简介
论文地址:https://proceedings.neurips.cc/paper/2020/file/7d97667a3e056acab9aaf653807b4a03-Paper.pdf
代码地址:https://github.com/jsyoon0823/VIME
使用自监督和半监督来对表格型的数据进行神经网络的预训练
VIME (Value Imputation and Mask Estimation)
论文介绍
1- 在神经网络处理图像和文字的时候,通常使用一些预训练就可以提升模型的准确率。本文将神经网络处理文字和图像中使用的预训练方法使用到表格型的数据中, 发现能对模型的预测能力有提升。而且在进行预训练的时候还使用了一些数据增强的方法。
2- 具体使用的预训练方法为自监督学习和半监督学习。
自监督学习
首先介绍两种借口任务,
第一个是特征向量估计,预测哪些特征是被遮住的
第二个是掩码向量估计,预测那些被遮住的特征的原始值
首先根据输入样本生成一个掩码向量 m ,m里面都是0或者1
然后就可以得到一个生成的数据

其中 \(\bar{x}\) 生成方法如下:
首先初始化一个与\(x\)维度一样,值全为0的矩阵 x_bar
然后循环遍历 \(x\) 的列,将得到的列数据随机打乱顺序,然后将打乱顺序后的数据放入到x_bar中,这样x_bar中每一列的数据跟x中的一样,但是顺序不一样。
这样我们就可以将 \(\tilde{x}\) 放入到我们的编码网络中进行训练。我们在编码网络后面并联的接上两个网络,分别用来进行特征向量估计和掩码向量估计
整体的自监督网络图如下:
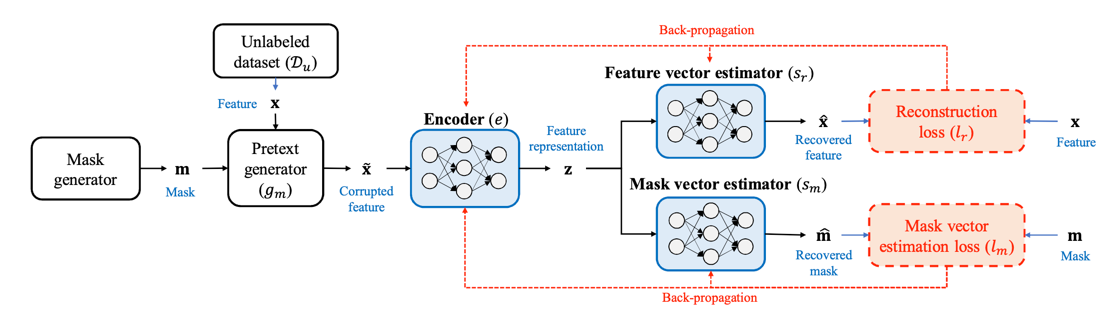
其中 \(S_m\) 和 \(S_r\) 的网络结构一样,只是他们的损失函数不一样 \(S_m\) 的损失函数为:
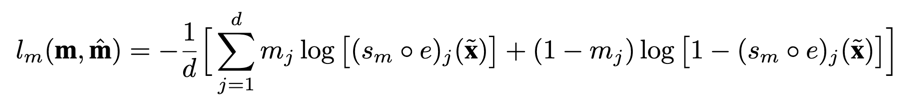
\(S_r\) 的损失函数为:
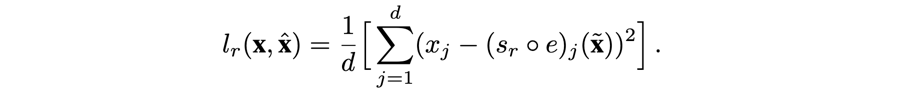
最终通过改网络来学习编码器Encoder(e)的参数
半监督学习
在自监督学习中我们得到了一个编码器Encoder(e),然后作者设计了一个包含编码器和预测网络的半监督训练网络模型,整体模型的结构如下:
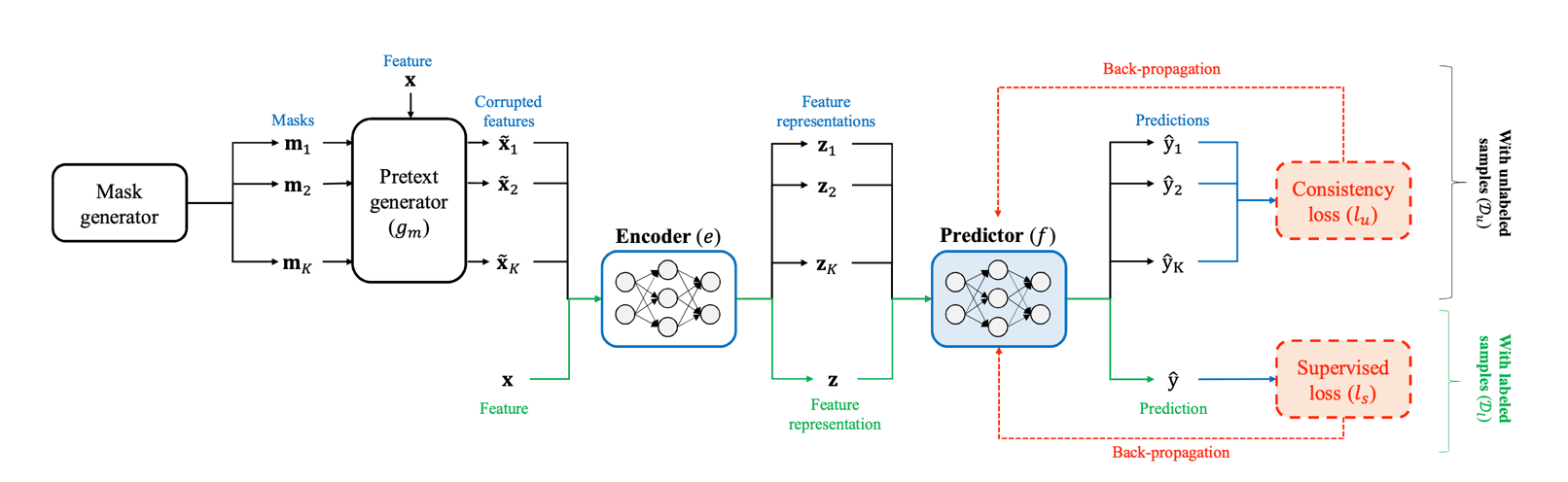
具体工作流程为:首先根据一份样本x生成K份掩码,然后通过K个掩码得到K个\(\tilde{x}\),然后将这K个\(\tilde{x}\)和x分别通过编码器Encoder(e), 得到\([z_1 , z_2 , ... , z_K , z ]\),其中\(z\)是x通过编码器Encoder(e)得到的输出,然后我们再将\([z_1 , z_2 , ... , z_K , z ]\) 分别通过预测器Predictor(f), 就得到\([\hat{y_1} , \hat{y_2} , ... , \hat{y_K} , \hat{y} ]\),最后我们使用 \([\hat{y_1} , \hat{y_2} , ... , \hat{y_K} ]\) 来进行一致性学习,使用\(\hat{y}\)来进行有监督学习。
所谓的一致性学习指的是我们假设模型对看似不同的输入能有相同的输出。在本文中作者使用\([\hat{y_1} , \hat{y_2} , ... , \hat{y_K} ]\) 和 \(\hat{y}\) 的差异来表示一致性。
具体数学表达式如下:
整个半监督的损失函数如下:
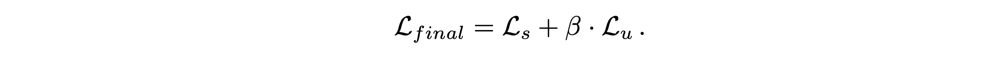
其中\(\mathcal{L}_s\)指的是有监督的学习中的损失,\(\mathcal{L}_u\)无监督学习中的损失
\(\mathcal{L}_s\)表达式如下:
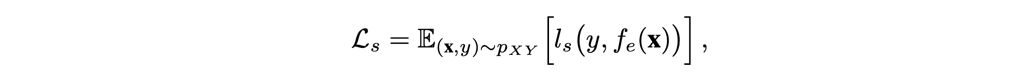
作者在文中,对于回归任务使用均方误差函数,对于分类任务使用交叉熵函数
\(\mathcal{L}_u\)表达式如下:
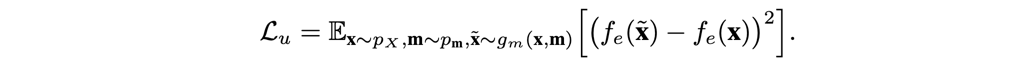
作者在文中使用的无监督损失函数为:
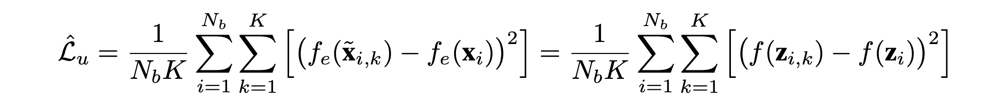
改函数指的是
\([\hat{y_1} , \hat{y_2} , ... , \hat{y_K} ]\) 与 \(\hat{y}\)的均方误差。
以上就是VIME的主要思想。
本文由 louis 创作,采用 知识共享署名4.0 国际许可协议进行许可
github 地址 https://github.com/7568/7568.github.io
最后编辑时间为:2022-10-28