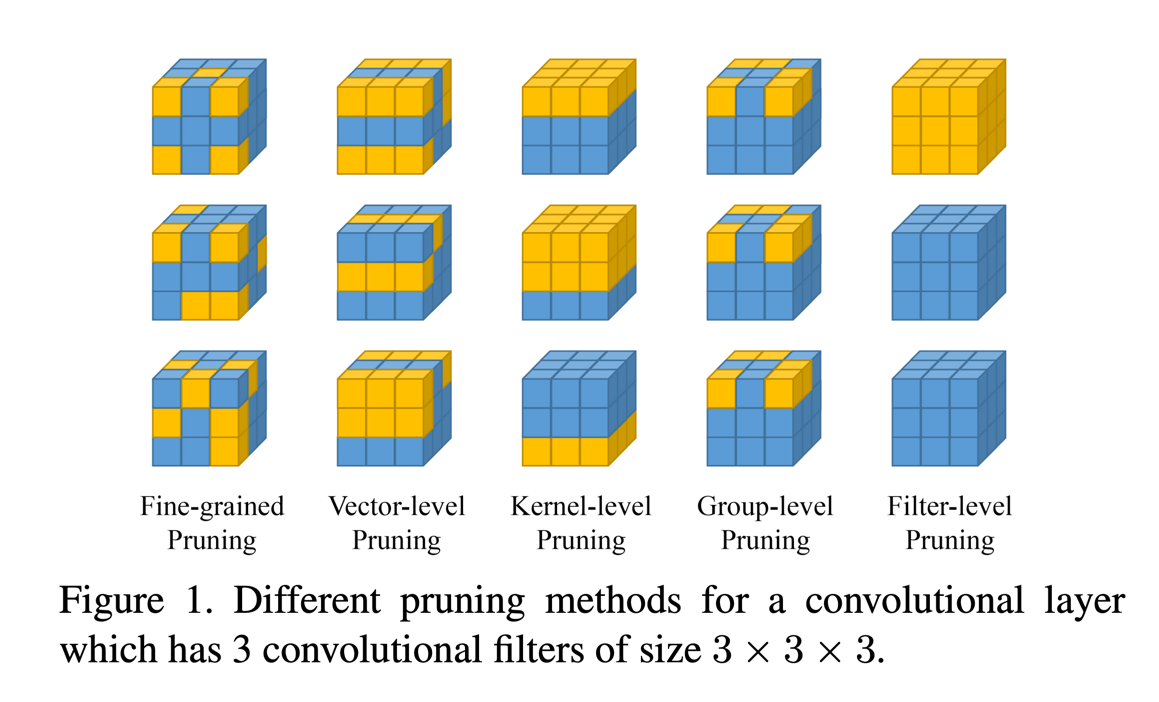
其中,在网络剪枝方面,根据剪枝的粒度不同,细分了5类来分别描述,分别是: 细粒度剪枝( fine-grained pruning) , 向量级别的剪枝(vector-level pruning),核级别的剪枝(kernel-level
pruning),祖级别的剪枝(group-level pruning ),过滤器级别的剪枝( filter-level pruning)。
细粒度剪枝( fine-grained pruning) 指的是以一种非结构化的方式来剪枝,选定一个判别方式,然后通过这个判别方式来判断某个参数是否要剪掉。
向量级别的剪枝(vector-level pruning)这个方法相对于 fine-grained pruning 来说,更加结构化一些,他是通过设计一个判别方法来判断卷积核中的某一个向量的参数是否需要被剪枝掉。
核级别的剪枝(kernel-level pruning)这个方法跟 vector-level pruning 类似,只是这个方法剪枝的是矩阵。
组级别的剪枝(group-level pruning )这个方法指的是在不同的卷积核上,设计一个判别方式,然后大家剪同样部分的枝。
过滤器级别的剪枝( filter-level pruning)这个方法指的是直接剪切掉某一个卷积核,这个方法的颗粒度最大
下图是不同的颗粒度剪枝方法的图示:
低秩近似( low-rank approximation )
这个方法分成三类,分别是 two-component decomposition, three-component decomposition and four-component decomposition。two-component
decomposition通常是SVD分解,然后three-component decomposition和four-component decomposition是将SVD分解之后的矩阵再进行分解成更小数量更多的矩阵。
网络量化( Network Quantization )
网络量化分成两种,一种是标量和矢量的量化,另一种权重的固定点量化。标量的方法指的是使用一个值来代替一组值,从而使得网络参数变小,例如使用 Kmeans 来进行分组,然后用中心值来代替一组值。
矢量的方法指的是我们最终使用一个或者若干个向量来代替一个矩阵,从而减少矩阵存储所用的空间。权重的固定点量化指的是通常我们的权重都是使用的32bit的数据长度来保存的,但是有研究认为其实是不需要这么大的数据精度的,于是就有人提出了使用16bit,8bit,3bit,2bit的方式来训练和保存权重参数。
权重的固定点量化又可以分成两类,一类是直接对权重进行量化,一类是对激活函数的运算进行量化。也可以两个一起使用。
老师学生网络(Teacher-student Network)
老师学生网络说的是我们可以使用一个大的已经训练好了的老师网络来训练一个小的学生网络,而且通常学生网络表现好于老师网络,具体的实现细节就是对于一个味标记的数据,先用老师网络得到预测结果,然后用学生网络来进行预测,并通过该结果与老师网络的结果计算损失,从而对学生网络进行优化。
紧凑型网络设计(Compact Network Design)
这个方法指的是我们使用小的卷积核来代替大的卷积核,从而来减少网络的参数量。例如使用1x1的卷积核。
硬件加速器(Hardware Accelerator)
硬件加速器分成两类,一类是加快运算速度,一类是减少运算所需的能源消耗。
COMPRESSING DEEP CONVOLUTIONAL NETWORKS USING VECTOR QUANTIZATION
这篇文章主要介绍了4种神经网络参数量化的方法,分别是:BINARIZATION,SCALAR QUANTIZATION USING kMEANS, PRODUCT QUANTIZATION, RESIDUAL
QUANTIZATION。
其中 BINARIZATION 指的是将矩阵中的数据全部变成1和-1,大于0的变成1,小于0的变成-1。
SCALAR QUANTIZATION USING kMEANS 指的是使用 kmeans 方法,将矩阵分成k类,然后用中心值来代替一组值。
PRODUCT QUANTIZATION
指的是对于一个矩阵,首先我们选择某一种方式,按照列分成s个小的矩阵,然后分别对每个小的矩阵按照行进行Kmeans聚类,分成k类,这样我们就可以使用一个向量来表示一个小矩阵,从而就使用s个向量来表示一个矩阵。
RESIDUAL QUANTIZATION
指的是首先使用kmeans将矩阵进行分类,分成k个向量组,得到k个中心点的向量,然后我们计算每个剩余向量与中心向量的残差,从新得到k个分组。也就是说我们使用kmean来确定k个中心,然后利用计算残差来得到每一组的元素。
Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better 本篇论文主要讲述的是如何让你的网络更小,更快,效果更好。
摘要:随着深度学习的快速发展,机器学习领域取得了很多重大突破,但是神经网络模型的参数越来越大,于是我们就需要更多的资源来训练。从而硬件规格相比于神经网络模型的性能就受到了更多的关注。 本文中我们从5个关键方面来研究网络模型的效率。我们还为神经网络的工作者在优化训练和部署上给出了一些基于经验的指导。本文涉及的地方包括算和硬件。希望对大家有帮助。
1 介绍
深度神经网络在图像识别和自然语言处理上取得了很多的成就,诞生了一大批巧妙的网络模型。比如在图像处理上AlexNet,VGGNet, Inception , ResNet。在
自然语言上基于Transformer的BERT , GPT-3。它们通常都有个特点就是性能越好,网络参数越多。而且对于单一的网络,增加网络的参数,往往也能提升网络的性能。
于是作为一个深度学习的工作者就会在训练和部署网络的时候面临以下几点:(1) 服务器端的可持续扩展性,在我们训练和部署一个很大的网络的时候,我们通常需要扩展我们的服务器的性能,此时我们就需要考虑我们的服务器是否能经得起一直扩张。
(2) 对指定设备的可用性,通常一个大的网络,我们在服务器上训练之后,如果此时我们需要部署到智能设备上,此时我们就会受限与智能设备的可用资源的有效性。
(3) 数据隐私和敏感,我们训练一个大的网络通常需要一个很大的数据集,如果此时能设计一个网络能在少量的数据集上得到很好的效果,那么这个网络就会比大的网络更有有效性。
(4) 新的应用,我们之前训练好的现成网络,可能会对一些有新限制的新应用不适用。
(5) 模型爆炸,有时一个单一的网络不能对多个任务很好的工作,我们需要训练大量的重复结构的网络来处理不同的任务,随着任务越来越多,可能就会耗尽计算资源。
1.1 网络的有效性:
通常有效性分为训练的有效性和推理有效性。推理有效性指的是我们在部署网络之后,对于新的输入进行推理的有效性,很多时候我们训练的机器与部署的机器并不是同一个机器,他们 的性能也是不一样的。
2 一个好的模型
对于一个网络,我们提出从以下5个方面来优化它。分别是:
(1)压缩技术,常用的方法是对网络进行量化,降低数据表示的精度,不是模型的精度。例如使用8精制的数来代替常用的32精制的数。
(2)学习技巧,通过一些学习策略,让网络能精度好,而且参数少。例如模型蒸馏。
(3)自动化,通过一些自动化的方法获得更好的网络结构,超参数等。
(4)有效的网络方式,例如使用卷积,RNN,或者使用注意力机制等。
(5)基础实现工具,例如pytorch,tensorflow等。
3 好的模型具体实现
3.1 网络压缩
3.1.1 剪枝 在网络剪枝中,一些经典的工作有Optimal Brain Damage (OBD) by LeCun et al. 和 Optimal Brain Surgeon paper (OBD) by Hassibi et al. 。他们的做法是(1)训练一个大的网络,让它达到一个合理的效果,然后我们通过不同的方法来计算每个参数的显著性,将那些不显著的参数设置为0 。从而使得我们的网络参数由原来的密集变成稀疏,稀疏的网络参数往往可以通过量化的方式来进行压缩。计算参数的显著性往往有计算二阶导数,或者直接指定一个阈值,或者计算偏导数。
剪枝策略:
(1)使用显著性,这个方法最常用。
(2)结构性和非结构性,通常非结构性剪枝指的是参数矩阵或者tensor中,每个参数是否被剪掉是独立的,而结构性指的是我们剪枝的时候可能时候整个行,或者列,或者矩阵全部剪掉,这样被我们剪过之后的网络是规律性的,结构性的。
(3)分配性,我们可以从全部参数的角度来分配哪些参数需要被剪掉和剪多少,也可以从每一层的角度来分配。
(4)规律性,我们可以指定每一轮迭代剪枝的数量,既可以是每次剪一样多,也可以是有规律性的剪枝。或者我们可以指定先少剪,再多剪。或者先多剪,再少剪。
Dynamic Network Surgery for Efficient DNNs 这篇论文介绍了一种给网络剪枝的方法,相较于之前别人的通过计算网络参数的重要性来判断是否需要将改参数剪掉,如果剪掉就将其设置成0,而本文是另外新建一个全为1的矩阵T, 长宽和网络的参数一样,再将原来的参数矩阵乘以T(不是矩阵相乘,而是对应位置相乘),然后通过计算每个网络参数的重要性,来判断是否将T对应的位置变成0,如果变成0,就表示该位置的参数被剪掉了。 这个方法与 Song 方法的不同是这个方法在参数被变成0之后,以后还有机会再恢复回来,因为作者认为一开始的剪 枝是有可能错误的将重要的参数剪掉,而本方法就算之前被剪掉,后面还是有可能恢复的。本文也是通过判断重要性是否大于某个阈值的方法来判断是否剪枝,比不过 本文使用了两个阈值。
idea:上面的文章只讨论了非结构的剪枝,我们可以将它应用到结构化剪枝上。 在2018年的时候,Soft Filter Pruning for Accelerating Deep Convolutional Neural Networks 已经对此进行了研究,不过它研究的是filter级别的剪枝,我们可以换一个级别。
RETHINKING THE VALUE OF NETWORK PRUNING 我们测试了所有的主流的剪枝算法,发现利用原来的参数微调一个网络,最终得到的效果并不会好于我们随机初始化剪枝之后的网络,进行训练的效果。于是我们得到以下3个 结论:(1)对于获得一个精简有效的网络,提前训练一个很大参数的网络不是必须的。(2)对一个大的模型学习参数的重要性对最终剪枝之后的小模型基本上没有用。 (3)剪枝之后网络结构本身,而不是模型参数的重要性,对于一个剪枝之后的网络更重要。基于此,我们建议在对网络剪枝的时候,我们应该将重心放在寻找剪枝之后的 结构上。
idea:本文说在剪枝的时候,使用留下来的参数并不会比使用随机初始化的参数效果更好,所以我的想法是我们一开始就不进行训练,而是使用一个大的网络结构, 然后构建一个剪枝比例的策略,这里可以分成结构化剪枝和非结构化剪枝,剪枝之后,直接训练,我们的目的就是通过大量的实验,找出合适的剪枝比例策略,例如我们 设定每个矩阵的剪枝 比例,然后我们比较是规律的剪枝还是随机的剪枝效果更好,或者我们对于网络的所有层,是大家都剪一样的比例,还是前面的层比例大,或 者前面的层比例小,或者每个层都有自己所对应的比例。
1 INTRODUCTION
通常来说我们对网络剪枝流程有两个方面的共同认识:(1)是首先我们需要训练一个大的网络,然后我们设计一个策略来计算参数的重要性,将那些不重要的参数剪掉。 (2)是我们认为剪枝之后,那些保留下来的参数和网络结构对对最终获得精简有效的网络至关重要,所以大家在剪枝之后,通常的做法是在剪枝之后的网络上进行微调, 而不是重新训练。
在本文中,我们展示了上面的两个认识对于结构性的剪枝方法并不是一定正确。(1)首先对于结构性的剪枝方法,提前定义一个目标网络结构,并随机初始化参数, 然后直接训练这个小的模型,依然能取得不差于通过剪枝-微调的方式得到的结果。(2)对于结构性的剪枝方法,使用一个自动搜索的方法来得到一个小模型,然后在这个 小模型上初始化参数,再训练,也能得到一个很好的结果。从这个结果可以给我们的启发是相较于设计一个方法来得到重要的参数,我们设计一个方法来得到模型结构 才是关键。(3)有趣的是,对于非结构性的剪枝方法,我们发现在小数据集上,我们使用剪枝,微调的方法能够获得较好的精确度,但是并不适用于像 imageNet 那样的大数据集。
Note 在某些情况下,如果已经有了一个好的大的模型,我们使用剪枝-微调的方式可能会更加节省时间。我们实验中的结论与其他研究的结论不一致的地方也可能 是由我们选择的超参数,数据增强,或者是评估结果的方法不公平的原因造成的。
2 BACKGROUND
首先,网络压缩很重要,已经有很多的相关研究发表。网络压缩中一个重要的分支是对权重的中的参数分别判断是否应该被剪掉,我们称这种压缩的方法为非结构性压缩, 也有关于这方面的很多研究,但是这种 压缩的方法,会导致最终得到的稀疏矩阵在进行运算的时候不能被加速,原因是这种稀疏矩阵不规律,不过这种方法可以在参 数保存的时候使用特殊的保存方法,使得需要的存储空间小。 与之对应的是结构性压缩,这种方法不再关心权重中的单个参数,而是一排或者几排参数或者一列或者 几列参数,或者参数中的某一个或者几个channel,甚至是层,也可以是排,列,channel,层的组合,总之经过这种方法的剪枝后,权重在运算的时候,就可以通 过硬件来加速,而且存储的时候所需的空间也小。其中针对channel的剪枝最为普遍。
Mittal et al. (2018) 发现随机的channel剪枝也能取得不错的效果,不过该方法也是要fine-tuned。Zhu & Gupta (2018) 发现如果使用一个小的紧凑的模型,并不能达到一个有相同参数 量的大的稀疏矩阵模型的效果。本文的研究发现,剪枝之后的参数不是重要的,而剪枝之后的结构才是重要的。
3 METHODOLOGY
Target Pruned Architectures : 目标网络结构,我们分为两种,一种是手动指定,一种是自动生成。
Datasets, Network Architectures and Pruning Methods
Training Budget
Implementation:(1)如果之前的剪枝方法有公开可用的设置,我们就用公开的设置。(2)如果没有的话,我们就自己来实现它,并且达到与原文有相同的效果。 (3)对于一些方法,他们有公开的设置,但是我们没有使用他们的设置,而是我们自己重新训练。有意思的是我们自己重新训练的结果比原文中的结果要好。我们的 代码全都是使用的Pytorch,训练时使用了常用的超参数和数据增强。
4 EXPERIMENTS
本章中我们对比了(1)结构化剪枝中手动定义剪枝结构的方法。(2)结构化剪枝中自动化得到的结构的方法。(3)非结构化剪枝中基于参数显著性的剪枝方法。
5 NETWORK PRUNING AS ARCHITECTURE SEARCH
本章中我们比较了通过方法获得的模型结构和均匀的剪枝方法的模型,实验证明通过方法获得的模型结构确实比均匀的剪枝方法的模型好一点点,但是并不多。
本文由 louis 创作,采用 知识共享署名4.0 国际许可协议进行许可
github 地址 https://github.com/7568/7568.github.io
最后编辑时间为:2022-10-28