Synthetic Humans for Action Recognition from Unseen Viewpoints
摘要
本文想通过利用合成的数据来提升视频人类动作的识别率。基于此想法,作者设计了一套合成数据的生成方法,生成了一个新的数据集 SURREACT,然后通过在 该数据集上进行训练,再分别在NTU RGB+D 和 UESTC 数据集上做微调,最后取得了目前动作识别最好准确率。NTU RGB+D 和 UESTC 数据集都是室内视频数据 集, 为了检验作者的方法,他们又在野外的视频数据集 Kinetics 上做了one-shot测试,即每一类只选择一个样本进行训练,然后取得了很好的效果。
Introduction:首先作者介绍通常大家都使用卷积神经网络CNN来对视频数据集UFC101进行动作识别训练和预测,但是作者提出卷积神经网络非常依赖于数据集的 大小,通常需要很大的数据集才能有好的效果,然后鉴于此就有很多工作 提出使用合成数据来增加数据量,例如使用光流估计,分割,身体和手势估计。在本文中研 究的是利用合成的数据来进行动作识别。
作者通过观察,发现对于现在流行的所有网络,对于同一个动作,如果训练和测试都使用同一个视角,能得到很好的结果,但是如果训练和测试使用不同的视角,这些 网络的性能就会大幅度减少。例如作者使用一个3D的卷积网络来对 NTU RGB+D 数据集进行训练, 当训练和测试都是正面视角的时候,最终能得到80%多的准确率, 但是如果我们的测试换成90度视角,这个时候准确率就只有40%了。这个结果激发了我们来从一个巧妙的视角研究视频动作识别。
在之前有一些对人体姿势预测进行了研究,并且取得了很好的成绩,通常他们的目的是动作捕获(MoCap),所以这些研究不适合于行为的预测,因为它们没有数据标记。
所以本文就提出了一个新的简单有效的方法来合成带有行为标签的数据。首先我们使用 HMMR 和 VIBE 等方法来动态的从单视角的 RGB 图像中得到 3D 的人, 这些 3D 的人是由一串 SMPL 的人体姿势的参数组成。 然后我们利用render将 SMPL 参数合成不同视角的带标签的训练数据。最后我们使用一个 3D 网络来对我们的数据进行训练,得到了非常好的效果。我们的效果主要有两个方面, 一是对于没见过的视角的行为识别,二是对于 one-shot 数据的训练识别。
相关工作
人类行为识别是一个成熟的研究领域,在 Kong et al 的一篇对其研究的综述论文中有详细的介绍。本文中我们只聚焦于相关工作中的合成数据, 交叉尺度动作识别,和简要的3D人类形态估计。
合成人类数据:在过去有很多研究都使用了合成数据来进行数据增强,但是他们都还没有将合成数据应用到人类行为识别上来,之前的一个重要的合成数据集 SURREAL , 就是视频中人类 shape , pose , 和 motion 的数据集,而不是行为的识别。过去也有一些用姿势合成数据,和点轨迹合成数据来进行不同视角的行为识别, 但是利用合成的RGB图像来训练,来进行动作识别的研究还是一个比较新的领域,De Souza et al是最早的一批人来研究该领域。但是他们方法自动化程度不高。 有一些地方 需要手动处理,而且他们的可扩展性不是很好。
之前有一篇论文(43)他们与我们的工作最相近,他们是利用合成的数据来学习人类姿势模型,然后通过该模型得到行为视频的特征,最后将该特征进行行为预测的分类。 我们与该论文的最大区别就是我们合成的数据是直接用来行为识别,也就是说我们生成的数据是带有行为标签的。
交叉视角的行为识别:NTU RGB+D 是第一个大规模多视角的行为识别数据集。从而使得我们可以开始在该领域使用深度神经网络。最近又有人提出了一个新的数据集 UESTC ,该数据集在实验室中 收集了大量动作的360全视角视频。在之前多视角行为数据集通常都是带有景深的RGB图像,一般大家的做法是通过RGB-D得到一个3D 的人体框架,然后基于该框架来进行多视角的研究, 也就是说他们这些研究在训练过程中使用的输入图像是 RGB-D 格式的或者是通过 RGB-D 得到的3D人体框架。 而我们提出的方法,训练的时候的输入输入的图像只是 RGB 格式的。
将RGB的特征转换成不同视角不像转换3D人体架构那样简单,之前有很多人对此进行了研究,我们与他们的不同是,我们不使用3D人体架构图,而是使用合成的数据 来进行数据增强,而且我们训练的时候并不假设训练的视频存在多视图。
人体3d形态估计:从单张图像中恢复出一个完整的人体体型网格已经有很多的研究,在本文中,我们使用 HMMR 和 VIBE 两种方法分别获得 SMPL 格式的人体参数。
合成带有行为标签的人类数据:首先我们通过 HMMR 或者 VIBE ,将一个视频数据中的人体以3D的形式提取出来,然后我们使用该3D数据来合成不同视角的数 据,最后我们使用一个3D网络来训练该合成的数据。
训练一个3D网络 :对于3D网络,我们使用3D ResNet-50,我们同时还使用了光流信息,我们使用一个 two-stack hourglass architecture 的网络来训练光流信息。通常一个视频段,里面包含的图像非常多,如果我们使用一个完整的clip,那么我们网络需要处理的数据会非常大,导致我们的网络训练起来 非常的慢。所以我们采用从一个视频clip中抽取出16帧图像来合成一个新的clip。在训练的时候我们随机的抽取这16帧图像,我们称这种方法叫非标准抽取,与之对 比是标准抽取,该方法通常更常用,该方法定义一个固定的抽取帧率,然后通过该抽取帧率抽取一段连续的帧。
训练:由于我们的合成数据远远大于真实数据,所以在训练的时候我们为了平衡合成数据与真实数据,每个epoch,我们放入到网络的合成数据和真实数据的总数一样多。
实验
Datasets and evaluation protocols
NTU RGB+D dataset (NTU):该数据集总共包含60个行为,同时使用了3个同步的摄像机,总共有56K的数据,每个视频平均有84帧。对该数据集标准的评价 准则是交叉视角得分和交叉主题。交叉视角(CV)为使用0度和90度的视角进行训练,然后使用45度的视角进行测试,此时不区分主题。交叉主题(CS)为20个主题 用于训练,另外20个主题用于测试,此时不区分视角。在实验中我们的方法能得到目前为止最好的效果。与此同时,我们提出一种新的评价准则,使得该任务更加具有 挑战性。在交叉主题的训练中,我们原来我们是不区分视角的,而此时我们在用于训练的20个主题中只训练0度视角的数据,而测试的使用不区分视角。我们称这种方法 为:cross- view-subject (CVS)。
UESTC RGB-D varying-view 3D action dataset (UESTC).:该数据在收集的时候使用了8个摄像机,他们平等的架设在人的四周,能够360度覆盖。 该数据集有118个主题,40个行为分类,总共有26500个视频,每个视频至少有200帧。官方的评价准则(CV-I)是训练一个视角,然后测试剩余的7个视角。为了增 加挑战性, 我们也提出了一个新的评价准则(CV-II),我们测试的时候使用多个视角,然后测试的时候使用剩余的多个视角。例如训练的时候使用0,2,4,6视角, 测试的时候使用1,3,5,7视角。
One-shot Kinetics-15 dataset (Kinetics-15):前面两个数据集周围的环境都是室内,而 Kinetics 是室外的数据集,本文使用的数据集是 Mini-Kinetics-200,Kinetics-400的一个子集。我们将 Mini-Kinetics-200 中的数据定义为15个类。在训练的时候我们从每个类中随机选择一个样本, 测试的时候我们使用全部的725个视频进行测试。这种方法使得我们在挑选训练数据的时候对数据非常敏感,因为如果选择的那个样本在抽取3D人体数据的时候时候 失败了,那么后面的所有预测都会非常的困难。
Ablation Study
首先我们对比了1只使用真实数据,2只使用合成数据,3使用合成数据与真实数据,进行训练得到的结果。然后我们探讨了一下动作估计的有效性。然后我们对比了不使 用合成数据而直接使用动作数据的特征和使用合成数据的优劣。然后我们还实验了在合成数据的时候使用不同的参数对不同的动作和视角的影响。
我们还对比了两种不同的获得3D动作的方法,HMMR 和 VIBE,我们发现使用 VIBE 效果会更好一些,通过这个现象我们可以发现,如果使用一个更好的获得 3D动作的方法,就能使我们的实验有更好的效果。
我们还研究了一个问题就是直接使用3D动作的参数,作为输入,来进行行为分类,而不是使用合成数据。最后实验表明使用合成的数据进行训练能得到更好的效果。 其中一个重要的原因就是使用合成的数据可以拥有很多数据增强,而且还可以在训练的时候通过合成的数据看到在真实数据中没有出现过的视角的行为。
我们还分析了样本的个数对识别率的影响。在没有合成数据的时候,当我们对每个类别使用小样本的时候,往往效果不好,但是使用了合成数据之后,即使使用很小的 数据量来进行训练,也能得到不错的效果。
我们还分析了不同的视角对预测准确率的影响。通过实验我们发现对于合成数据,如果我们的合成数据中没有对应的视角,那么在测试的时候往往效果不好。如果我们 使用全部的视角,就能获得最好的效果。
我们还分析了对于同一个分类,我们使用插值的方式得到新的合成数据。我们还通过实验发现我们用插值合成的数据在最终的效果上比改变衣服,体型,灯光 更有效。
Comparison with the state of the art
然后我们将自己的方法与当前最好的方法分别在 UESTC 和 NTU 数据集上做对比。
One-shot training
我们在Kinetics-15数据集上做了单例训练的实验,最后发现我们的方法对 One-shot 的训练有很大的优势。
Conclusions
我们提出了一个合成的数据集,通过该数据集能提升我们在 UESTC 和 NTU 数据集上的人类行为识别的准确率,特别是对没见过的视角和One-shot训练,我们都有 很好的效果。但是我们的方法受限于3D姿势估计的方法,在一些杂乱的场景中,我们的准确率并不高。
未来可能的研究方向包括将动作串进行受限行为的生成,和对行为识别进行上下文线索的模拟。
SURREACT dataset:通过 NTU RGB+D 和 UESTC 这两个标准的人类行为视频数据集来合成大量的多视角,多背景,多服饰,多身体形态的数据集。 SURREAL dataset(from 83):从多个人体动作视频数据集中合成的一个新的,多视角的人体动作视频数据集。
related papers
(83) Learning from Synthetic Humans 对于图像分割,其中有一个任务是通过输入一张图像,能够分割出人 的同时也要能分割出这个人在该图像中的景深信息。 对于这样一个任务,我们可用的数据集很少,于是本文就提出一个方法来人工合成一个数据集(SURREAL)。这 篇文章说我们使用 CMU MoCap数据集,然后将 SMPL 人体参数信息拟合到MoCap数据中,然后改变人的衣服,环境,周围灯光,相机位置,最终用 Blender 合成大 量的图像。
![figure_3]
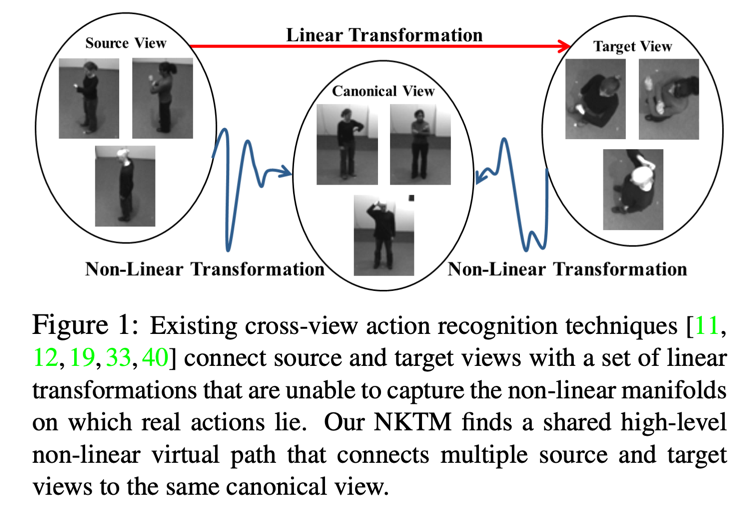
(65) Learning a Non-linear Knowledge Transfer Model for Cross-View Action Recognition 本文提出一种方法来将视频中不同角度运动转换到一个最常用的经典角度,从而提升视频中动作识别的准确率。而且这个方法是一种无监督学习的方式。本文的出发 点是希望这样做了之后,当我们在一个有限的数据集上训练一个网络,在测试的时候,如果我们碰到了一个动作,它的拍摄角度 是之前训练数据集里面没有的话, 那么该网络就对这种视频的动作识别准确率很差,但是如果我们有个方法,能够使得所有的测试集在进入到网络之前都全部转换成我们最常见的经典角度,这个时候我 们的网络 就可以很容易的识别该动作了。
(43) Learning human pose models from synthesized data for robust RGB-D action recognition : 本文提出一个视频动作识别的方法。1 我们从 CMU MoCap 数据集中使用 HDBSCAN 方法获得3D的动作结构框架,然后用MakeHuman方法来用一个模拟的人的来 填充该 skeleton ,得到一个3D的人的姿势, 接下来我们改变模特的衣服和灯光,背景等,使用 Blender 合成一个新的动作图像。同时我们使用一个GAN结构 的网络来使得合成的图像看上去更像是真实的图像。2 我们设计了一个 CNN的神经网络(HPM),该网络和GAN一起,使得不管我们改变相机视角,衣服,模特形态, 背景环境,灯光,他都能够识别输入的human poses。3 我们将2中的 网络得到的特征再用来训练一个时间模型 Fourier Temporal Pyramid 和分类模型 SVM, 最终来进行人类行为的识别。

(HMMR) Learning 3D Human Dynamics from Video: 利用神经网络来得到单张图像上人的SMPL信息。
(VIBE) VIBE: Video Inference for Human Body Pose and Shape Estimation: 与HMMR类似, 只是使用的网络架构不一样。
本文由 louis 创作,采用 知识共享署名4.0 国际许可协议进行许可
github 地址 https://github.com/7568/7568.github.io
最后编辑时间为:2022-10-28