简介
TabNet 是2020年 Google Cloud AI 团队发表的一篇用来处理表格数据的深度神经网络模型,它可解释性强而且使用到了自监督技术,本文将 通过💝 💝 💝 论文 💝 💝 💝 和💝 💝 💝 代码 💝 💝 💝(非官方) 来对 TabNet 进行介绍。
论文介绍
对于处理 tabular 类型的数据,目前使用基于树结构的集成学习框架会有很好的效果。例如 💝 LightGBM 💝 和 💝 XDBoost 💝 在众多 tabular 类型的数据处理任务中都有精彩的表现。 但是 TabNet 有自己的优点,而且在很多任务中效果并不比它们差。
TabNet 优点如下:
- 方便使用,对原始数据不需要做任何其他的操作,就能直接使用,而且 TabNet 是端对端的,训练起来非常方便。
- TabNet 使用 attention 机制,使得模型的解释性强。
- TabNet 效果好,并且有两种不同的可解释性,一个是局部可解释性,一个是全局可解释性。
- 对于第一次遇见的 tabular 类型的数据,我们使用非监督填词游戏的方式对模型进行预训练,使得模型在该数据上能有很好的表现。
所谓非监督填词游戏就是把样本数据随机的选择一些属性置为空,然后让网络来进行预测学习。当网络对该数据的填词游已经处理得 很好之后,然后再来进行对该数据的实际任务的微调训练,从而提高网络在实际任务上的性能。通常我们可以把这种预训练好的模型 当作整个网络的 embedding 层。
下图展示了 TabNet 的整体结构
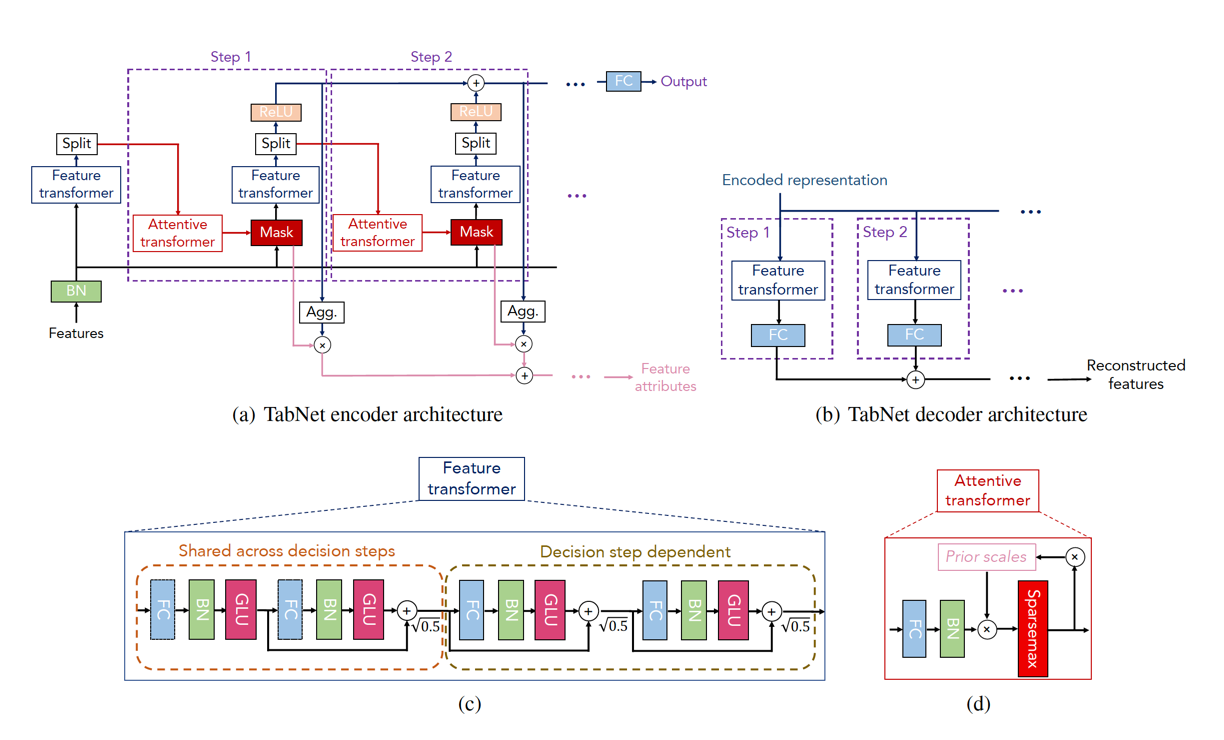
整体分为 encoder 和 decoder 两部分,在 encoder 中有三个特殊的结构,分别为 feature transformer,attentive transformer和 feature masking,其中 feature transformer 是 用来进行特征提取,attentive transformer 是用来进行特征选择,和提供对模型的可解释性,而 feature masking 是用来获取全局特征重要性的分布。 图中的(a)是 encoder 结构,(b)是 decoder 结构,(c)是 feature transformer,里面可以分成4层,每一层都是由 FC,BN,💝 GLU 💝 构成。其中前2层为 Shared across decision steps,另外两层为 Decision step dependent, (d)是 attentive transformer 结构,里面的 💝 sparsemax 💝 用来做归一化处理,并且结果中只包含突出的特征信息。
其中在(a)中,有一个将 Relu 先 Agg. 然后再与 Mask 相乘的操作,最终的到 Feature attributes,该操作是为了做展示用的,训练的时候不会用到它,所以可以先不管。
Self-supervised
自监督学习在机器学习文本任务中的一个常用的学习策略,通常自监督学习都是使用填词游戏来进行的。下图展示的是自监督学习的过程。
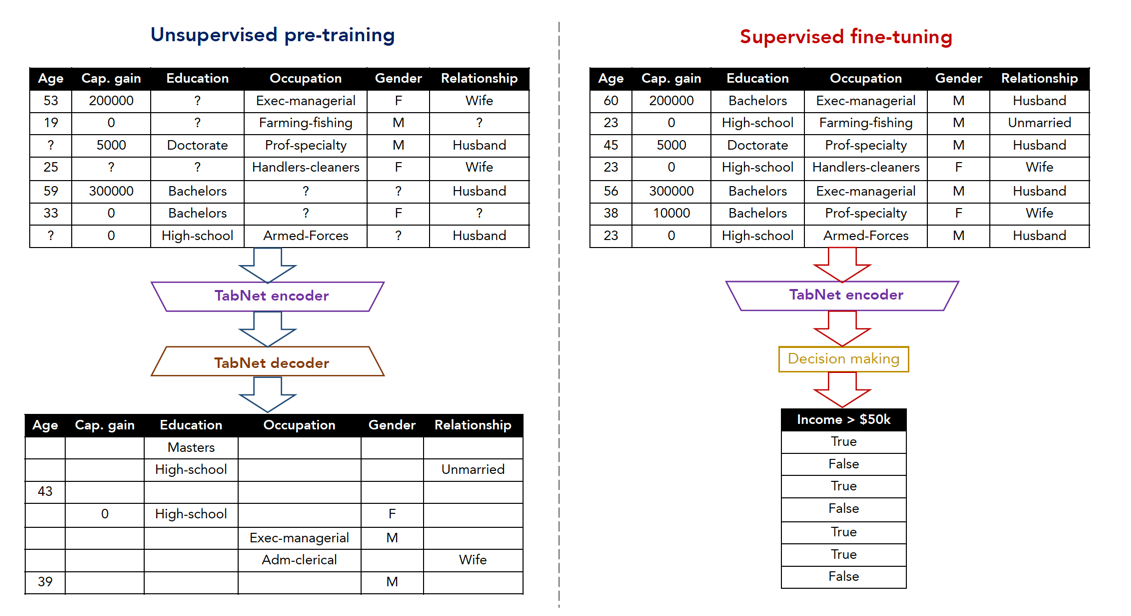
左边是自监督学习的过程,首先将输入样本随机的 mask 住一部分内容,然后放入 encoder,得到输入样本的 features,再进行 decoder ,预测 mask 掉的位置的值,进行训练。 当我们左边的任务训练好之后,就开始右边的训练,此时输入样本没有 mask,放入到在左边训练好了的 encoder 之后,得到样本的 features,然后放入到一个分类网络中,得到我们分类任务的结果。 通过微调我们的右边的网络,就能得到一个比较好的效果。
sparsemax
sparsemax 常用于多标签分类任务中,通常当作神经网络的激活函数放在最后一层取代 softmax。sparsemax 和 softmax 的区别如下:
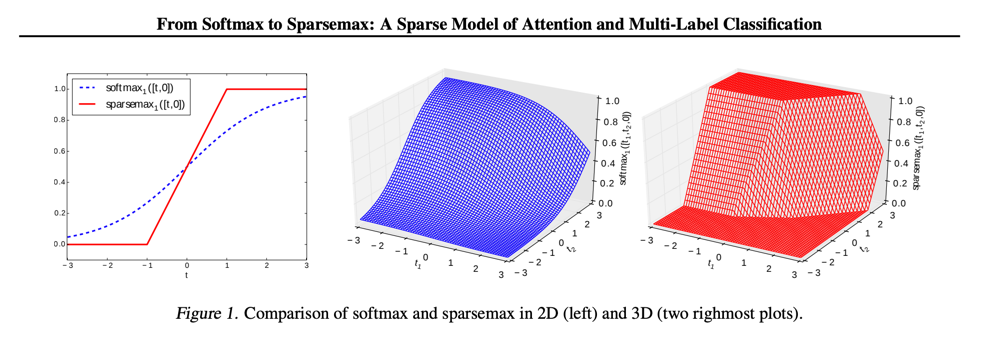
个人理解 sparsemax 的优势是在多分类任务中,使用 sparsemax 能够平衡一个样本属于多个分类的权重,而在 softmax 中 一个样本虽然可能属于多个类别,但是他们的权重却是不一样的。例如某一个样本属于1,2两个类别,如果我们的网络算得该样本在类别1,2上的 softmax 值分别为0.7和0.9,而且这两个值也是最大的两个值,虽然最终结果能得出该样本属于1,2两个类别,但是其实 网络在反向求导的过程中还是会惩罚这两个输出,因为他们不是1,而如果使用 sparsemax 就不会这样,结果也是能够得出该样本 属于1,2两个类别,而且反向的时候不会对它们进行惩罚。所以 sparsemax 在某些应用中似乎会更加合理一些。
LightGBM
TODO
XDBoost
TODO
gradient-boosted DT
TODO
代码
在 💝 dreamquark-ai 💝 的 tabnet 实现代码中有7个 example ,他们分别是:
- tabnet 对美国人口数据分类预测的基本使用介绍 💝 census_example.ipynb 💝
- 自定义规则的 tabnet 分类预测使用介绍,💝 customizing_example.py 💝
- tabnet 对森林覆盖率数据分类预测的基本使用介绍 💝 forest_example.py 💝
- tabnet 对回归数据的基本使用介绍 💝 regression_example.py 💝
- tabnet 对多分类任务的使用介绍 💝 multi_task_example.py 💝
- tabnet 对多回归任务的使用介绍 💝 multi_regression_example.py 💝
- 带自监督的预训练模型的tabnet对分类任务的使用介绍 💝 pretraining_example.py 💝
本来上面的代码,对 tabnet 的基本的使用是没问题的,但是做研究不能只是会用,还得搞明白别人是怎么实现的。所以接下来我将重新改写一下上面的代码,将调用接口的地方全部改成方法的实现。 虽然最后我绝大部分的代码还是使用的 💝 dreamquark-ai 💝 中提供的,但是我代码实现的目的不一样,观众看我的代码的话能更好的理解 tabnet 的原理和实现方法, 而 💝 dreamquark-ai 💝 的代码主要是方便别人使用,所以里面会有很多地方做了各种封装各种接口化,对于想学习 tabnet 的人来说是很不友好的。
NOTE: 本文不会列出所有的代码,只会列出关键的代码,点击💝 完整代码 💝 可下载完整的代码。带自监督学习的网络,分成自监督训练和微调两个部分,其中微调部分的代码实现和不带自监督学习的过程是一样的,所以本文将先实现不带自监督的分类任务,然后再加上自监督的代码。
tabnet 基本数据分类任务
首先是数据准备,我们的数据是一份美国部分人口的调查数据,我们的任务是通过训练该数据来预测不同的人的收入年收入是否大于50K。前10条数据如下

我们最终需要来预测 “<=50K” 这个列的数据。首先我们是要进行空值的填充,然后再将字符串数据转换成数组数据,最后我们将数据按照8:1:1的比例分成3份,分别是train,validation,和test。其中 train用来训练,validation用来在训练的时候检验效果,test用来在训练完成之后检验效果。 代码如下:
#!/usr/bin/env python
# coding: utf-8
from pytorch_tabnet.tab_model import TabNetClassifier
import torch
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import roc_auc_score
import pandas as pd
import numpy as np
import os
import wget
from pathlib import Path
from matplotlib import pyplot as plt
from torch.utils.data import Dataset
from torch.utils.data import DataLoader, WeightedRandomSampler
from torch.nn import Linear, BatchNorm1d, ReLU
from pytorch_tabnet import sparsemax
from torch.nn.utils import clip_grad_norm_
np.random.seed(1024)
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
dataset_name = 'census-income'
out = Path(os.getcwd() + '/data/' + dataset_name + '.csv')
out.parent.mkdir(parents=True, exist_ok=True)
if out.exists():
print("File already exists.")
else:
print("Downloading file...")
wget.download(url, out.as_posix())
train = pd.read_csv(out)
target = ' <=50K'
if "Set" not in train.columns:
train["Set"] = np.random.choice(["train", "valid", "test"], p=[.8, .1, .1], size=(train.shape[0],))
train_indices = train[train.Set == "train"].index
valid_indices = train[train.Set == "valid"].index
test_indices = train[train.Set == "test"].index
nunique = train.nunique()
types = train.dtypes
categorical_columns = []
categorical_dims = {}
for col in train.columns:
if types[col] == 'object' or nunique[col] < 200:
print(col, train[col].nunique())
l_enc = LabelEncoder()
train[col] = train[col].fillna("VV_likely")
train[col] = l_enc.fit_transform(train[col].values)
categorical_columns.append(col)
categorical_dims[col] = len(l_enc.classes_)
else:
train.fillna(train.loc[train_indices, col].mean(), inplace=True)
train.loc[train[target] == 0, target] = "wealthy"
train.loc[train[target] == 1, target] = "not_wealthy"
unused_feat = ['Set']
features = [col for col in train.columns if col not in unused_feat + [target]]
cat_idxs = [i for i, f in enumerate(features) if f in categorical_columns]
cat_dims = [categorical_dims[f] for i, f in enumerate(features) if f in categorical_columns]
X_train = train[features].values[train_indices]
y_train = train[target].values[train_indices]
X_valid = train[features].values[valid_indices]
y_valid = train[target].values[valid_indices]
X_test = train[features].values[test_indices]
y_test = train[target].values[test_indices]
batch_size = 128
need_shuffle = False
num_workers = 1
drop_last = False
pin_memory = True
max_epochs = 10
cross_entropy_loss = torch.nn.CrossEntropyLoss()
lambda_sparse: float = 1e-3
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# weather clip the gradient , clip the gradient can fix the gradient exploding problems
clip_value = 0
接下来我们构造数据加载器,方便训练和测试的时候使用,代码如下
class TorchDataset(Dataset):
def __init__(self, x, y):
self.x = x
self.y = y
def __len__(self):
return len(self.x)
def __getitem__(self, index):
x, y = self.x[index], self.y[index]
return x, y
train_dataloader = DataLoader(
TorchDataset(X_train.astype(np.float32), y_train),
batch_size=batch_size,
shuffle=need_shuffle,
num_workers=num_workers,
drop_last=drop_last,
pin_memory=pin_memory,
)
eval_set = [(X_train, y_train), (X_valid, y_valid)]
valid_dataloaders = []
for X, y in eval_set:
valid_dataloaders.append(
DataLoader(
TorchDataset(X.astype(np.float32), y),
batch_size=batch_size,
shuffle=False,
num_workers=num_workers,
pin_memory=pin_memory,
)
)
接下来我们开始进行模型的构造。首先我们从大的视角来构建模型,我们先定义一个 TabNet 对象,里面包含有 EmbeddingGenerator 和 TabNetNoEmbeddings 两个小的子对象。 其中 EmbeddingGenerator 指的是在我们把数据放入模型之后前的操作,在论文的网络图中其实是省略了这个步骤的。论文的网络图的输入直接是 Features ,但是该 Features 其实是已经 embedding 之后的了。 TabNetNoEmbeddings 就是我们论文中的网络图的结构了。在有 Self-supervised 的网络中,TabNetNoEmbeddings 中包含了 encoder 和 decoder 两个模块,而在没有 Self-supervised 的网络中 , TabNetNoEmbeddings 中只包含 encoder。由于 TabNet 不仅可以进行分类任务,还可以进行回归任务,所以这里我们的分类器并不在 TabNet 中。
现在假设我们有一条数据,60, 200000, Bachelors, Exec-managerial, M, Husband 分别指的是 年龄, 投资的收益, 学历, 职业, 性别, 夫妻角色,首先我们的数据要经过 LabelEncoder 将字符数据转化成数字为 [1., 0., 0., 8., 0., 3.]。
class TabNet(torch.nn.Module):
def __init__(self, input_dim, output_dim, n_d=8, n_a=8, n_steps=3, gamma=1.3, cat_idxs=[], cat_dims=[],
cat_emb_dim=1, n_independent=2, n_shared=2, epsilon=1e-15, virtual_batch_size=128, momentum=0.02,
mask_type="sparsemax", ):
"""
Defines TabNet network
Parameters
----------
input_dim : int
Initial number of features
output_dim : int
Dimension of network output
examples : one for regression, 2 for binary classification etc...
n_d : int
Dimension of the prediction layer (usually between 4 and 64)
n_a : int
Dimension of the attention layer (usually between 4 and 64)
n_steps : int
Number of successive steps in the network (usually between 3 and 10)
gamma : float
Float above 1, scaling factor for attention updates (usually between 1.0 to 2.0)
cat_idxs : list of int
Index of each categorical column in the dataset
cat_dims : list of int
Number of categories in each categorical column
cat_emb_dim : int or list of int
Size of the embedding of categorical features
if int, all categorical features will have same embedding size
if list of int, every corresponding feature will have specific size
n_independent : int
Number of independent GLU layer in each GLU block (default 2)
n_shared : int
Number of independent GLU layer in each GLU block (default 2)
epsilon : float
Avoid log(0), this should be kept very low
virtual_batch_size : int
Batch size for Ghost Batch Normalization
momentum : float
Float value between 0 and 1 which will be used for momentum in all batch norm
mask_type : str
Either "sparsemax" or "entmax" : this is the masking function to use
"""
super(TabNet, self).__init__()
self.cat_idxs = cat_idxs or []
self.cat_dims = cat_dims or []
self.cat_emb_dim = cat_emb_dim
self.input_dim = input_dim
self.output_dim = output_dim
self.n_d = n_d
self.n_a = n_a
self.n_steps = n_steps
self.gamma = gamma
self.epsilon = epsilon
self.n_independent = n_independent
self.n_shared = n_shared
self.mask_type = mask_type
if self.n_steps <= 0:
raise ValueError("n_steps should be a positive integer.")
if self.n_independent == 0 and self.n_shared == 0:
raise ValueError("n_shared and n_independent can't be both zero.")
self.virtual_batch_size = virtual_batch_size
self.embedder = EmbeddingGenerator(input_dim, cat_dims, cat_idxs, cat_emb_dim)
self.post_embed_dim = self.embedder.post_embed_dim
self.tabnet = TabNetNoEmbeddings(self.post_embed_dim, output_dim, n_d, n_a, n_steps, gamma, n_independent,
n_shared, epsilon, virtual_batch_size, momentum, mask_type, )
def forward(self, x):
x = self.embedder(x)
return self.tabnet(x)
def forward_masks(self, x):
x = self.embedder(x)
return self.tabnet.forward_masks(x)
然后将[1., 0., 0., 8., 0., 3.]放入到 EmbeddingGenerator 中,得到 [-1.1524, -0.5344, -0.3433, 0.3956, 0.4631, 1.1878]。
输入属性编码 EmbeddingGenerator 的代码如下,该属性编码是可以通过网络来学习的。
class EmbeddingGenerator(torch.nn.Module):
"""
Classical embeddings generator
"""
def __init__(self, input_dim, cat_dims, cat_idxs, cat_emb_dim):
"""This is an embedding module for an entire set of features
Parameters
----------
input_dim : int
Number of features coming as input (number of columns)
cat_dims : list of int
Number of modalities for each categorial features
If the list is empty, no embeddings will be done
cat_idxs : list of int
Positional index for each categorical features in inputs
cat_emb_dim : int or list of int
Embedding dimension for each categorical features
If int, the same embedding dimension will be used for all categorical features
"""
super(EmbeddingGenerator, self).__init__()
if cat_dims == [] and cat_idxs == []:
self.skip_embedding = True
self.post_embed_dim = input_dim
return
elif (cat_dims == []) ^ (cat_idxs == []):
if cat_dims == []:
msg = "If cat_idxs is non-empty, cat_dims must be defined as a list of same length."
else:
msg = "If cat_dims is non-empty, cat_idxs must be defined as a list of same length."
raise ValueError(msg)
elif len(cat_dims) != len(cat_idxs):
msg = "The lists cat_dims and cat_idxs must have the same length."
raise ValueError(msg)
self.skip_embedding = False
if isinstance(cat_emb_dim, int):
self.cat_emb_dims = [cat_emb_dim] * len(cat_idxs)
else:
self.cat_emb_dims = cat_emb_dim
# check that all embeddings are provided
if len(self.cat_emb_dims) != len(cat_dims):
msg = f"""cat_emb_dim and cat_dims must be lists of same length, got {len(self.cat_emb_dims)}
and {len(cat_dims)}"""
raise ValueError(msg)
self.post_embed_dim = int(
input_dim + np.sum(self.cat_emb_dims) - len(self.cat_emb_dims)
)
self.embeddings = torch.nn.ModuleList()
# Sort dims by cat_idx
sorted_idxs = np.argsort(cat_idxs)
cat_dims = [cat_dims[i] for i in sorted_idxs]
self.cat_emb_dims = [self.cat_emb_dims[i] for i in sorted_idxs]
for cat_dim, emb_dim in zip(cat_dims, self.cat_emb_dims):
self.embeddings.append(torch.nn.Embedding(cat_dim, emb_dim))
# record continuous indices
self.continuous_idx = torch.ones(input_dim, dtype=torch.bool)
self.continuous_idx[cat_idxs] = 0
def forward(self, x):
"""
Apply embeddings to inputs
Inputs should be (batch_size, input_dim)
Outputs will be of size (batch_size, self.post_embed_dim)
"""
if self.skip_embedding:
# no embeddings required
return x
cols = []
cat_feat_counter = 0
for feat_init_idx, is_continuous in enumerate(self.continuous_idx):
# Enumerate through continuous idx boolean mask to apply embeddings
if is_continuous:
cols.append(x[:, feat_init_idx].float().view(-1, 1))
else:
cols.append(
self.embeddings[cat_feat_counter](x[:, feat_init_idx].long())
)
cat_feat_counter += 1
# concat
post_embeddings = torch.cat(cols, dim=1)
return post_embeddings
无自监督学习的TabNet的整体结构在 TabNetNoEmbeddings 中, TabNetNoEmbeddings 的代码如下。
class TabNetNoEmbeddings(torch.nn.Module):
def __init__(self, input_dim, output_dim, n_d=8, n_a=8, n_steps=3, gamma=1.3, n_independent=2, n_shared=2,
epsilon=1e-15, virtual_batch_size=128, momentum=0.02, mask_type="sparsemax", ):
"""
Defines main part of the TabNet network without the embedding layers.
Parameters
----------
input_dim : int
Number of features
output_dim : int or list of int for multi task classification
Dimension of network output
examples : one for regression, 2 for binary classification etc...
n_d : int
Dimension of the prediction layer (usually between 4 and 64)
n_a : int
Dimension of the attention layer (usually between 4 and 64)
n_steps : int
Number of successive steps in the network (usually between 3 and 10)
gamma : float
Float above 1, scaling factor for attention updates (usually between 1.0 to 2.0)
n_independent : int
Number of independent GLU layer in each GLU block (default 2)
n_shared : int
Number of independent GLU layer in each GLU block (default 2)
epsilon : float
Avoid log(0), this should be kept very low
virtual_batch_size : int
Batch size for Ghost Batch Normalization
momentum : float
Float value between 0 and 1 which will be used for momentum in all batch norm
mask_type : str
Either "sparsemax" or "entmax" : this is the masking function to use
"""
super(TabNetNoEmbeddings, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.is_multi_task = isinstance(output_dim, list)
self.n_d = n_d
self.n_a = n_a
self.n_steps = n_steps
self.gamma = gamma
self.epsilon = epsilon
self.n_independent = n_independent
self.n_shared = n_shared
self.virtual_batch_size = virtual_batch_size
self.mask_type = mask_type
self.initial_bn = BatchNorm1d(self.input_dim, momentum=0.01)
self.encoder = TabNetEncoder(input_dim=input_dim, output_dim=output_dim, n_d=n_d, n_a=n_a, n_steps=n_steps,
gamma=gamma, n_independent=n_independent, n_shared=n_shared, epsilon=epsilon,
virtual_batch_size=virtual_batch_size, momentum=momentum, mask_type=mask_type, )
if self.is_multi_task:
self.multi_task_mappings = torch.nn.ModuleList()
for task_dim in output_dim:
task_mapping = Linear(n_d, task_dim, bias=False)
initialize_non_glu(task_mapping, n_d, task_dim)
self.multi_task_mappings.append(task_mapping)
else:
self.final_mapping = Linear(n_d, output_dim, bias=False)
initialize_non_glu(self.final_mapping, n_d, output_dim)
def forward(self, x):
res = 0
steps_output, M_loss = self.encoder(x)
res = torch.sum(torch.stack(steps_output, dim=0), dim=0)
if self.is_multi_task:
# Result will be in list format
out = []
for task_mapping in self.multi_task_mappings:
out.append(task_mapping(res))
else:
out = self.final_mapping(res)
return out, M_loss
def forward_masks(self, x):
return self.encoder.forward_masks(x)
由于是无监督学习,所以只有 encoder 部分,没有 decoder 部分,我们其实可以把 decoder 部分加进来,当作后面分类层。但是由于 TabNet 不关心分类与回归,所以这里就没有 decoder 。
从论文中可以看到,在 encoder 中,首先我们的数据会进入到 BN 层,在代码中,BN的实现并不是使用的常用的BN,而是使用的 GBN(Ghost Batch Normalization) 。然后数据会分两头分别进入到 Feature transformer 模块中和 Mask 模块中,如下图所示:
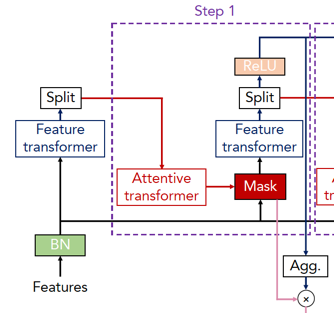
Feature transformer 的代码如下:
class FeatTransformer(torch.nn.Module):
def __init__(
self,
input_dim,
output_dim,
shared_layers,
n_glu_independent,
virtual_batch_size=128,
momentum=0.02,
):
super(FeatTransformer, self).__init__()
"""
Initialize a feature transformer.
Parameters
----------
input_dim : int
Input size
output_dim : int
Output_size
shared_layers : torch.nn.ModuleList
The shared block that should be common to every step
n_glu_independent : int
Number of independent GLU layers
virtual_batch_size : int
Batch size for Ghost Batch Normalization within GLU block(s)
momentum : float
Float value between 0 and 1 which will be used for momentum in batch norm
"""
params = {
"n_glu": n_glu_independent,
"virtual_batch_size": virtual_batch_size,
"momentum": momentum,
}
if shared_layers is None:
# no shared layers
self.shared = torch.nn.Identity()
is_first = True
else:
self.shared = GLU_Block(
input_dim,
output_dim,
first=True,
shared_layers=shared_layers,
n_glu=len(shared_layers),
virtual_batch_size=virtual_batch_size,
momentum=momentum,
)
is_first = False
if n_glu_independent == 0:
# no independent layers
self.specifics = torch.nn.Identity()
else:
spec_input_dim = input_dim if is_first else output_dim
self.specifics = GLU_Block(
spec_input_dim, output_dim, first=is_first, **params
)
def forward(self, x):
x = self.shared(x)
x = self.specifics(x)
return x
Feature transformer 结构如下图所示
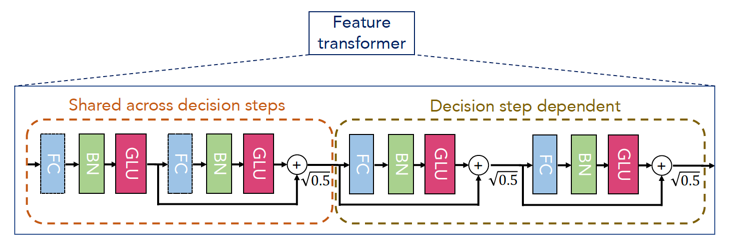
Feature transformer 分成两个部分,一部分为 Shared across decision steps,就是代码中的self.shared,另一部分为 Decision step dependent,就是代码中的self.specifics,它们里面都是由两个 FC+BN+GLU 组成,只是连接方式不一样。 在dreamquark-ai 的代码中 将 FC+BN+GLU 放在了一起,组成一个 GLU_Layer ,GLU_Layer 代码如下
class GLU_Layer(torch.nn.Module):
def __init__(
self, input_dim, output_dim, fc=None, virtual_batch_size=128, momentum=0.02
):
super(GLU_Layer, self).__init__()
self.output_dim = output_dim
if fc:
self.fc = fc
else:
self.fc = Linear(input_dim, 2 * output_dim, bias=False)
initialize_glu(self.fc, input_dim, 2 * output_dim)
self.bn = GBN(
2 * output_dim, virtual_batch_size=virtual_batch_size, momentum=momentum
)
def forward(self, x):
x = self.fc(x)
x = self.bn(x)
out = torch.mul(x[:, : self.output_dim], torch.sigmoid(x[:, self.output_dim :]))
return out
我们的数据经过了 Feature transformer 之后,得到的输出为:[-0.5458, 0.1613, 0.0086, -1.0458, 0.6683, -0.5557, -0.3257, 0.1752, -0.5458, -0.3031, 0.7458, -0.1514, -0.1752, -0.3387, 0.1345, -0.1505],此时我们的输出为16维。
然后数据进入到split,split将数据从维度方向一分为二,一部分数据经过RELU,进入到输出环节,另一部分进入到 Attentive transformer 中。
Attentive transformer 结构图如下所示
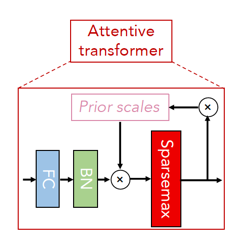
数据在 Attentive transformer 中首先是经过 FC 和 GBN,然后与 Prior scales 相乘,得到结果之后,再经过 Sparsemax 得到输出。其中 Prior scales 初始值为全为1的向量, 当数据经过了 encoder 的 step 1 之后,在 step 2 中 Prior scales 就是 Attentive transformer 的输出。
Attentive transformer 的代码如下:
class AttentiveTransformer(torch.nn.Module):
def __init__(
self,
input_dim,
output_dim,
virtual_batch_size=128,
momentum=0.02,
mask_type="sparsemax",
):
"""
Initialize an attention transformer.
Parameters
----------
input_dim : int
Input size
output_dim : int
Output_size
virtual_batch_size : int
Batch size for Ghost Batch Normalization
momentum : float
Float value between 0 and 1 which will be used for momentum in batch norm
mask_type : str
Either "sparsemax" or "entmax" : this is the masking function to use
"""
super(AttentiveTransformer, self).__init__()
self.fc = Linear(input_dim, output_dim, bias=False)
initialize_non_glu(self.fc, input_dim, output_dim)
self.bn = GBN(
output_dim, virtual_batch_size=virtual_batch_size, momentum=momentum
)
if mask_type == "sparsemax":
# Sparsemax
self.selector = sparsemax.Sparsemax(dim=-1)
elif mask_type == "entmax":
# Entmax
self.selector = sparsemax.Entmax15(dim=-1)
else:
raise NotImplementedError(
"Please choose either sparsemax" + "or entmax as masktype"
)
def forward(self, priors, processed_feat):
x = self.fc(processed_feat)
x = self.bn(x)
x = torch.mul(x, priors)
x = self.selector(x)
return x
当我们的数据经过了 Attentive transformer 之后,输出的就是 attention ,此时我们将该 attention 与最开始经过 BN 之后的 features 相乘,这就是 tabnet 结构图中的 Mask 操作。然后我们将 Mask 中得到的结果当作输入,放入 Feature transformer ,然后经过 split 和 ReLU 得到输出,同时 split 的一部分结果 当作下一个 step 的输入。该输出还经过Agg操作,与之前的 Mask 的结果进行相乘,作为 Feature attribute 的其中一步。
💝 INVASE 💝 论文中用实验说明了使用带选择性的feature比使用全部的feature效果要好。
本文由 louis 创作,采用 知识共享署名4.0 国际许可协议进行许可
github 地址 https://github.com/7568/7568.github.io
最后编辑时间为:2022-10-28