简介
在💝 上一篇blog 💝 中我们讲述了使用rnn来进行自然语言的翻译工作,限于篇幅的原因,我们将会在本blog来讲述使用 cnn 进行自然语言的翻译工作。我们将会在💝 下一篇 💝 进行 Transformer 的讲解。
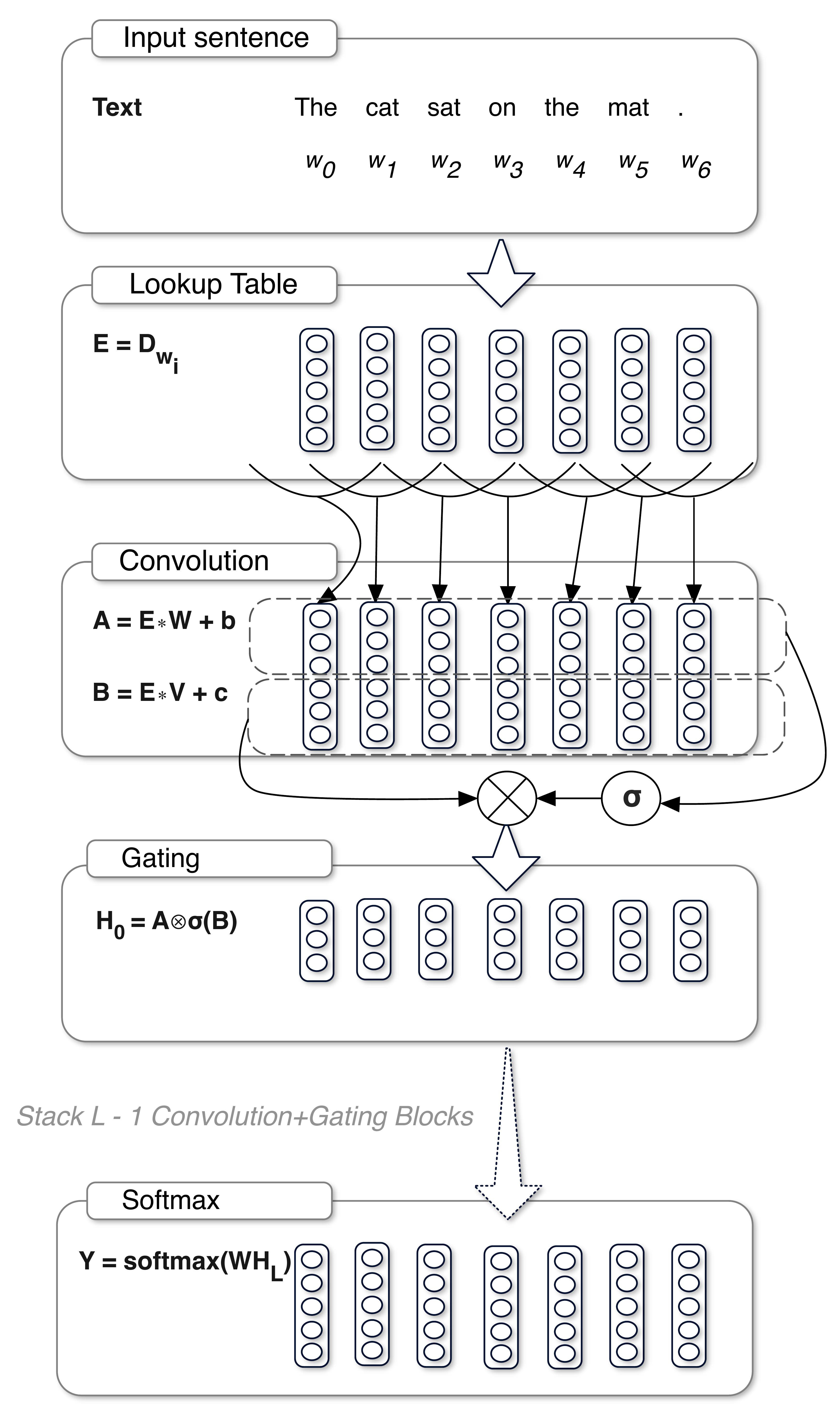
本文我们将会在本blog中实现 Convolutional Sequence to Sequence Learning 论文中的方法。该方法与我们的之前的方法完全不一样,在之前的方法中我们 使用的都是自然语言处理中常用的循环神经网络rnn,而本文使用的是通常使用在图像处理中任务中的卷积神经网络cnn。不过与通常在图像中使用的cnn不同的是,在图像中cnn的卷积核通常 是带有宽度和高度的,但是在文本处理任务中的cnn卷积核只有长度,没有高度。在💝 此处 💝 有关于cnn的介绍。
准备数据
首先我们还是准备数据,该部分与 💝 之前 💝 的内容一致,就不做过多讲解。
模型介绍
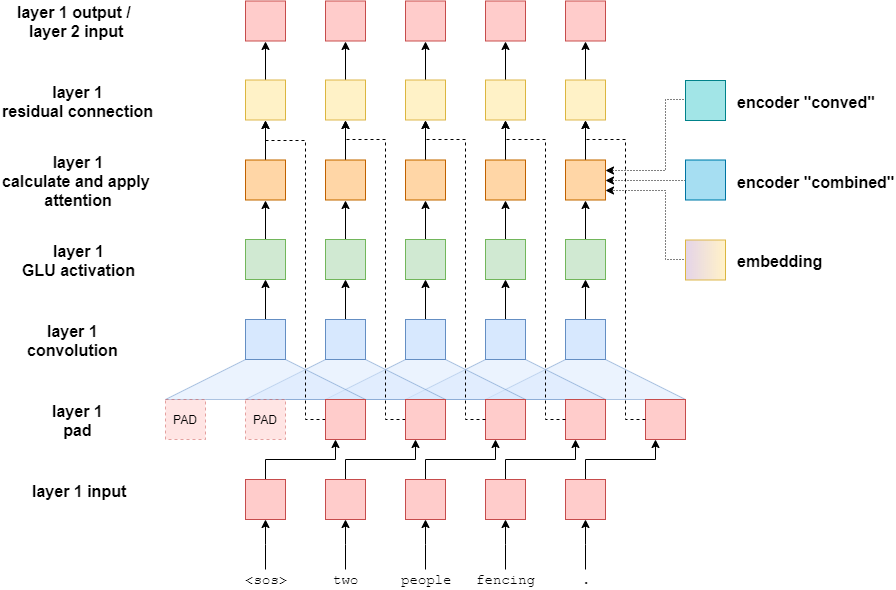
使用cnn进行文本翻译工作,我们的模型还是分成 encoder 和 decoder 两部分,结构如下图所示。
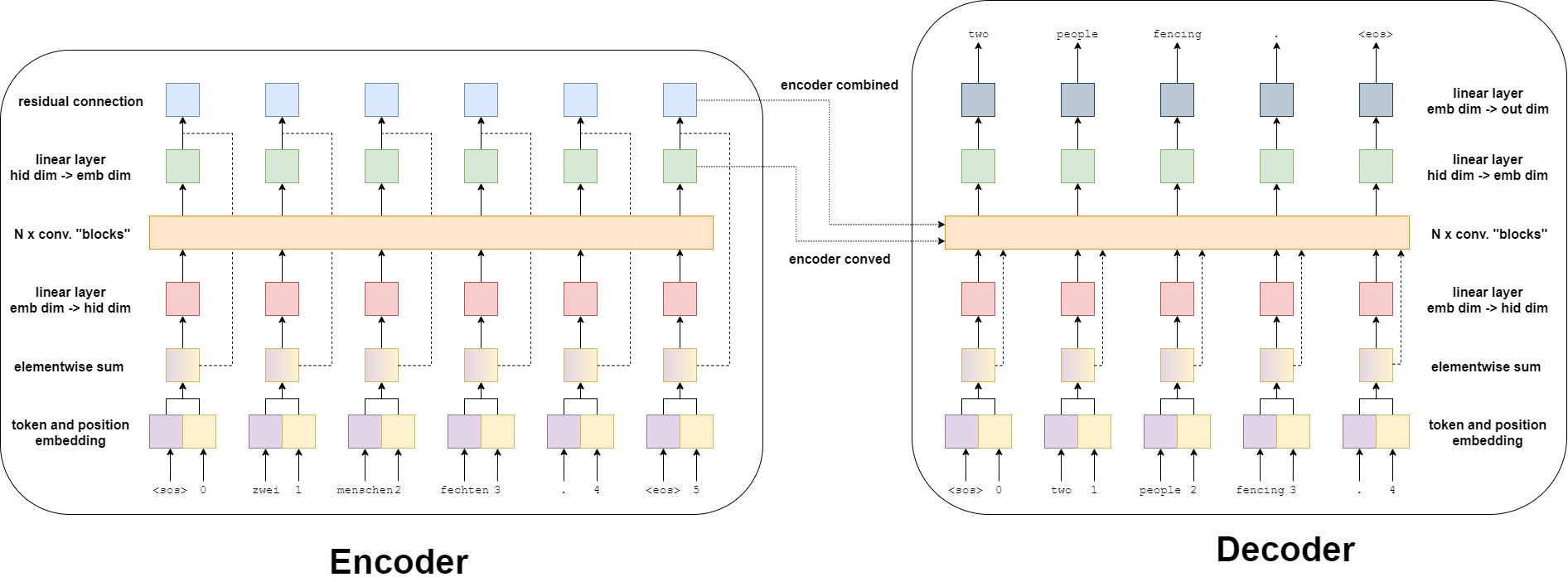
encoder
我们先来看看 encoder 的结构
我们可以看到在 encoder 中有一个很大的特点就是位置的操作,之前我们的rnn中都没有位置编码,是因为rnn天然就有先后顺序,而cnn没有, 而我们自然语言是有顺序的,相同的单词可能会因为顺序的不一样,组成的句子的意思可能会完全不一样。所以在cnn中需要对输入进行位置编码。
在 encoder 中我们的输入分为6个部分:
- 将输入进行token化,就是将字符转换成数字。再拼接上位置编码
- 将位置编码与token进行逐点相加,得到带位置属性的token
- 将上一步的结果进行全连接操作
- 将上一步的结果进行卷积操作,得到第一个结果,为卷积层的输出 “conved output”
- 将上一步的结果与第二步的结果进行逐点相加,得到第二个结果,称为 “combined output”
在 rnn 中我们的 encoder 只会有一个结果传到 decoder 中,而在 cnn 中我们有两个结果,分别是”conved output”和”combined output”,都会作为参数传到 decoder 中去。
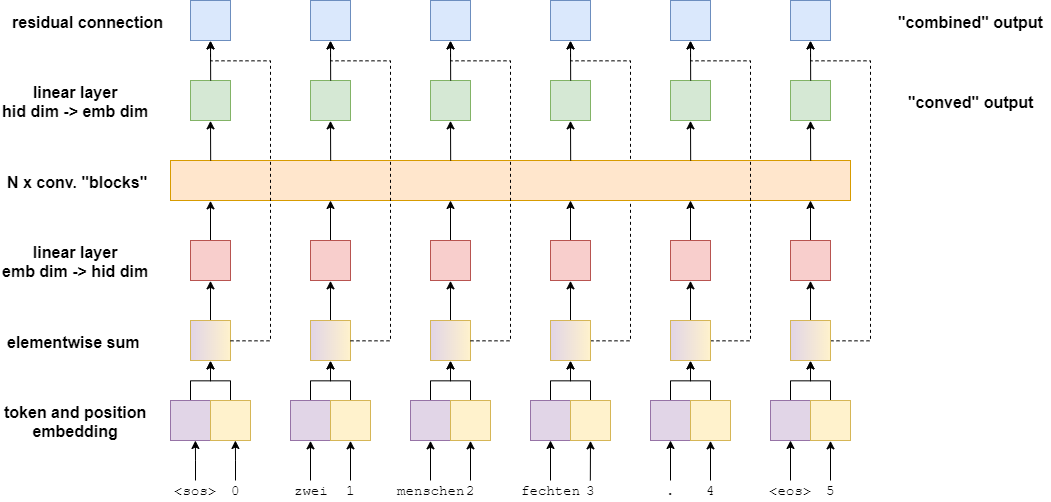
在上面我们描述的是只有一层 cnn 的网络,如果想有多层,其中一个简单的方法是直接在第4步加上多层网络,本文将介绍一个带残差块的 cnn 网络模型,结构如下图所示:
GLU
在上图中绿色的方块表示 gated linear units (GLU) 外加激活函数,该操作也是跟 GRU 和 LSTM 一样,带有门控单元,是一种带门控的网络结构。GLU 可用数学表达式为
\[GLU(a,b) = a \otimes \sigma(b)\]在神经网络中使用如下图所示,看上去与残差网络类似
下面是 encoder 的代码
class Encoder(nn.Module):
def __init__(self,
input_dim,
emb_dim,
hid_dim,
n_layers,
kernel_size,
dropout,
device,
max_length = 100):
super().__init__()
assert kernel_size % 2 == 1, "Kernel size must be odd!"
self.device = device
self.scale = torch.sqrt(torch.FloatTensor([0.5])).to(device)
self.tok_embedding = nn.Embedding(input_dim, emb_dim)
self.pos_embedding = nn.Embedding(max_length, emb_dim)
self.emb2hid = nn.Linear(emb_dim, hid_dim)
self.hid2emb = nn.Linear(hid_dim, emb_dim)
self.convs = nn.ModuleList([nn.Conv1d(in_channels = hid_dim,
out_channels = 2 * hid_dim,
kernel_size = kernel_size,
padding = (kernel_size - 1) // 2)
for _ in range(n_layers)])
self.dropout = nn.Dropout(dropout)
def forward(self, src):
#src = [batch size, src len]
batch_size = src.shape[0]
src_len = src.shape[1]
#create position tensor
pos = torch.arange(0, src_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
#pos = [0, 1, 2, 3, ..., src_len - 1]
#pos = [batch_size, src_len]
#embed tokens and positions
tok_embedded = self.tok_embedding(src)
pos_embedded = self.pos_embedding(pos)
#tok_embedded = pos_embedded = [batch size, src len, emb dim]
#combine embeddings by elementwise summing
embedded = self.dropout(tok_embedded + pos_embedded)
#embedded = [batch size, src len, emb dim]
#pass embedded through linear layer to convert from emb dim to hid dim
conv_input = self.emb2hid(embedded)
#conv_input = [batch size, src len, hid dim]
#permute for convolutional layer
# 将1,2维度对调,相当于将矩阵转置
# torch.equal(conv_input[0].permute(1,0), conv_input[0].t()) 为 True,故由此判断
conv_input = conv_input.permute(0, 2, 1)
#conv_input = [batch size, hid dim, src len]
#begin convolutional blocks...
for i, conv in enumerate(self.convs):
#pass through convolutional layer
conved = conv(self.dropout(conv_input))
#conved = [batch size, 2 * hid dim, src len]
#pass through GLU activation function
conved = F.glu(conved, dim = 1)
#conved = [batch size, hid dim, src len]
#apply residual connection
conved = (conved + conv_input) * self.scale
#conved = [batch size, hid dim, src len]
#set conv_input to conved for next loop iteration
conv_input = conved
#...end convolutional blocks
#permute and convert back to emb dim
conved = self.hid2emb(conved.permute(0, 2, 1))
#conved = [batch size, src len, emb dim]
#elementwise sum output (conved) and input (embedded) to be used for attention
combined = (conved + embedded) * self.scale
#combined = [batch size, src len, emb dim]
return conved, combined
整个过程大概就是embedding加残差,至于为什么要有 self.scale 暂时还不清楚,也不清楚选择不同的 self.scale 的值对模型性能是否有影响,目前选择的是根号5。
decoder
在训练过程中的 decoder 与 encoder 很相似,但是在 decoder 中,卷积的地方不仅要接收上一层网络传过来的数据,还要接收从上上一层跳跃连接过来的数据和 encoder 中输出的两个参数。
训练过程如下图所示:
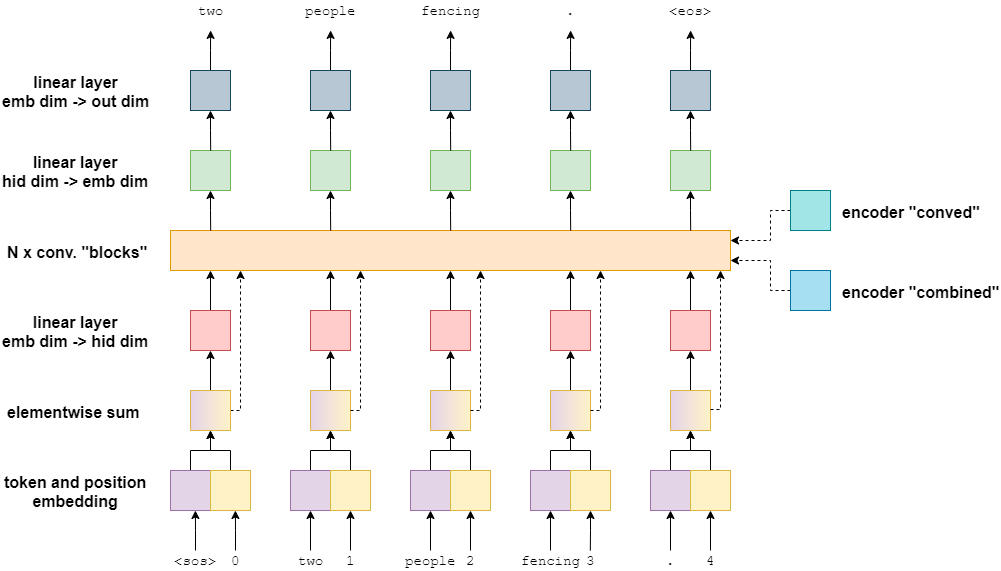
从图中我们可以看到,cnn层共接收了4个参数。下图是卷积层拆开之后的样子。
下面是代码
class Decoder(nn.Module):
def __init__(self,
output_dim,
emb_dim,
hid_dim,
n_layers,
kernel_size,
dropout,
trg_pad_idx,
device,
max_length = 100):
super().__init__()
self.kernel_size = kernel_size
self.trg_pad_idx = trg_pad_idx
self.device = device
self.scale = torch.sqrt(torch.FloatTensor([0.5])).to(device)
self.tok_embedding = nn.Embedding(output_dim, emb_dim)
self.pos_embedding = nn.Embedding(max_length, emb_dim)
self.emb2hid = nn.Linear(emb_dim, hid_dim)
self.hid2emb = nn.Linear(hid_dim, emb_dim)
self.attn_hid2emb = nn.Linear(hid_dim, emb_dim)
self.attn_emb2hid = nn.Linear(emb_dim, hid_dim)
self.fc_out = nn.Linear(emb_dim, output_dim)
self.convs = nn.ModuleList([nn.Conv1d(in_channels = hid_dim,
out_channels = 2 * hid_dim,
kernel_size = kernel_size)
for _ in range(n_layers)])
self.dropout = nn.Dropout(dropout)
def calculate_attention(self, embedded, conved, encoder_conved, encoder_combined):
#embedded = [batch size, trg len, emb dim]
#conved = [batch size, hid dim, trg len]
#encoder_conved = encoder_combined = [batch size, src len, emb dim]
#permute and convert back to emb dim
conved_emb = self.attn_hid2emb(conved.permute(0, 2, 1))
#conved_emb = [batch size, trg len, emb dim]
combined = (conved_emb + embedded) * self.scale
#combined = [batch size, trg len, emb dim]
energy = torch.matmul(combined, encoder_conved.permute(0, 2, 1))
#energy = [batch size, trg len, src len]
attention = F.softmax(energy, dim=2)
#attention = [batch size, trg len, src len]
attended_encoding = torch.matmul(attention, encoder_combined)
#attended_encoding = [batch size, trg len, emd dim]
#convert from emb dim -> hid dim
attended_encoding = self.attn_emb2hid(attended_encoding)
#attended_encoding = [batch size, trg len, hid dim]
#apply residual connection
attended_combined = (conved + attended_encoding.permute(0, 2, 1)) * self.scale
#attended_combined = [batch size, hid dim, trg len]
return attention, attended_combined
def forward(self, trg, encoder_conved, encoder_combined):
#trg = [batch size, trg len]
#encoder_conved = encoder_combined = [batch size, src len, emb dim]
batch_size = trg.shape[0]
trg_len = trg.shape[1]
#create position tensor
pos = torch.arange(0, trg_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
#pos = [batch size, trg len]
#embed tokens and positions
tok_embedded = self.tok_embedding(trg)
pos_embedded = self.pos_embedding(pos)
#tok_embedded = [batch size, trg len, emb dim]
#pos_embedded = [batch size, trg len, emb dim]
#combine embeddings by elementwise summing
embedded = self.dropout(tok_embedded + pos_embedded)
#embedded = [batch size, trg len, emb dim]
#pass embedded through linear layer to go through emb dim -> hid dim
conv_input = self.emb2hid(embedded)
#conv_input = [batch size, trg len, hid dim]
#permute for convolutional layer
conv_input = conv_input.permute(0, 2, 1)
#conv_input = [batch size, hid dim, trg len]
batch_size = conv_input.shape[0]
hid_dim = conv_input.shape[1]
for i, conv in enumerate(self.convs):
#apply dropout
conv_input = self.dropout(conv_input)
#need to pad so decoder can't "cheat"
padding = torch.zeros(batch_size,
hid_dim,
self.kernel_size - 1).fill_(self.trg_pad_idx).to(self.device)
padded_conv_input = torch.cat((padding, conv_input), dim = 2)
#padded_conv_input = [batch size, hid dim, trg len + kernel size - 1]
#pass through convolutional layer
conved = conv(padded_conv_input)
#conved = [batch size, 2 * hid dim, trg len]
#pass through GLU activation function
conved = F.glu(conved, dim = 1)
#conved = [batch size, hid dim, trg len]
#calculate attention
attention, conved = self.calculate_attention(embedded,
conved,
encoder_conved,
encoder_combined)
#attention = [batch size, trg len, src len]
#apply residual connection
conved = (conved + conv_input) * self.scale
#conved = [batch size, hid dim, trg len]
#set conv_input to conved for next loop iteration
conv_input = conved
conved = self.hid2emb(conved.permute(0, 2, 1))
#conved = [batch size, trg len, emb dim]
output = self.fc_out(self.dropout(conved))
#output = [batch size, trg len, output dim]
return output, attention
在 decoder 中比 encoder 中多了一个 calculate_attention 方法,该方法接收4个参数,输出两结果,其中一个是attention。
接下来就是训练代码,与之前的并无差别。
在测试的时候,我们 decoder 的输入需要做一些修改。在 rnn 结构的网络中,我们的 decoder 的输入(即训练时候的目标翻译结果)可以根据起始标志来依次往后, 得到翻译的预测,但是在 cnn 中却不能这样做,需要一次性输入整个目标结果,但是目标结果是不知道的。
通过分析代码,我们可以知道,cnn 网络的文本翻译与 rnn 网络的文本翻译,他们在 decoder 的时候,输入都是第一个开始字符,那 cnn 是如何进行卷积操作的呢? 答案就是通过 embedding 操作实现的。这也解释了为什么在 cnn 网络中为什么有那么多的 embedding 操作,embedding 操作能将任意长度的输入变成相同维度的输出, 从而保证了后面的计算维度合适。妙啊!
代码下载
从bentrevett / pytorch-seq2seq 中提取出的代码如下:
👉️ 👉️ 👉️ 点击 💝 💝 💝 可以直接下载使用 rnn 结构的 seq2seq 模型的代码 。将代码中 is_train = False 改成 is_train = True 就可以训练了,测试的时候再改回来即可。
更多参考资料来自于
- Towards Data Science - Attention — Seq2Seq Models
- Sequence to Sequence Learning with Neural Networks -Jay Alammar Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
本文由 louis 创作,采用 知识共享署名4.0 国际许可协议进行许可
github 地址 https://github.com/7568/7568.github.io
最后编辑时间为:2022-10-28