简介
在文本处理中有两个经典的网络模型,一个是基于循环神经网络加上 attention 的 Seq2Seq 和完全基于 attention 的 Transformer。这两个模型在机器翻译中都取得了很好的效果。 本文中很大一部分内容来自翻译 jalammar : The Illustrated Transformer , harvard : The Illustrated Transformer 和 bentrevett : Attention is All You Need 。
我们在上一篇文章 中讲述了 Seq2Seq with attention,也就是 Seq2seq Models With Attention 中的内容。
Transformer 论文地址在 Attention is All You Need. 。
模型结构
首先 Transformer 还是经典的 encoder ,decoder 模型,不一样的地方在于 Transformer 没有使用 rnn 和 cnn 而是使用一种叫 self-attention 的技术,该技术相对于 rnn的优势是 self-attention 可以并行运算,从而使得大规模计算得以进行。不再是后面的单词需要等前面的单词运行完,得到前一个单词的 hidden 之后,再进行后面的运算。相对于 cnn 的优势是它是可解释的, 能够直观的看到翻译结果是由哪些因素决定的。
Transformer 整体结构如下:
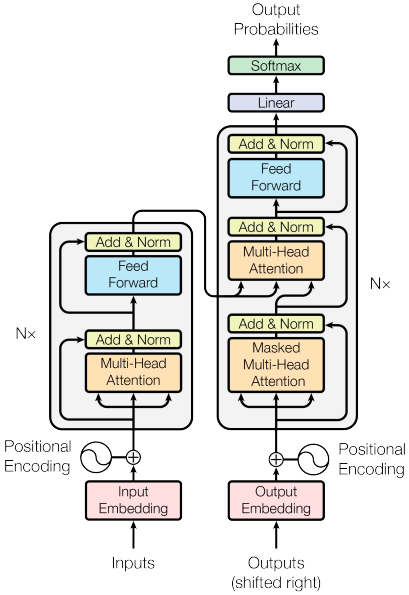
我们从高层次来看该模型的化就是这样,一个输入,一个黑盒,一个输出

当我们拆开黑盒,就会发现里面包含两个模块,分别是 encoders 和 decoders
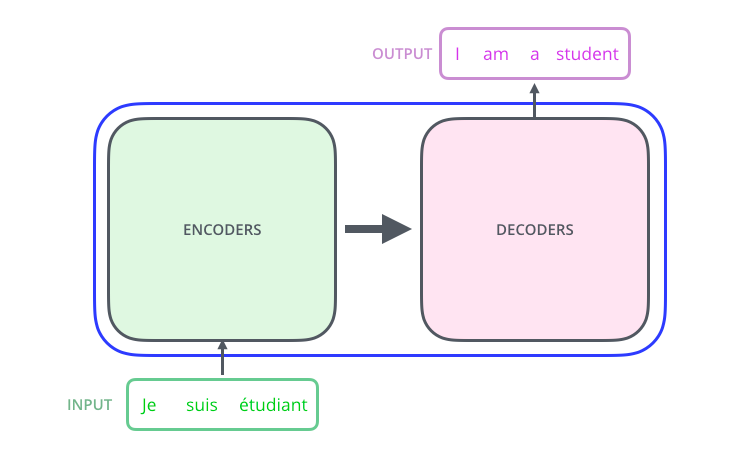
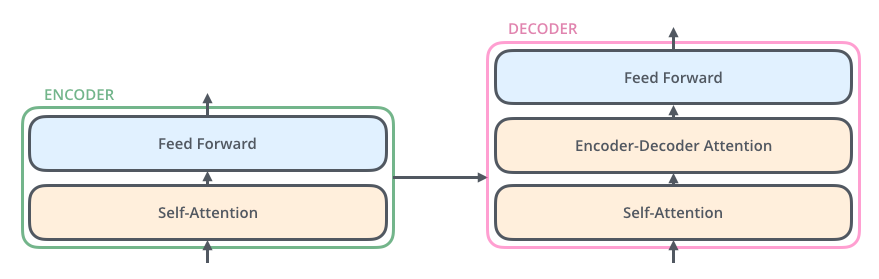
当我们继续探究黑盒,里面的 encoders 和 decoders ,我们就会发现,每一个 encoders 里面又包含有8个 encoder,decoders 里面也包含有8个 decoder。
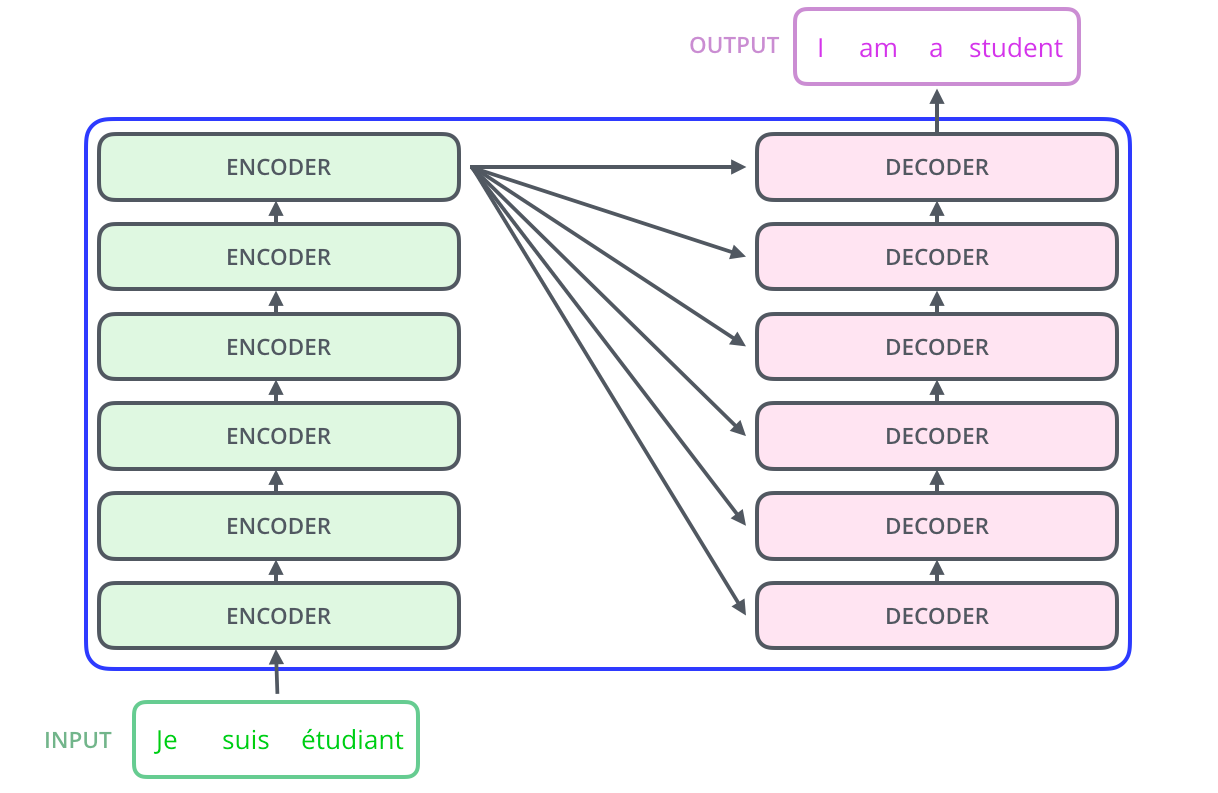
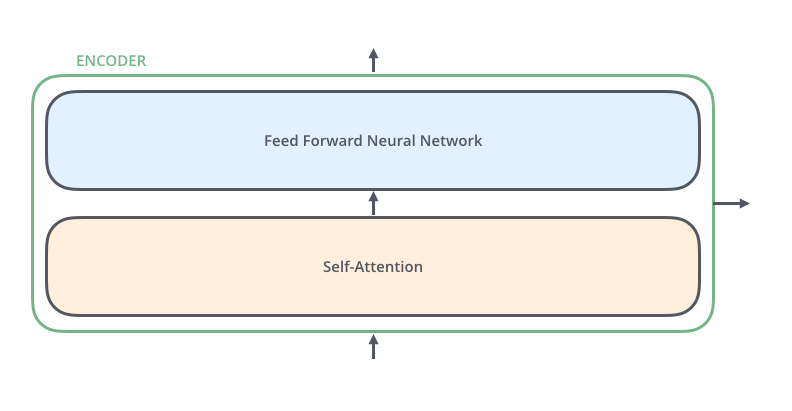
当我们继续探究每一个 encoder ,就可以看到,每一个 encoder 都有相同的结构,都是由两部分构成,分别是 feed-forward neural network 和 self-attention 。
然后我们查看 decoder,可以看到,每一个 decoder 也是都包含相同的结构,都是由三部分构成,分别是 feed-forward neural network,Encoder-Decoder Attention,和self-attention 。
运行过程
现在我们大概了解了 transformer 的整体结构,接下来我们来看一看一个句子是如何从输入一步一步到输出,从而研究 ecnoder 和decoder中的各个模块是如何工作的。
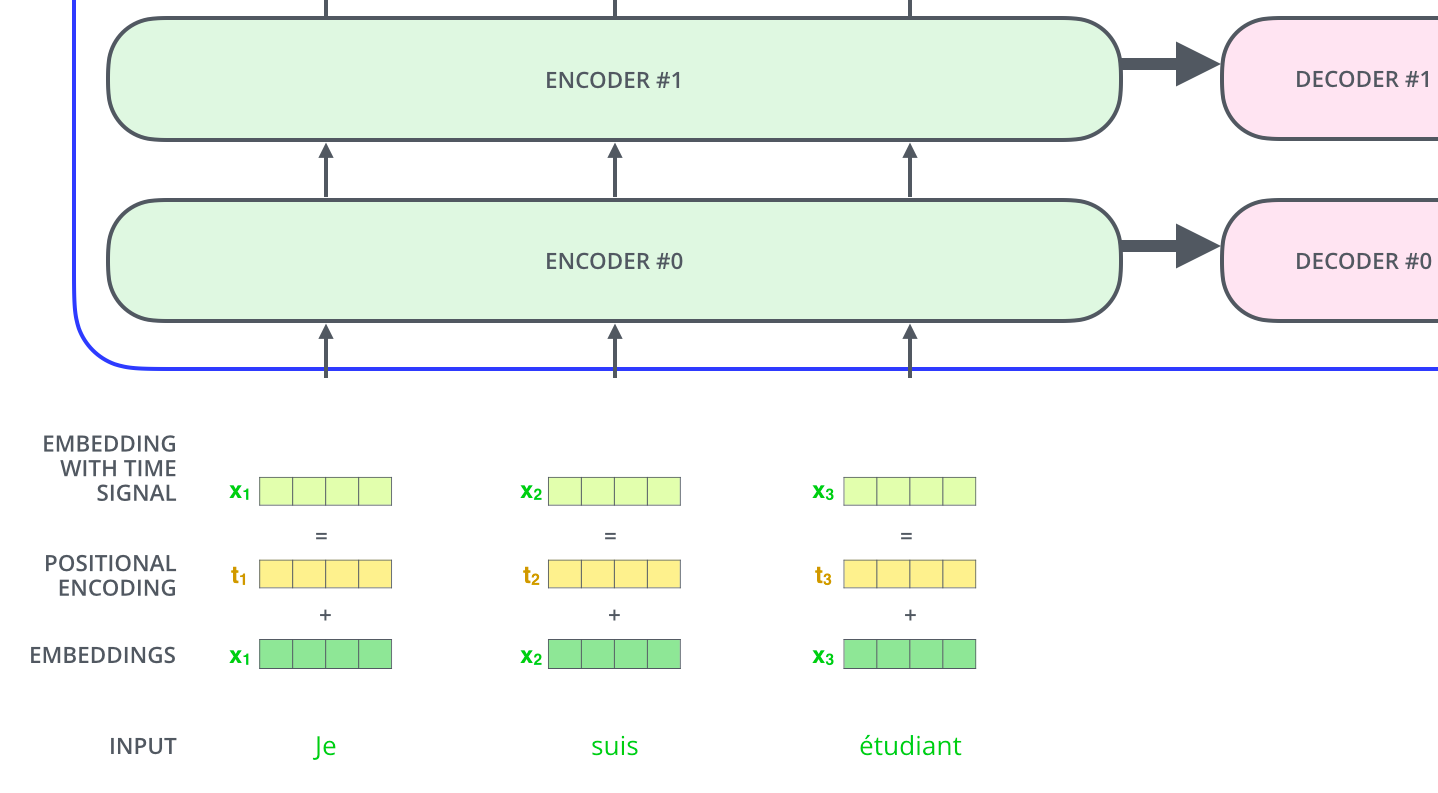
首先与常规的NPL处理一样,我们的输入都要经过 embedding 处理,将输入的每个单词变成向量。如下图所示

然后再放入到 encoder 里面,在一个 encoder 里面处理的流程如下:
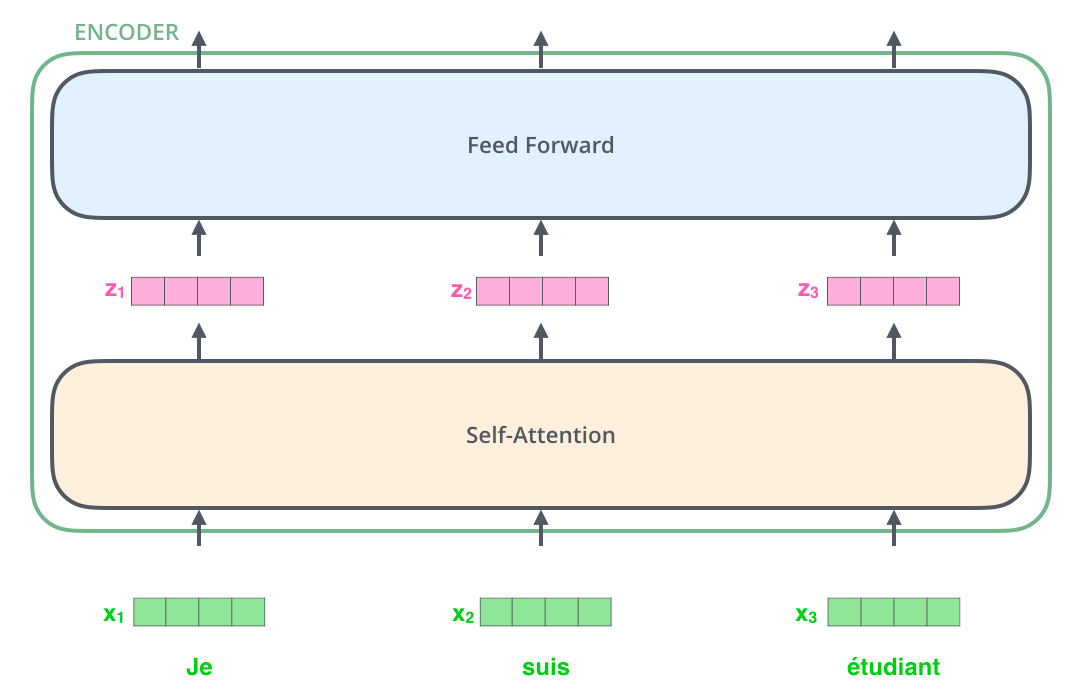
接下来我们就来解释不同的单词是如何在 self-attention 中被处理,得到输出的。
self-attention 介绍
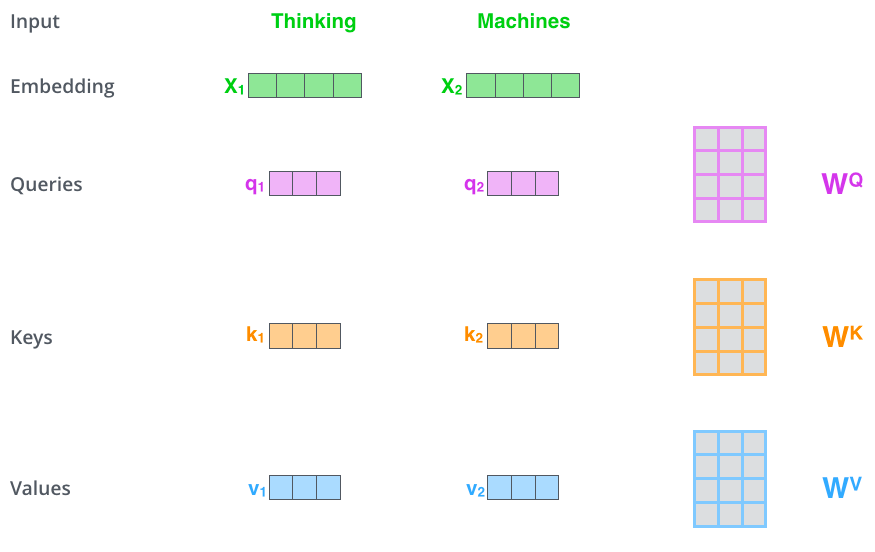
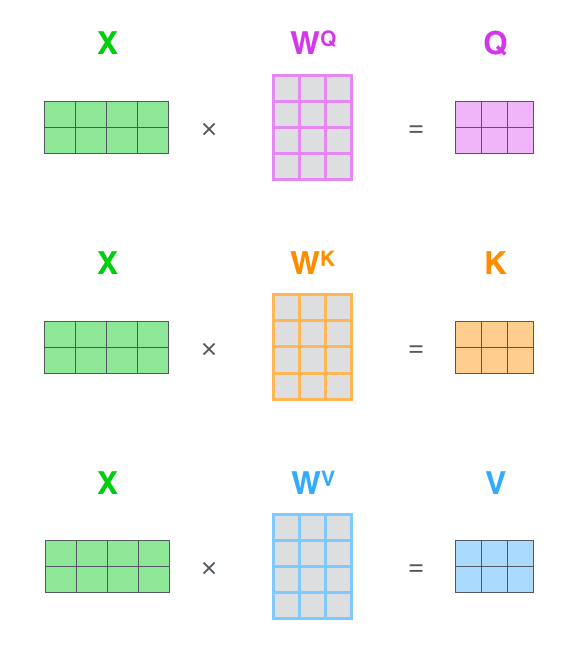
首先假设我们有两个单词,分别是 Thinking,和 Machines。在计算 self-attention 之前首先要进行 embedding 运算,得到 \(X_1 , X_2\) , 然后我们通过 \(X_1 , X_2\) 分别乘以矩阵\(W^Q\),\(W^K\),\(W^V\), 得到\(q_1 , q_2\),\(k_1 , k_2\),\(v_1 , v_2\) ,他们分别表示为Querys, keys,和Values。其中矩阵\(W^Q\) , \(W^K\) , \(W^V\)使用默认初始化数据,然后在训练过程中不断学习优化。整个过程如下图所示
当我们得到了不同单词的\(q\) , \(k\) , \(v\)之后,我们就可以进行 self-attention 计算了。比如我们要计算\(X_1\)的self-attention结果,我们的操作流程如下:
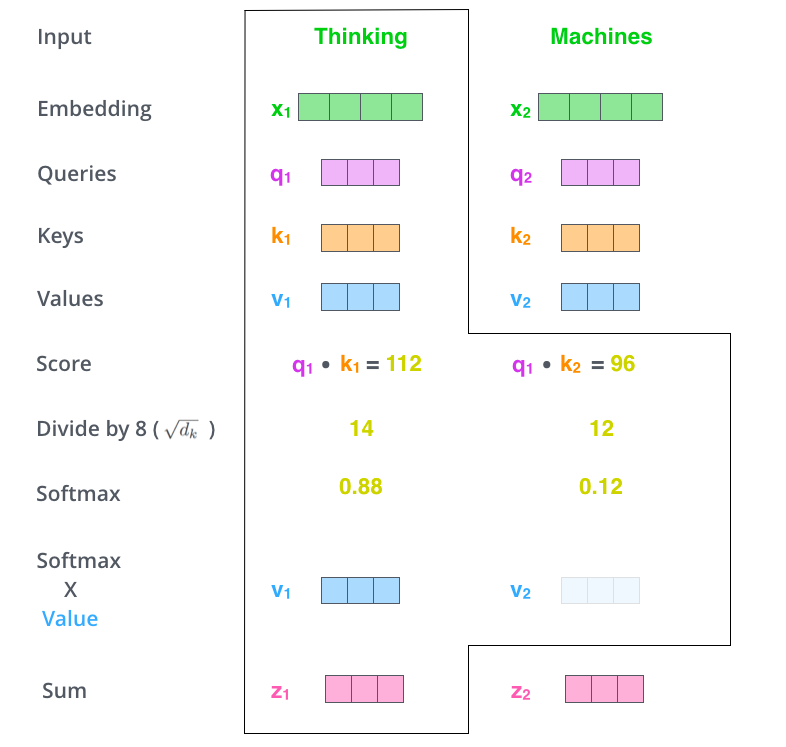
- 首先第一步就是计算得分,也就是图中的Score,Thinking 对自己的得分为\(q_1\) \(\times\) \(k_1^T\),Thinking 对 Machines 的得分为\(q_1\) \(\times\) \(k_2^T\),如果后面还有单词的化,计算得分为\(q_1\) \(\times\) \(k_i^T\)。
- 第二步将得分Score 除以 \(\sqrt{d_k}\),\(d_k\)为\(k\)的维度,此处假设为8。
- 第三步为将第二步的结果进行 softmax 操作。
- 第四步将 softmax 的结果乘以各自的 Values,得到新的向量。
- 第五步将第四步的结果全部进行向量相加,得到一个新的向量\(z_1\),这个\(z_1\)就是 Thinking 经过 self-attention 运算的结果。
- 当我们计算 Machines 的 self-attention 运算结果的时候,与 Thinking 流程是一样的,只是在计算 Score 的时候,使用的是\(q_2\)分别乘以\(k_1 , k_2 , ... , k_i\),来计算Thinking相对于各个单词的Score。剩下的流程其实是一样的。
我们可以把上面的步骤转换成矩阵乘法运算,比如我们通过 \(X\) 计算\(W^Q\) , \(W^K\) , \(W^V\),我们就可以通过下面的方式得到。
因为卷积运算其实也是矩阵乘法, 所以其实这一步也可以理解成一个特殊卷积核的卷积操作。
于是我们的整个self-attention就可以描述成如下的运算。
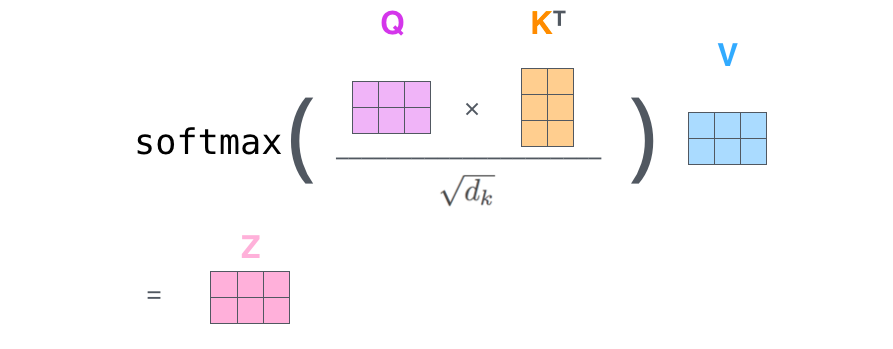
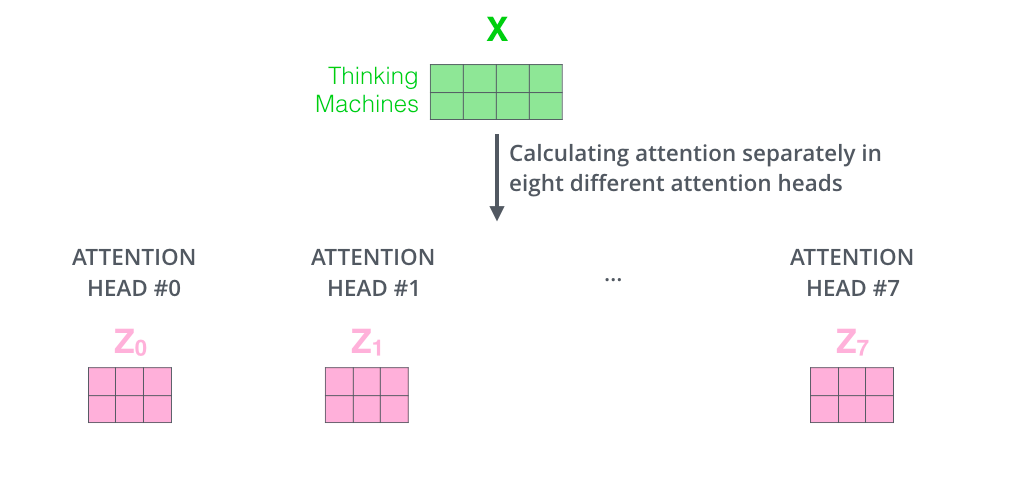
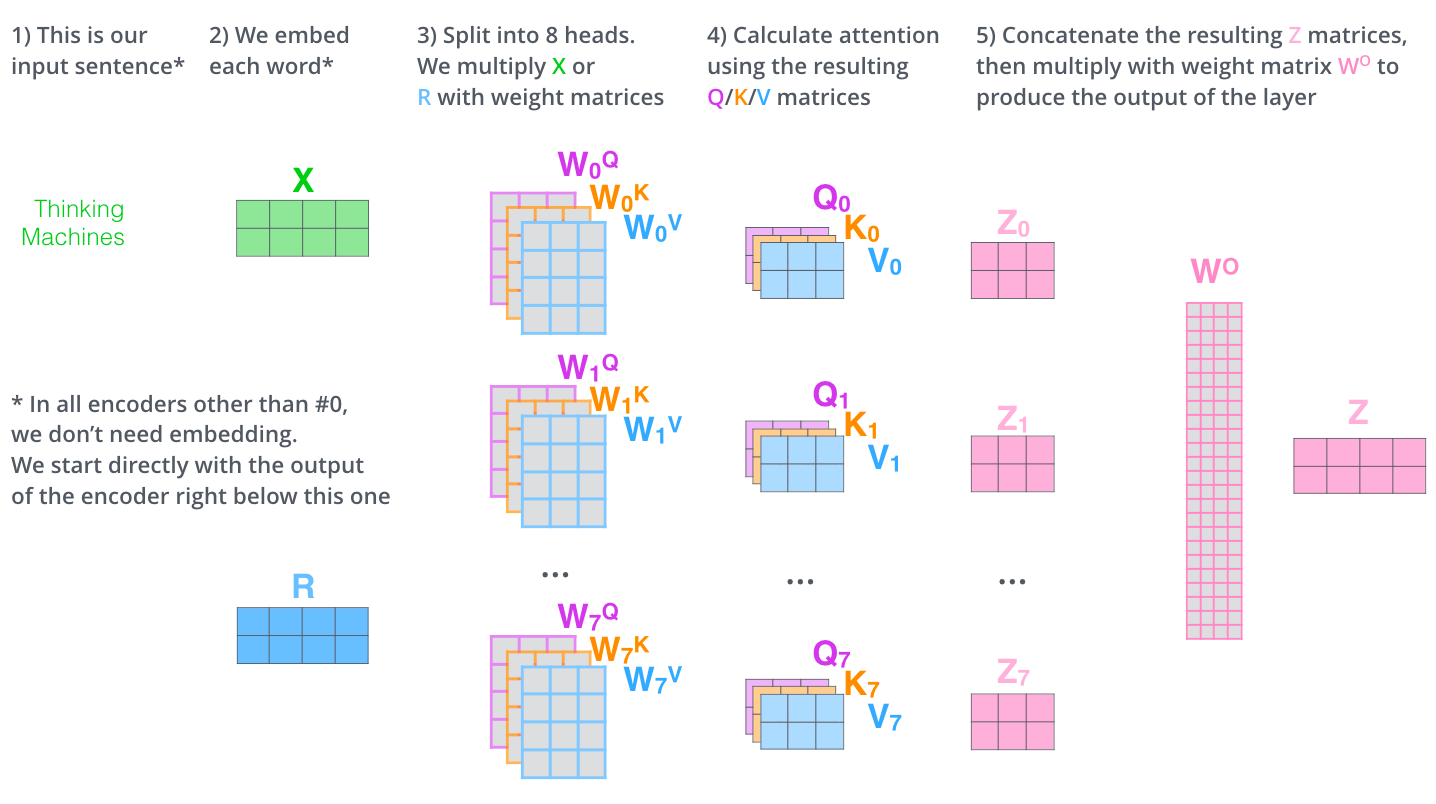
多头注意力机制
在论文Attention is All You Need. 中作者使用的是多头注意力机制。当我们知道了self-attention机制之后,再来理解多头注意力机制就很简单了。
在self-attention中我们使用的是上图的方法得到某一个单词的self-attention的结果,那多头self-attention就是对某一个单词的embedding结果 \(X\) 使用多个不同的\(W^Q\) , \(W^K\) , \(W^V\)来
分别计算得到 \(X\) 的多个self-attention结果,然后将这些结果拼接起来,再进行一次卷积操作,得到的结果作为最终的 \(X\) 对应的\(Z\)
如下图所示,对 \(X\) 计算8个self-attention
然后我们把8个self-attention结果拼接起来,然后一起乘以一个矩阵 \(W_O\) 最终得到输出\(Z\),如下图所示
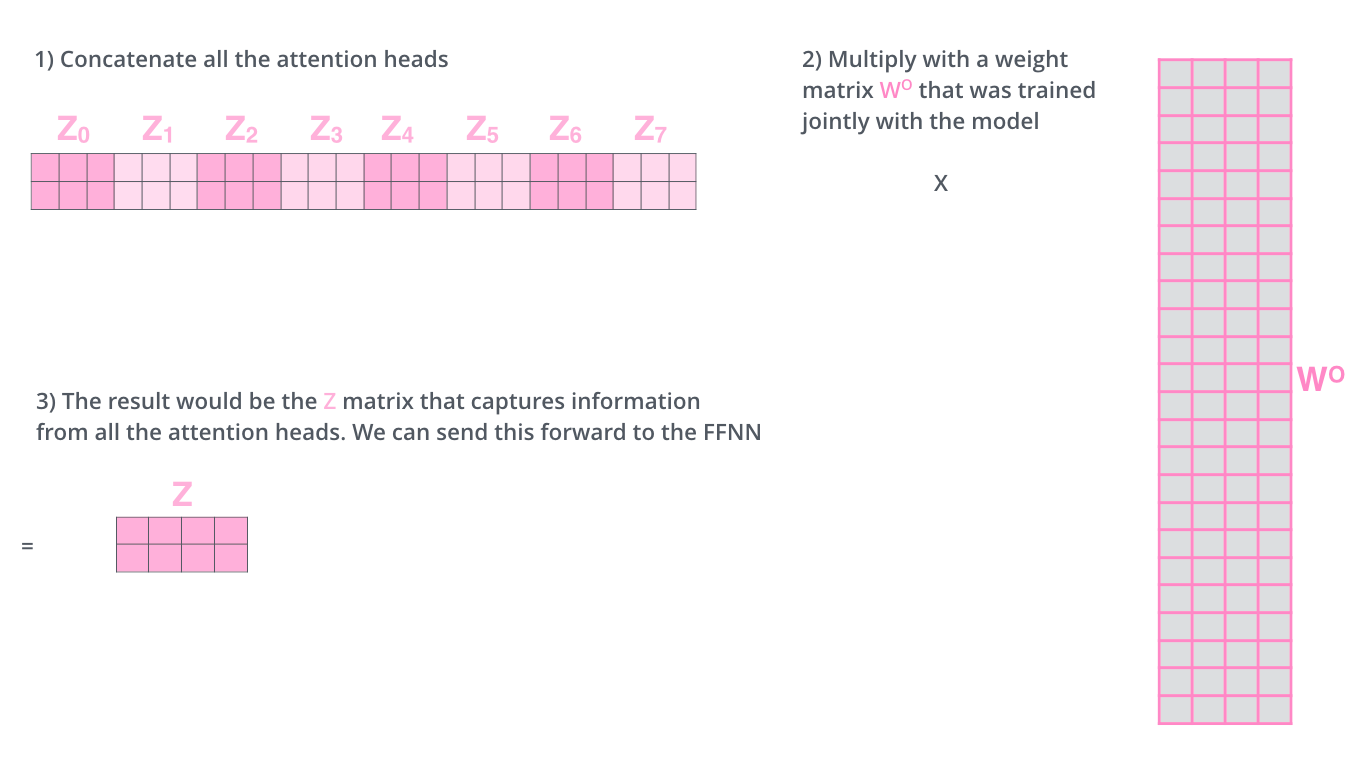
于是乎整个过程可以描述成如下所示。在下图中多了一个\(R\),你可以把它想像成上一个encoder的输出,同时也是下一个encoder的输入。
同时在整个encoders中只有第一个encoder的输入是需要进行embedding操作的,后面的都不需要。
注意力理解
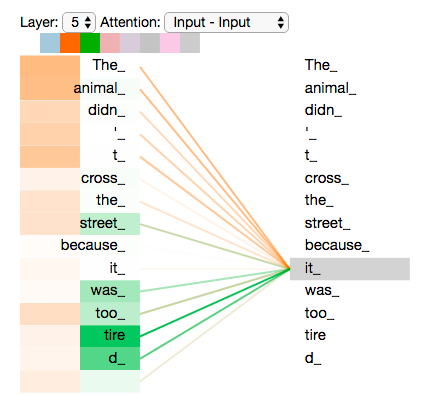
接下来我们看看注意力机制最终达到的目的是哈。比如我们的输入是 The animal didn’t cross the street because it was too tired ,我们想要知道其中的it表示的是啥。
对于我们人类来说这个问题太简单了,但是对于机器来说确是很难。当我们有了self-attention之后,机器这个问题看上去就有了一些转机。下图是我们的self-attention的效果图。

图中连线越粗表示相关性越强,我们可以看到,it与The animal的相关性是最强的。
在多头注意力multi-headed-attention中,我们的 it 相对与每一个不同的self-attention,它要表达的东西不一样,比如下图所示有两个self-attention,对于it连线最粗的分别是The animal和tired,
虽然虽然每一个self-attention最终的侧重点不一样,但是我们可以理解成不同的self-attention表示的联系不一样,比如it虽然表示的不是tired,但是it显然是与tired有关的。
或者我们可以将它理解成高维的联系。如下图所示
位置编码
在self-attention中,所有的操作都是矩阵乘法,所以我们可以将self-attention理解成特殊的卷积操作,而且是不分顺序的,这与我们在使用之前介绍的卷积网络进行文本翻译 来操作文本翻译一样,都需要有个位置编码来区分相同的单词由于出现的位置不一样,导致句子的意思不一样的情况。
在卷积网络进行文本翻译 中,我们的位置编码直接使用的是顺序编码,也就是说按照句子的长度,从0开始,依次编码,位置在第0位位置编码就是0,在第1位,位置编码就是1,依次往后。
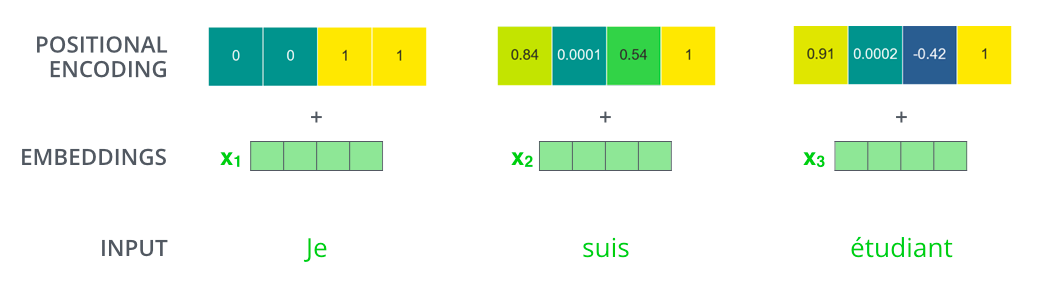
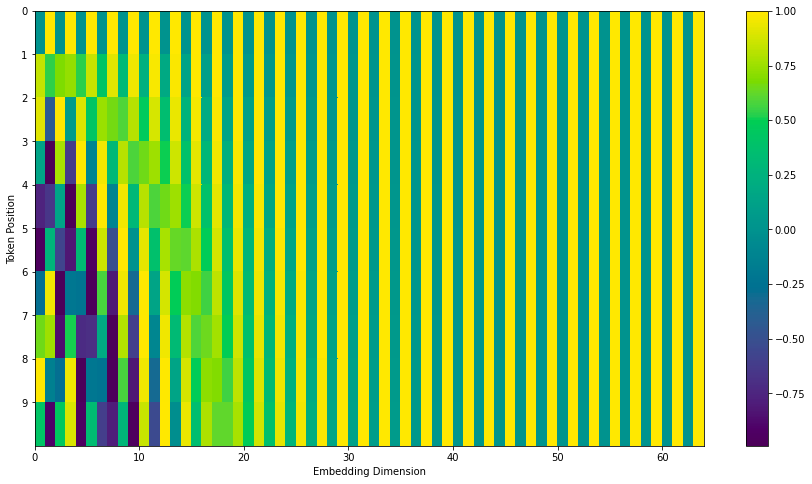
但是在我们的论文Attention is All You Need. 中作者提使用了一个新的位置编码的方式,具体就是使用某个方法,生成一组向量,每个向量就表示一个位置。效果如下图所示。
比如我们的位置编码向量的长度为4,对于不同的位置,效果如下图所示。
接下来我们来看看向量长度为512,句子长度为20的一个位置编码的效果图。每一行就表示一个单词的位置向量。
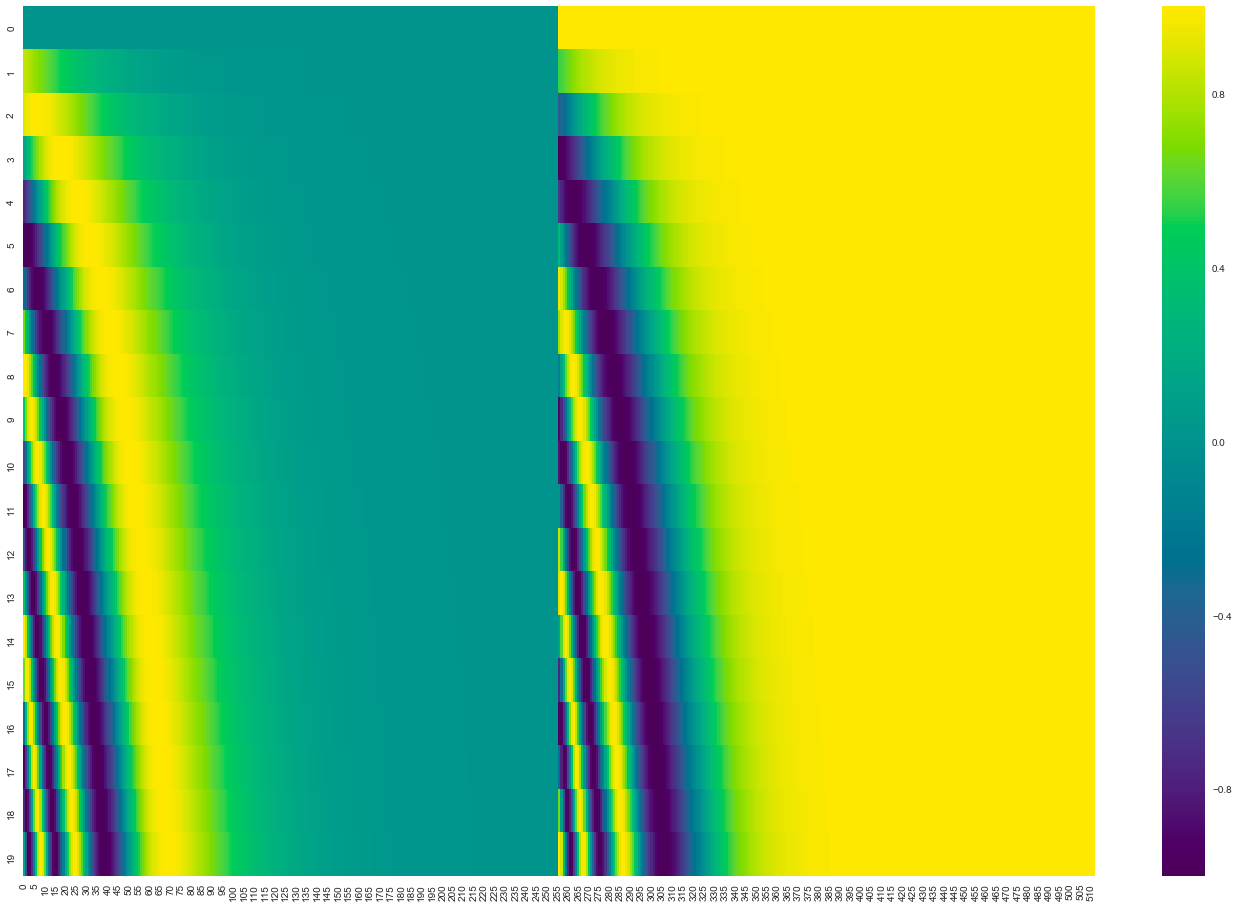
在很多地方我们也可以看到如下的位置编码效果图,其实该效果图与上面的效果图差别不是很大,只是下面的效果图加上了 interweaves 操作,其实就是对奇数位置和偶数位置分别再用sin和cos进行运算一次。
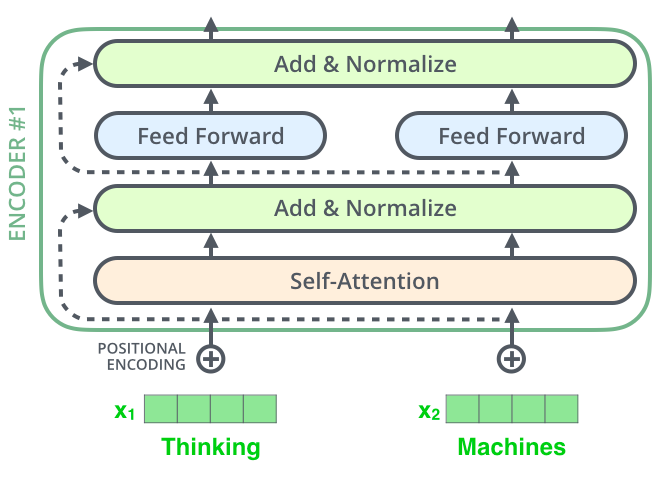
残差块
接下来我们再来看看每一个encoder内部的结构,如下:
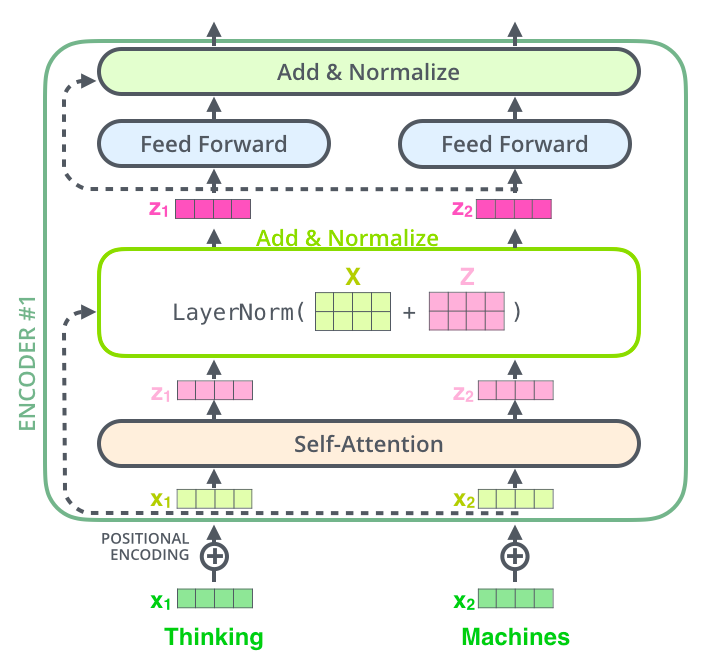
当我们的X经过了self-attention之后,会进入到一个Add&Normalize的层,Add操作是指将self-attention的输出\(z_1,z_2, ... , z_i\)拼接起来,然后再
与输入\(x_1,x_2,...,x_i\)进行相加,这一套操作也称为残差操作。然后将残差的结果进行LayerNorm运算,得到新的\(z_1,z_2, ... , z_i\)。之后我们将\(z_1,z_2, ... , z_i\)当作新的输入,
传入到一个前馈神经网络中,然后再进行一次残差操作,与LayerNorm操作。我们将这两次残差操作合称为一个残差块。于是一个encoder就是一个残差块,效果如下图所示
接下来我们再来看看decoders中的内容,发现其实与encoders中的内容是一样的,整体结构如下 ![encoder-architecture-3]
跟在卷积网络进行文本翻译 中一样,我们最关心的还是在实际中,decoder是如何一步步生成翻译结果的。 下面的动画就很好的解释了翻译的decoder的全过程
也就是说在我们训练的时候,我们的decoders只是从下到上运行一次,一次加载所有的输入,然后一次性的得到结果。而在我们实际翻译的时候,由于我们实际的答案是不能再当作输入的,或者我们此时根本就没有翻译的答案,这个时候decoders就会运行多次,比如翻译的结果句子长度为10,那么decoders就会运行12次,因为从开始符号一直要运行到结束符为止。
比如我们的翻译的结果为“I am a student”,那么我们在decoders中,第一次的输入是 ”<sos>”,经过decoders之后得到 “I”,然后将 ”<sos> I”一起当作输入,放入到decoders中,得到 “am” 然后再将 ”<sos> I am” 当作输入放入到decoders中,得到结果 “a” 依次类推下去,一直到得到结束符 ”<eos>” 为止。 最终得到的翻译结果为”<sos> I am a student <eos>”
代码分析
由于本章内容过多,已将代码分析放于 💝 此处 💝
更多参考来自于
- graykode / nlp-tutorial
- Transformers: Attention in Disguise
- The Illustrated Transformer
- The Annotated Transformer
本文由 louis 创作,采用 知识共享署名4.0 国际许可协议进行许可
github 地址 https://github.com/7568/7568.github.io
最后编辑时间为:2022-10-28