简介
在文本处理中有两个经典的网络模型,一个是基于循环神经网络加上 attention 的 Seq2Seq 和完全基于 attention 的 Transformer。这两个模型在机器翻译中都取得了很好的效果。 本文中很大一部分内容来自翻译 Seq2seq Models With Attention 和 The Illustrated Transformer 。 代码参考于 https://github.com/bentrevett/pytorch-seq2seq
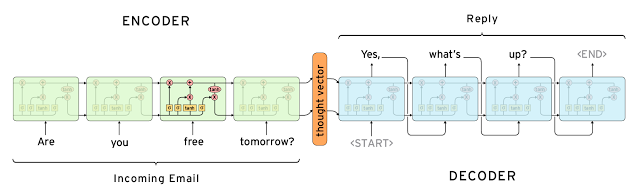
本篇将主要讲述和翻译在Seq2seq Models With Attention 中的内容,Seq2seq的相关论文地址在Sutskever et al. , Cho et al., 2014 我们将在下一篇文章 中讲述Transformer,也就是The Illustrated Transformer 中的内容
所有代码都可在文末下载,这些代码都是我从bentrevett / pytorch-seq2seq 中提取出的
模型介绍
Sequence-to-sequence模型是一个深度学习神经网络模型,在很多像机器翻译,短文总结,和图像描述等任务中都取得了很好的成绩。接下来我将通过本blog来介绍 Seq2Seq 模型的相关内容和代码。希望对于初学者有所帮助。
本文主要讲述的代码是 Seq2Seq 模型在机器翻译上英文对德文的翻译。
Seq2Seq 模型是典型的 encoder-decoder 模型,下面的动画将介绍 Seq2Seq 进行机器翻译时候的基本工作流程。左边是输入,右边是输出。
下面这个视频来自于 https://github.com/google/seq2seq 不过 https://github.com/google/seq2seq中的内容对本文关系不大
encoder
在 Seq2Seq 模型的 encoder 中,要进行的工作有:
- 将输入 X1 字符编码,变成数字类型,即 Word2Vec,得到 X1_Vec,如果我们的输入是 “早上好”,在 Word2Vec 中,先会加上开始标志
<sos>和结束标志<eos>, 这样输入就变成了5个字符,然后每个字符用一串0和1表示,于是得到5个Vector,就是我们想要的 X1_Vec 。 - 将 X1_Vec 中的5个 Vector 依次按顺序放入到RNN中,得到一个输出 Z
比如这样
decoder
在 decoder 中,首先我们要对标签进行编码,然后,将编码后的结果放入到一个神经网络中,用来提取特征,
代码实现
数据准备
首先我们要安装pytorch(1.0以上),torchtext,spacy
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.legacy.datasets import Multi30k
from torchtext.legacy.data import Field, BucketIterator
import spacy
import numpy as np
import random
import math
import time
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
我们通过执行一下脚本来安装数据集
$ python -m spacy download en_core_web_sm
$ python -m spacy download de_core_news_sm
然后加载数据集
spacy_de = spacy.load('de_core_news_sm')
spacy_en = spacy.load('en_core_web_sm')
接下来就是我们的编码阶段 首先我们将输入的一串连续的字符转换成list,如 ‘早上好’ 转换成 ‘[早,上,好]’ ,然后再将他们变成 0,1 编码,代码如下
def tokenize_cn(text):
"""
Tokenizes German text from a string into a list of strings (tokens) and reverses it
将德文的一段话进行编码,将每个汉字都编码成一个字符串式的tokens。然后将他们反转,反转是为了放入RNN的时候保证最先放入的是一开始的字符,而不是最后的字符
"""
return [tok.text for tok in spacy_de.tokenizer(text)][::-1]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings (tokens)
英文同德文一样
"""
return [tok.text for tok in spacy_en.tokenizer(text)]
在 torchtext 中已经有方法帮我们实现编码方法,我们只需要调用如下方法,分别进行德文和英文的编码
SRC = Field(tokenize = tokenize_de,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)
TRG = Field(tokenize = tokenize_en,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)
接下来我们加载数据集,然后自动分为训练数据,验证数据,和测试数据,本数据集使用的是 Multi30k dataset , 里面包含有 30000 条英文对法文和德文的句子。
train_data, valid_data, test_data = Multi30k.splits(exts = ('.cn', '.en'), fields = (SRC, TRG))
我们检查一下每个数据集的大小
print(f"Number of training examples: {len(train_data.examples)}")
print(f"Number of validation examples: {len(valid_data.examples)}")
print(f"Number of testing examples: {len(test_data.examples)}")
查看一个样本数据,看看数据集的格式是什么样子的。
print(vars(train_data.examples[0]))
我们得到的输出是这样子的,前面的 src中是德语,后面的 trg中是英语。
{'src': ['.', 'büsche', 'vieler', 'nähe', 'der', 'in', 'freien', 'im', 'sind', 'männer', 'weiße', 'junge', 'zwei'], 'trg': ['two', 'young', ',', 'white', 'males', 'are', 'outside', 'near', 'many', 'bushes', '.']}
接下来我们对训练集的输入和输出进行 vocabulary 处理, vocabulary 处理其实就是找出输入输出中所有的单词,然后去重,然后给去重后的每个单词排序,得到每个单词的index,这个index就是每个单词的编码。
执行 vocabulary 处理代码如下
# 构建词汇,构建之后,SRC 就多了个 vocab 属性,vocab 中包含有 freqs、itos、stoi 三个属性,其中freqs 表示的是 SRC 中每个单词和该单词的频数,也就是个数。
# itos 是一个列表,包含的的是频数 >= 2 的单词,stoi 用来标记 itos 中每个单词的索引,从0开始。
# 例如 输入是['two', 'two', ',', 'two', 'two', 'are', 'outside', 'near', 'many', 'bushes', 'two', 'young', ',', 'white', 'white', 'near', 'outside', 'near', 'many', 'bushes', '.']
# 则 freqs 是({'two': 5, 'near': 3, ',': 2, 'outside': 2, 'many': 2, 'bushes': 2, 'white': 2, 'are': 1, 'young': 1, '.': 1})
# itos 是 ['<unk>', '<pad>', '<sos>', '<eos>', 'two', 'near', ',', 'bushes', 'many', 'outside', 'white']
# 其中 <sos>:一个句子的开始,<eos>:一句话的结束,<UNK>: 低频词或未在词表中的词,比如我们设置 min_freq = 2 ,那么那些只出现了 1 次的单词,将来在放入到神经网络之前都会被 <UNK> 替换掉
# <PAD>: 补全字符,由于我们在进行批量计算的时候,每个样本的长度不一样,<PAD>就是用于保证样本长度一样的。参考于 https://github.com/nicolas-ivanov/tf_seq2seq_chatbot/issues/15
# 由于我们的 min_freq = 2 ,所以可以看到频数为1的 'are','young', '.' 都没有在 itos 中。
# stoi 是 {'<unk>': 0, '<pad>': 1, '<sos>': 2, '<eos>': 3, 'two': 4, 'near': 5, ',': 6, 'bushes': 7, 'many': 8, 'outside': 9, 'white': 10})
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)
# 输出一下结果
print(f"Unique tokens in source (de) vocabulary: {len(SRC.vocab)}")
print(f"Unique tokens in target (en) vocabulary: {len(TRG.vocab)}")
我们接下来看看我们的数据在进入到神经网络之前,都经历了怎样的处理 :
-
首先是我们的原始数据,如下图展示。
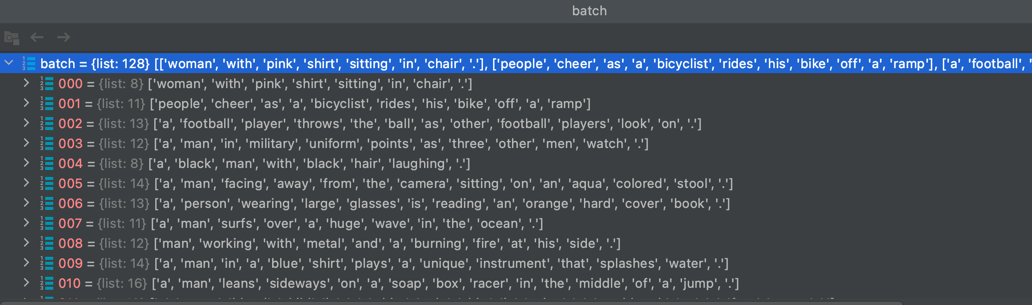
-
接下来是我们的填充,首先在每句话的开始和结束分别加上’<sos>‘和 ‘<eos>’ , 然后将整个 batch 中的数据对齐,按照最长的句子对齐, 不够的用 ‘<pad>’ 来填充,如下图所示。

-
最后就是将输入数据进行数字化处理,将每个单词分别转换成它所对应的索引,该索引就是 SRC.vocab stoi 中的值 ,如下图所示。

到此,我们的数据预处理就完成了。
Encoder
接下来我们构造我们的 encoder 模型
在RNN系列中,传统的RNN存在比较大的梯度消失和梯度爆炸的问题,所以现在大家常常用LSTM来代替RNN,本文也将使用 LSTM 来进行编码,在 Understanding LSTM Networks 中有对 LSTM 的详细介绍。
我们先看看LSTM的结构,该结构图来自于dive into deep learning
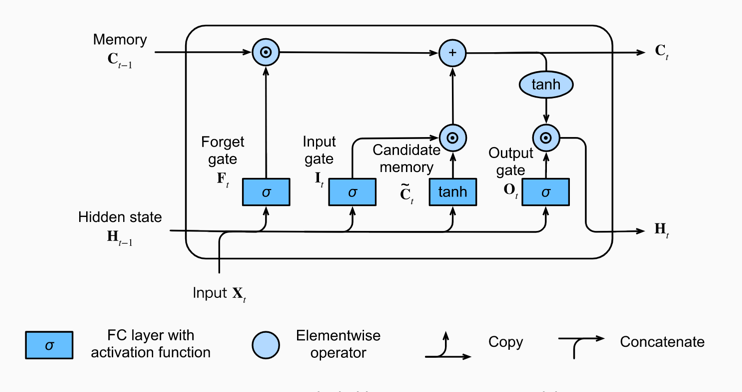
最终的输出就是把 \(H_t\) 做一个线性变换,直接将 \(H_t\) 当作输出也是可以的。在 Understanding LSTM Networks 这篇文章中有关于 LSTM 更加详细的介绍。
于是我们的seq2seq模型就变成了如下结构,该图来自于 nicolas-ivanov
在原论文中作者使用的是4层LSTM,本文我们只使用2层LSTM进行训练。其中每层中又包含有多个LSTM单元,具体有多少个是根据输入的长度决定的。LSTM我们可以表示成如下表达式:
\[(h_t,c_t) = LSTM(e(x_t),h_{t-1},c_{t-1})\]其中 \(h_t\) 和 \(c_t\) 分别表示第 t 个LSTM的输出中的隐藏单元和记忆单元,\(x_t\) 表示第 t 个输入,\(e(x_t)\) 表示将第 t 个输入进行 embedding 处理。\(h_(t-1),c_(t-1))\) 分别表示上一层的输出中的隐藏单元和记忆单元。 在理解上我们可以把 \(h_t\) 和 \(c_t\) 都当成隐藏单元,只不过计算方式不一样。其中 \(h_0\) 和 \(c_0\) ,是初始化随机生成的 。
\[z^i = (h_l^i,c_l^i)\]我们令 \(z^1\) , \(z^2\) 分别为每个隐藏单元的输出。\(z^i\) 表示第 i 层的输出。\(h_l^i\) 和 \(c_l^i\) 表示第 i 层的最后一个LSTM单元的隐藏单元的输出和记忆单元的输出。
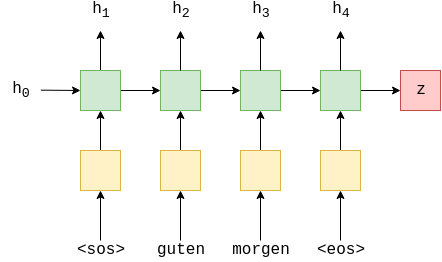
下图是一个LSTM编码的例子。其中黄色方块表示对输入进行 embedding 处理,有2层绿色方块,表示有两层LSTM网络,每个绿色方块都表示一个LSTM单元,红色方块表示每层的输出。
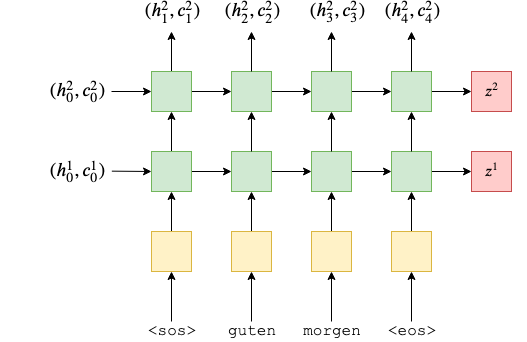
在 PyTorch 中,我们可以使用 nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout) 来创建一个LSTM网络,其中 :
- emb_dim:输入的维度, 不是指一句话的长度,而是每个单词 embedding 之后的向量的长度。
- hid_dim:隐藏单元的维度。
- n_layers:网络的层数,也是深度。
- dropout:每一层的 dropout。
Note: 需要注意的是,在LSTM中,如果我们的输入的维度只有1,那么我们就不能直接使用 nn.LSTM,而是使用 nn.LSTMCell,因为如果直接使用 nn.LSTM 会有维度转换的问题。
代码如下:
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
#src = [src len, batch size]
embedded = self.dropout(self.embedding(src))
#embedded = [src len, batch size, emb dim]
outputs, (hidden, cell) = self.rnn(embedded)
#outputs = [src len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#outputs are always from the top hidden layer
return hidden, cell
embedding
下面这张图很好的介绍了 embedding 的过程
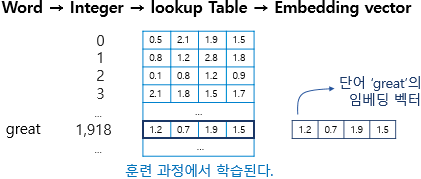
下面是pytorch的embedding文档中的例子。nn.Embedding(10, 3) ,就是随机生成一个 10x3 的表,然后当进行embedding的时候,每一个输入都对应着一行数据。
>>> # an Embedding module containing 10 tensors of size 3
>>> embedding = nn.Embedding(10, 3)
>>> # a batch of 2 samples of 4 indices each
>>> input = torch.LongTensor([[1,2,4,5],[4,3,2,9]])
>>> embedding(input)
tensor([[[-0.0251, -1.6902, 0.7172],
[-0.6431, 0.0748, 0.6969],
[ 1.4970, 1.3448, -0.9685],
[-0.3677, -2.7265, -0.1685]],
[[ 1.4970, 1.3448, -0.9685],
[ 0.4362, -0.4004, 0.9400],
[-0.6431, 0.0748, 0.6969],
[ 0.9124, -2.3616, 1.1151]]])
Decoder
我们再来构造我们的 decoder 模型
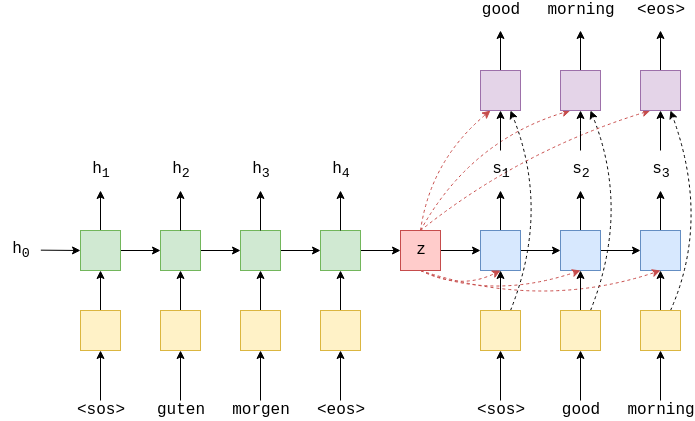
decoder 模型我们也是使用2层 LSTM ,原论文是4层。 网络结构跟 encoder 非常相似,是不过这里的 \(h_0\) 和 \(c_0\) 变成了 encoder 中的 \(z^1\) , \(z^2\) 。
下图展示的是我们的decoder的结构图
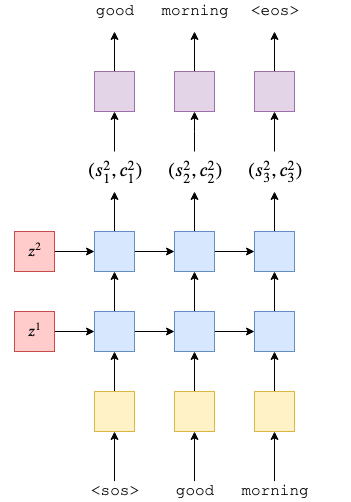
在最后我们将输出传入到一个全连接网络中,得到我们的输出。
接下来是 decoder 的代码实现:
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
#input = [batch size]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#n directions in the decoder will both always be 1, therefore:
#hidden = [n layers, batch size, hid dim]
#context = [n layers, batch size, hid dim]
input = input.unsqueeze(0)
#input = [1, batch size]
embedded = self.dropout(self.embedding(input))
#embedded = [1, batch size, emb dim]
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
#output = [seq len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#seq len and n directions will always be 1 in the decoder, therefore:
#output = [1, batch size, hid dim]
#hidden = [n layers, batch size, hid dim]
#cell = [n layers, batch size, hid dim]
prediction = self.fc_out(output.squeeze(0))
#prediction = [batch size, output dim]
return prediction, hidden, cell
Seq2Seq
接下来我们看看我们的 Seq2Seq 整体的结构,在我们的 Seq2Seq 模型中,我们将 Seq2Seq 分成三部分,分别是:
- 接收输入数据和目标数据,并将他们进行预处理
- 将输入数据进行 encoder ,得到输入的特征。
- 将目标数据进行预处理,同时将 encoder 中得到的输入特征作为 LSTM 的初试值,一起放入到 decoder 网络中,得到输出。
整体结构如下图所示:
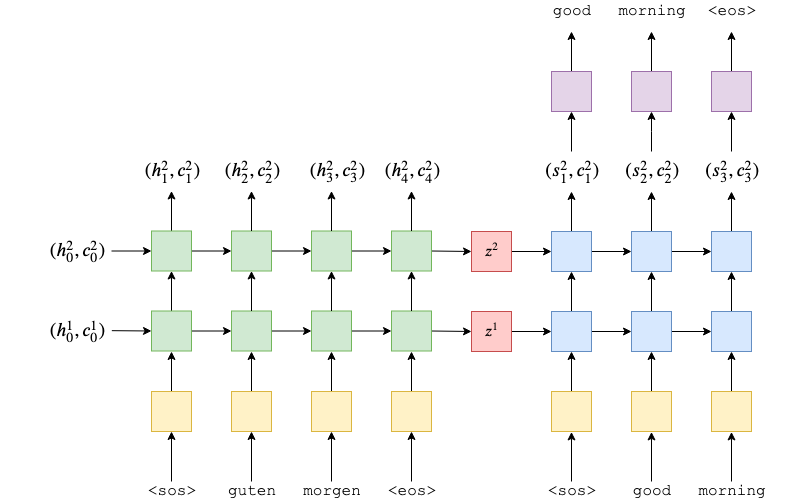
在 Seq2Seq 模型中,我们通常将 encoder 的层数与 decoder 的层数设置为一样,这不是必须的,但是这样做能方便我们处理模型。
代码如下:
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
assert encoder.hid_dim == decoder.hid_dim, \
"Hidden dimensions of encoder and decoder must be equal!"
assert encoder.n_layers == decoder.n_layers, \
"Encoder and decoder must have equal number of layers!"
def forward(self, src, trg, teacher_forcing_ratio = 0.5):
#src = [src len, batch size]
#trg = [trg len, batch size]
#teacher_forcing_ratio is probability to use teacher forcing
#e.g. if teacher_forcing_ratio is 0.75 we use ground-truth inputs 75% of the time
batch_size = trg.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
#tensor to store decoder outputs
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
#last hidden state of the encoder is used as the initial hidden state of the decoder
hidden, cell = self.encoder(src)
#first input to the decoder is the <sos> tokens
input = trg[0,:]
for t in range(1, trg_len):
#insert input token embedding, previous hidden and previous cell states
#receive output tensor (predictions) and new hidden and cell states
output, hidden, cell = self.decoder(input, hidden, cell)
#place predictions in a tensor holding predictions for each token
outputs[t] = output
#decide if we are going to use teacher forcing or not
teacher_force = random.random() < teacher_forcing_ratio
#get the highest predicted token from our predictions
top1 = output.argmax(1)
#if teacher forcing, use actual next token as next input
#if not, use predicted token
# 判断下一个的输入,是使用训练集中的还是使用从 decoder 中预测的
input = trg[t] if teacher_force else top1
return outputs
从代码中我们可以看到,我们先是将整个源数据放入 encoder 中(源数据指的是训练数据中的 src 数据),然后我们一个一个的遍历目标数据, 首先我们将 ‘<sos>’ 放入到 decoder 中,得到一个输出,保存到输出的结果中。然后我们以一定的概率来判断是否要使用目标数据中的下一个当作输入, 也就是说我们的decoder的输入不一定全是目标数据。
接下来我们看看我们的训练代码
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
HID_DIM = 512
N_LAYERS = 2
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, N_LAYERS, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DEC_DROPOUT)
model = Seq2Seq(enc, dec, device).to(device)
def init_weights(m):
for name, param in m.named_parameters():
nn.init.uniform_(param.data, -0.08, 0.08)
model.apply(init_weights)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
optimizer = optim.Adam(model.parameters())
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index=TRG_PAD_IDX)
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg)
# trg = [trg len, batch size]
# output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
# trg = [(trg len - 1) * batch size]
# output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
我们使用 Adam 优化器,CrossEntropyLoss 损失函数,在 CrossEntropyLoss 中我们不计算为了保持batch中样本长度一致而填充的部分。 训练中还使用了 torch.nn.utils.clip_grad_norm_ 方法,该方法指的是将每一次迭代中,反向传播时候的梯度进行归一化并限制住grad,防止梯度爆炸和消失。
接下来就是开始我们的训练了。
训练了20个epoche之后,我们来进行测试以下
测试
测试过程为:
- 我们将我们的要翻译的源数据先进行encoder计算,得到 hidden, cell ,
- 然后我们将开始描述符
\<sos\>当作输入,跟 hidden, cell 一起放入到decoder中去,这个时候得到一个输出和新的 hidden, cell 。 - 我们将输出保存下来,然后将该输出与新的 hidden, cell 一起当作输入放入到decoder中去,如此循环,就可以得到我们的翻译语句了。
在测试中,通过设置max-len,也就是说输出的最大长度,从而来决定输出的句子的长度。当decoder中得到的结束符就停止,否则直到max-len结束。
最终结果:| Test Loss: 3.943 | Test PPL: 51.571 |
GRU 的简单介绍
在 2 - Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation 中 作者还做了使用 GRU (Gated Recurrent Unit) 来替代 LSTM 进行机器翻译的训练,使用了更多的参数,有更好的效果。不过其实有人做过实验,发现其实 GRU 与 LSTM 性能几乎是差不多的 论文链接 在此。
下图是 GRU 的encoder结构图,这里使用的是一层网络
从图上我们可以看到,几乎与LSTM一样,需要提醒的是每一个绿色的方块都代表一次GRU操作,每次GRU都是一样的,也就是说上图是一个单层,单个GRU的模型, 即 ‘<sos>’ 先进入 GRU,运算后得到输出,再 guten 进入 GRU,还是之前的那个 GRU,只是输入参数不一样了,GRU 里面的参数此时是一样的。
下图是 GRU 的decoder结构图,此处我们对decoder稍作修改,能让网络有更好的性能,具体做法是将 z 拼接到decoder的每一次运算中,再将 decoder 中运 行的结果都拼接到后面,一起当作输入。其余的过程跟跟 LSTM 很相似。效果入下图。

其中紫色的方块表示全连接。decoder与之前的LSTM结构的decoder的连结方式不一样,在 GRU 中 encoder 的输出会被使用到每一个 decoder 的节点中来。
下图是使用 GRU 模型的seq2seq模型
整个结构与使用 LSTM 结构的seq2seq 模型并无太大的差别,此处就不过多介绍。在 2 - Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation 中有详细的代码实现。
Align 介绍
在前面我们介绍了 LSTM 和 GRU 模型,他们在处理输入的时候,都是将一句话从头到尾都经过一次神经网络,在 Neural Machine Translation by Jointly Learning to Align and Translate 论文中,作者提出了双向的网络模型,就是说让我们的输入先从头到尾进入一个网络,然后再从尾到头经过另一个网络,即双向 RNN ,这样我们就有了两个输出。 具体结构如下:
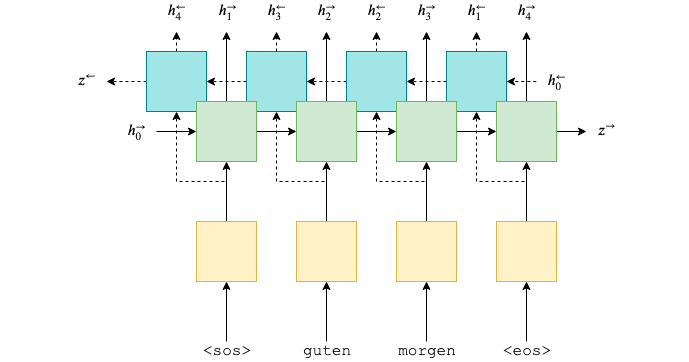
可以用数学表达为:
\[h_t^{\to} = EncoderGRU^{\to}(e(x_t^{\to}) , h_{t-1}^{\to})\] \[h_t^{\gets} = EncoderGRU^{\gets}(e(x_t^{\gets}) , h_{t-1}^{\gets})\]其中 \(x_0^{\to}=<sos> , x_1^{\to}=guten\) ,\(x_0{^\gets}=<eos> , x_1^{\gets}=morgen\)
我们再来看看论文中关于align的介绍如下图

在 decoder 中,输入包含了 一个双向的 encoder 的拼接,也就是说一句话中的某个单词的预测翻译,会加上所有的输入的信息。但是实际中我们往往不需要全部的信息, 所有这里就引入了Attention机制,使得在拼接的时候有选择性的拼接。也就是说某个单词的预测翻译,与输入中的某几个单词有关,至于是哪几个,则是通过网络来学习的。
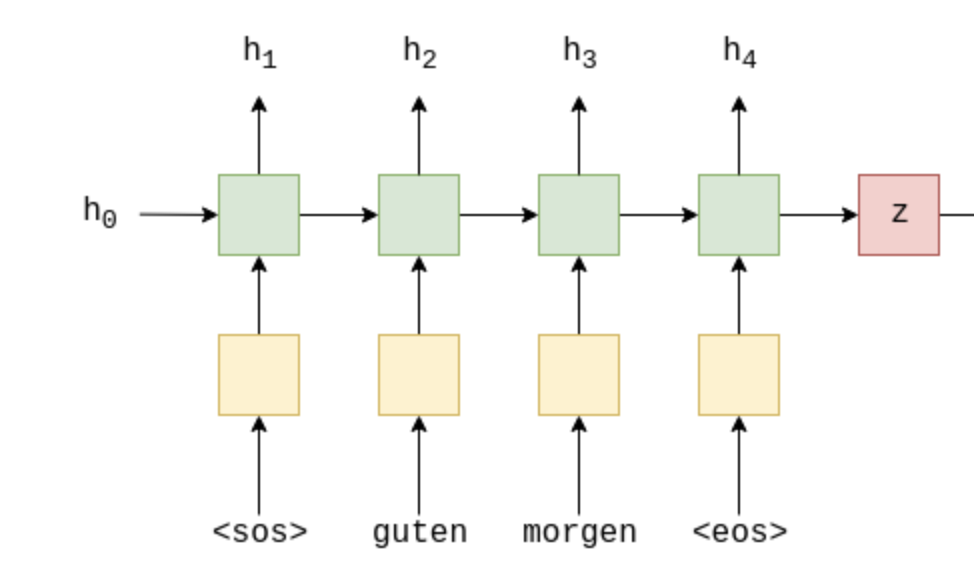
Attention 介绍
Attention 也叫注意力机制,原理就是接受输入,然后输出一个向量,该向量所有的值都是[0,1]之间的数,向量的和为1,通常的做法是通过最后一层网络后,加上一个SoftMax激活函数。
下图是一个RNN中计算 Attention 的一种方式:
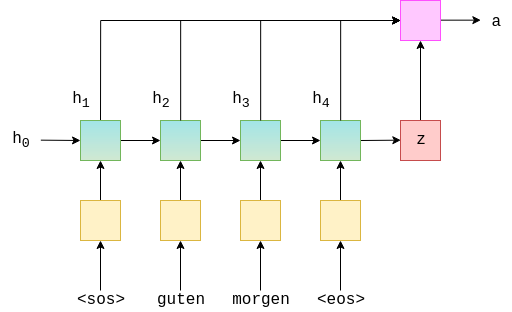
从图中可以看到,z为 rnn 的输出,\(h_1\) ~ \(h_4\)为每个输入的隐藏单元,我们将 z 与 \(h_1\) ~ \(h_4\) 一起放进一个神经网络中,得到 Attention a,该神经网络通常选择为全连接。
下图是 decoder部分,
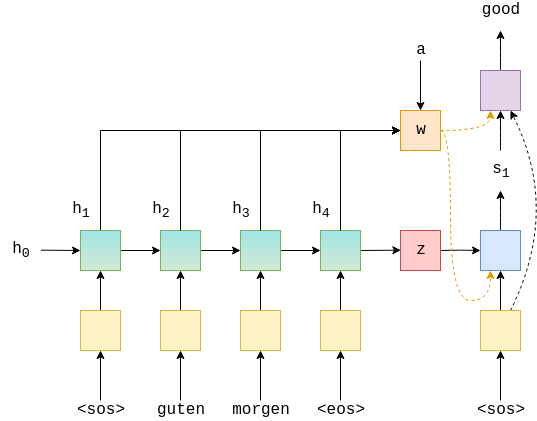
在我们没有 Attention 机制的 RNN 中,encoder 的输出 z 是要参与到 decoder 的所有操作中的。而在带有 Attention 机制的 RNN 中,z 此时只是参与到 GRU 中当作输入, 此时表示 Attention 的 a 参与到 decoder 的所有操作中的,相比于传统的 GRU,带 Attention 机制的 RNN 能够携带上在 encoder 中的每一次计算的隐藏单元 h,能够把能多的信息传递到 decoder 中。
在 decoder 中我们需要关注两个地方,1:是 w 是如何参与蓝色方框的运算,2:w 是如何参与到紫色方框的运算。从代码中我们可以看到,
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout, attention):
super().__init__()
self.output_dim = output_dim
self.attention = attention
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU((enc_hid_dim * 2) + emb_dim, dec_hid_dim)
self.fc_out = nn.Linear((enc_hid_dim * 2) + dec_hid_dim + emb_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, encoder_outputs):
#input = [batch size]
#hidden = [batch size, dec hid dim]
#encoder_outputs = [src len, batch size, enc hid dim * 2]
input = input.unsqueeze(0)
#input = [1, batch size]
embedded = self.dropout(self.embedding(input))
#embedded = [1, batch size, emb dim]
a = self.attention(hidden, encoder_outputs)
#a = [batch size, src len]
a = a.unsqueeze(1)
#a = [batch size, 1, src len]
encoder_outputs = encoder_outputs.permute(1, 0, 2)
#encoder_outputs = [batch size, src len, enc hid dim * 2]
weighted = torch.bmm(a, encoder_outputs)
#weighted = [batch size, 1, enc hid dim * 2]
weighted = weighted.permute(1, 0, 2)
#weighted = [1, batch size, enc hid dim * 2]
rnn_input = torch.cat((embedded, weighted), dim = 2)
#rnn_input = [1, batch size, (enc hid dim * 2) + emb dim]
output, hidden = self.rnn(rnn_input, hidden.unsqueeze(0))
#output = [seq len, batch size, dec hid dim * n directions]
#hidden = [n layers * n directions, batch size, dec hid dim]
#seq len, n layers and n directions will always be 1 in this decoder, therefore:
#output = [1, batch size, dec hid dim]
#hidden = [1, batch size, dec hid dim]
#this also means that output == hidden
assert (output == hidden).all()
embedded = embedded.squeeze(0)
output = output.squeeze(0)
weighted = weighted.squeeze(0)
prediction = self.fc_out(torch.cat((output, weighted, embedded), dim = 1))
#prediction = [batch size, output dim]
return prediction, hidden.squeeze(0)
input是decoder的输入, hidden是encoder输出的隐藏单元, encoder_outputs是encoder的输出,a = self.attention(hidden, encoder_outputs) 就是计算Attention,
weighted = torch.bmm(a, encoder_outputs) 将Attention与encoder_outputs进行矩阵相乘得到weighted,然后将weighted拼装进input编码之后的矩阵embedded中,
于是的到了新的 decoder的输入,将该新输入放入到GRU中去计算得到output。最后prediction = self.fc_out(torch.cat((output, weighted, embedded), dim = 1)) 将
‘output’, ‘weighted’, ‘embedded’ 一起拼装放入到一个全连接中,得到最终的预测值。
提升准确率
packed padded sequences
我们用 Packed padded sequences 来告诉我们的RNN网络,忽略掉 encoder 中为了对齐batch而添加 padding 的部分。 具体的做法如下:
SRC = Field(tokenize = tokenize_de,
init_token = '<sos>',
eos_token = '<eos>',
lower = True,
include_lengths = True)
TRG = Field(tokenize = tokenize_en,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
sort_within_batch = True,
sort_key = lambda x : len(x.src),
device = device)
其中 include_lengths = True 表示将来在我们的 batch.src 中将不再进行 padding 操作,还要记录每个句子的长度。 sort_within_batch = True,sort_key = lambda x : len(x.src), 表示将 batch 中的样本按照 len(x.src) 输入的长度排序,第一个是最长的。
这样我们的训练样本的 src 就不再是一个tensor了,而是一个 tuple ,里面的元素的长度都不一样,第一个最长,然后依次递减。
既然我们的模型需要接收tensor,所以就需要来对encoder做一些修改。以下是encoder的主要代码:
def forward(self, src, src_len):
# src = [src len, batch size]
# src_len = [batch size]
embedded = self.dropout(self.embedding(src))
# embedded = [src len, batch size, emb dim]
# need to explicitly put lengths on cpu!
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, src_len.to('cpu'))
packed_outputs, hidden = self.rnn(packed_embedded)
# packed_outputs is a packed sequence containing all hidden states
# hidden is now from the final non-padded element in the batch
outputs, _ = nn.utils.rnn.pad_packed_sequence(packed_outputs)
# outputs is now a non-packed sequence, all hidden states obtained
# when the input is a pad token are all zeros
# outputs = [src len, batch size, hid dim * num directions]
# hidden = [n layers * num directions, batch size, hid dim]
# hidden is stacked [forward_1, backward_1, forward_2, backward_2, ...]
# outputs are always from the last layer
# hidden [-2, :, : ] is the last of the forwards RNN
# hidden [-1, :, : ] is the last of the backwards RNN
# initial decoder hidden is final hidden state of the forwards and backwards
# encoder RNNs fed through a linear layer
hidden = torch.tanh(self.fc(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1)))
# outputs = [src len, batch size, enc hid dim * 2]
# hidden = [batch size, dec hid dim]
return outputs, hidden
代码中的 nn.utils.rnn.pack_padded_sequence 是用来打包我们的句子,从而可以放入到rnn中去。首先比如 nn.utils.rnn.pack_padded_sequence 的输入的维度是 [19, 128, 256],
19表示最长的句子的长度,128是batch,256表示每个单词的编码,此时的 embedded 是有 padding 的。还有一个输入是 src_len.to('cpu') ,表示每一个句子的长度, nn.utils.rnn.pack_padded_sequence 的输出是
将 embedded 中的句子取出来,取句子的方式如下图所示:图像来自stackoverflow
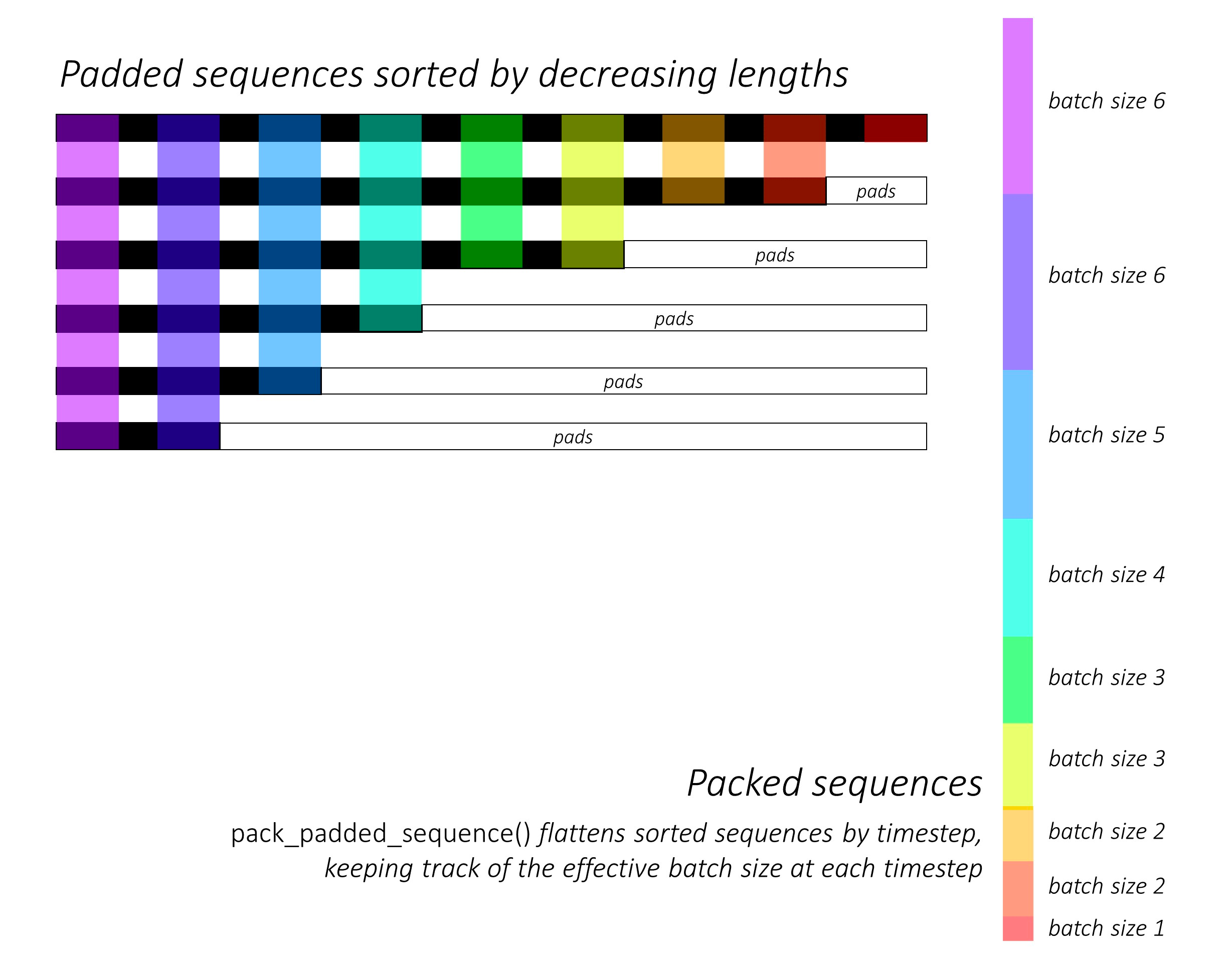 这个时候句子中就没有了 padding 了。
这个时候句子中就没有了 padding 了。
可能有人会问为什么 packed_embedded 中的内容是交替着从 embedded 的每个 batch 中取,而不是每个每个句子的取。以下是我的粗浅的理解,如果错了,有人看到了话请提交issue,我以后也会持续关注这个问题,动态更新。
我们可以将神经网络的运算想象成为矩阵的乘法。
比如batch为1的一个样本,例如是一个句子,句子长度为10,在全连接网络中,如果输出是一个数的话,整个网络我们可以描述出如下:
\[[i_1,i_2,i_3,\dots,i_{10}] \times \begin{bmatrix}* \\* \\ \vdots \\ * \end{bmatrix}_{10\times 1} = O_{1\times1}\]其中 \([i_1,i_2,i_3,\dots,i_{10}]\)表示输入,\(\begin{bmatrix}* \\* \\ \vdots \\ * \end{bmatrix}_{10\times 1}\)表示神经网络,\(O_{1\times 1}\) 表示输出。
如果是在循环神经网络中,我们先看看循环神经网络是如何工作,下图是一个简单的rnn的流程图解
所以循环神经网络的运算过程可以表示成
\[i_1 \times rnn = o_1 \\ \phi(o_1,i_2) \times rnn = o_2 \\ \phi(o_2,i_3) \times rnn = o_3 \\ \vdots \\ \phi(o_9,i_10) \times rnn = O \\\]此时将 batch 换成 n 的话,如果样本是对齐的。则所以循环神经网络的运算过程可以表示成
\[(i_{11},i_{21},...,i_{n1}) \times rnn = (o_{11},o_{21},o_{31},...,o_{n1}) = O_1 \\ \phi(O_1,(i_{12},i_{22},...,i_{n2})) \times rnn = (o_{12},o_{22},o_{32},...,o_{n2}) = O_2 \\ \phi(O_2,(i_{13},i_{23},...,i_{n3})) \times rnn = (o_{13},o_{23},o_{33},...,o_{n3}) = O_3 \\ \vdots \\ \phi(O_9,(i_{19},i_{29},...,i_{n9})) \times rnn = (o_{19},o_{29},o_{39},...,o_{n9}) = O_9 \\\]每一次与 rnn 相乘的都是batch中相应位置的单位数据。
所以在进行 nn.utils.rnn.pack_padded_sequence 之后,输出都是每个样本交替拼接而成的向量,由于数据不是对齐的,所以输出只能是向量,而不能是矩阵。
masking
Masking 是直接作用于网络让它直接忽略掉某些确定的值,例如让模型不将 Attention 使用到 padding 上。 例如输入是 [“hello”, “how”, “are”, “you”, “?”, <pad>, <pad>] 那么 masking 就是 [1, 1, 1, 1, 1, 0, 0] 。下面是带 masking 的 Attention 的代码。
class Attention(nn.Module):
def __init__(self, enc_hid_dim, dec_hid_dim):
super().__init__()
self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim)
self.v = nn.Linear(dec_hid_dim, 1, bias = False)
def forward(self, hidden, encoder_outputs, mask):
#hidden = [batch size, dec hid dim]
#encoder_outputs = [src len, batch size, enc hid dim * 2]
src_len = encoder_outputs.shape[0]
#repeat decoder hidden state src_len times
hidden = hidden.unsqueeze(1).repeat(1, src_len, 1)
encoder_outputs = encoder_outputs.permute(1, 0, 2)
#hidden = [batch size, src len, dec hid dim]
#encoder_outputs = [batch size, src len, enc hid dim * 2]
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim = 2)))
#energy = [batch size, src len, dec hid dim]
attention = self.v(energy).squeeze(2)
#attention = [batch size, src len]
# attention.masked_fill(mask == 0, -1e10) 指的是将 attention 与 mask 相乘,然后为0的地方换成-1e10,
# 为 -1e10 的地方会在 softmax 之后变成0
attention = attention.masked_fill(mask == 0, -1e10)
return F.softmax(attention, dim = 1)
通过代码我们可以看到 mask 通过参数传入到 Attention 中,然后在最后计算 softmax 之前将得到的 attention 与 mask 相乘。
BLEU 介绍
在自然语言翻译任务中,一种常用的评价方法就是使用blue,该方法也很简单,就是计算预测的句子的 n-grams 与实际的句子的 n-grams 有多少单词是重合的。比如A为我们预测的句子的 n-grams,B为实际翻译出来的句子的 n-grams, 那么\(blue = \frac{A \cap B}{B}\)
暂时完结 ✨⭐ ✨⭐ ✨⭐ 。
本文主要讲述的是使用 rnn 来进行自然语言的翻译,我们将会在下一篇 blog 中来讲述使用 cnn 来进行自然语言的繁育
代码下载
从bentrevett / pytorch-seq2seq 中提取出的代码如下:
👉️ 👉️ 👉️ 点击 💝 💝 💝 可以直接下载使用 LSTM 结构的seq2seq 模型的代码。将代码中 is_train = False 改成 is_train = True 就可以训练了,测试的时候再改回来即可。
👉️ 👉️ 👉️ 点击 💝 💝 💝 可以直接下载使用 GRU 结构的seq2seq 模型的代码。将代码中 is_train = False 改成 is_train = True 就可以训练了,测试的时候再改回来即可。
👉️ 👉️ 👉️ 点击 💝 💝 💝 可以直接下载使用 Attention 结构的seq2seq 模型的代码。将代码中 is_train = False 改成 is_train = True 就可以训练了,测试的时候再改回来即可。
👉️ 👉️ 👉️ 点击 💝 💝 💝 可以直接下载使用 Packed Padded Sequences ,Attention ,Masking 结构的seq2seq,并用 BLEU 评价模型的代码。将代码中 is_train = False 改成 is_train = True 就可以训练了,测试的时候再改回来即可。
更多参考资料来自于
- Towards Data Science - Attention — Seq2Seq Models
- Sequence to Sequence Learning with Neural Networks -Jay Alammar Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
本文由 louis 创作,采用 知识共享署名4.0 国际许可协议进行许可
github 地址 https://github.com/7568/7568.github.io
最后编辑时间为:2022-10-28