简介
DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFMAN CODING 是 Song Han 在 2016 年发表在 cs.cv 上的一篇论文。 该论文主要讲述的是通过一种新方法使神经网络的参数大幅减少,同时网络的性能基本上不变,例如将 AlexNet 的参数从 240MB 减少到6.9M,这是十分惊人的效果。接下来我就通过论文和代码来分析一下论文。
摘要
神经网络通常需要很大的计算量和存储量,从而使得它很难在资源受限的嵌入式系统上部署。为了处理这种限制,我们提出了一种深度压缩的方法:”deep compression”,该方法分成三个步骤来进行压缩,分别是剪枝、 量化处理、 Huffman 编码。这三个步骤共同作用,使得网络所需要的存储能缩小到的35倍或者49倍,而不影响网络的精度。我们方法的第一步就是通过学习来给网络剪枝,只留下重要的连接层。接下来,我们我们量化分析权重参数,使得网络能有 更多的权重共享。最后我们使用 Huffman 编码 。在经过了前两步之后,我们重新训练网络,来微调剩下的连接层,和量化之后的中心点。剪枝通常能将网络连接的层数减少9到13倍,然后量化分析能将每层连接的表示字节从32变到5。 在 ImageNet 数据集上,我们的方法将 AlexNet 所需要的存储从 240MB 减少到了 6.9MB,而且精度还没有损失。将 VGG-16 所需要的存储从 552MB 减少到了 11.3MB同样也没有损失精度。从而使得压缩之后的网络 能够适配到 SRAM 缓存的单片机上,而不仅仅是片外 DRAM 内存上。我们的方法同样能方便的使复杂的网络能够应用到那些大小和网络宽带受限的手机应用程序上。在一些标准的 CPU, GPU 和手机 GPU上,使用我们的方法压缩之后的网络,每一层都会有 3到4倍的提速,在计算效能上有3到7倍的提升。
压缩的整体结构如下图所示:
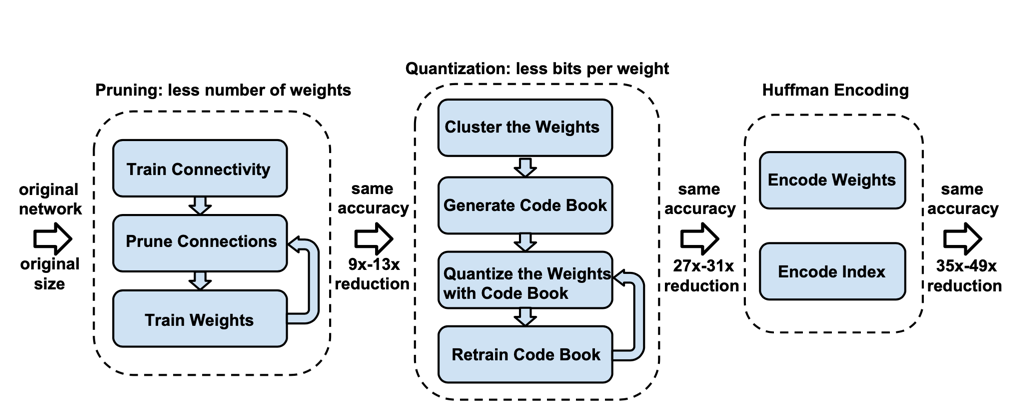
INTRODUCTION
首先我们通过正常的网络训练来学习网络中的连接,然后我们裁剪掉参数权重小的连接层:网路中所有参数权重小于指定的阈值的连接全部被裁剪掉。最后我们重新训练网络来学习到最终的网络权重参数,从而只 保留稀疏的连接层。接下来我们将剪枝后的稀疏结构的参数使用行压缩(CSR) 或列压缩(CSC)的方法进行压缩并保存,该操作需要2a + n + 1个数据,其中a表示非零元素的个数,n表示行或者列。
为了进一步进行压缩,我们在对稀疏矩阵进行存储的时候使用相对位置索引的方式进行存储,而不是绝对位置的存储。在编码该相对位置中,我们使用8bits和5bits来分别编码 conv 层和 fc 层。
在我们编码的时候,当索引的相对位置大于我们指定的范围的时候,我们在中间插入0来解决该问题。例如在如下的图中:
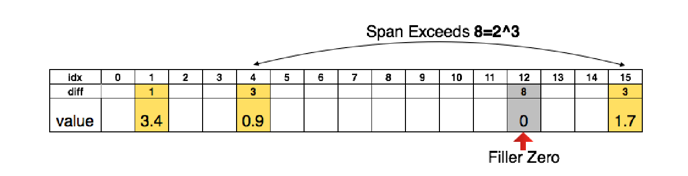 该图表示我们需要存储的数据为一个一维的稀疏向量,向量长度为16,其中只有三个位置,分别在位置1、4、15,当我们需要存储该向量的时候,最简单的方式是定义一个长度为16的区域,在1、4、15,位置为3.4、0.9、1.7,其余
位置全为0,但是这样虽然简单,所需要的存储空间就会比较大。这时我们就可以使用一种相对位置编码的压缩方法,来压缩这个向量,从而保存的时候只需使用较少的存储空间。
具体的方法是我们找每个不为0的元素,再找到他们相对于前一个不为0的元素的相对位置,例如3.4这个数,相对于开始位置0而言他的相对位置为1,0.9这个数相对于3.4这个数而言他的位置为3,依次类推。
在图中,由于我们位置编码使用的是8bits,8bits只能表示0到7,包括7,表示不了大于7的数,在计算1.7这个数相对于0.9这个数的相对位置的时候,本来应该为11,但是超过了8bits所能表达的范围,所以这里作者就通过在相对位置刚好等于8的位置填充0,从而让1.7的相对位置是从填充0的位置开始计算的,于是乎1.7元素的相对位置就是3。
至于为什么用8bits,或者5bits,就是为了存储的时候能更节省存储空间。
该图表示我们需要存储的数据为一个一维的稀疏向量,向量长度为16,其中只有三个位置,分别在位置1、4、15,当我们需要存储该向量的时候,最简单的方式是定义一个长度为16的区域,在1、4、15,位置为3.4、0.9、1.7,其余
位置全为0,但是这样虽然简单,所需要的存储空间就会比较大。这时我们就可以使用一种相对位置编码的压缩方法,来压缩这个向量,从而保存的时候只需使用较少的存储空间。
具体的方法是我们找每个不为0的元素,再找到他们相对于前一个不为0的元素的相对位置,例如3.4这个数,相对于开始位置0而言他的相对位置为1,0.9这个数相对于3.4这个数而言他的位置为3,依次类推。
在图中,由于我们位置编码使用的是8bits,8bits只能表示0到7,包括7,表示不了大于7的数,在计算1.7这个数相对于0.9这个数的相对位置的时候,本来应该为11,但是超过了8bits所能表达的范围,所以这里作者就通过在相对位置刚好等于8的位置填充0,从而让1.7的相对位置是从填充0的位置开始计算的,于是乎1.7元素的相对位置就是3。
至于为什么用8bits,或者5bits,就是为了存储的时候能更节省存储空间。
TRAINED QUANTIZATION
网络量化和权重共享通过减少用来表达每一层权重所需要的bits的数量来进一步对剪枝后的网络进行压缩。我们通过使用多个连接共享相同的权重,从而限制住需要保存的有效权重的数量,然后再微调这些共享权重。
下图是一个权重共享的示意图:
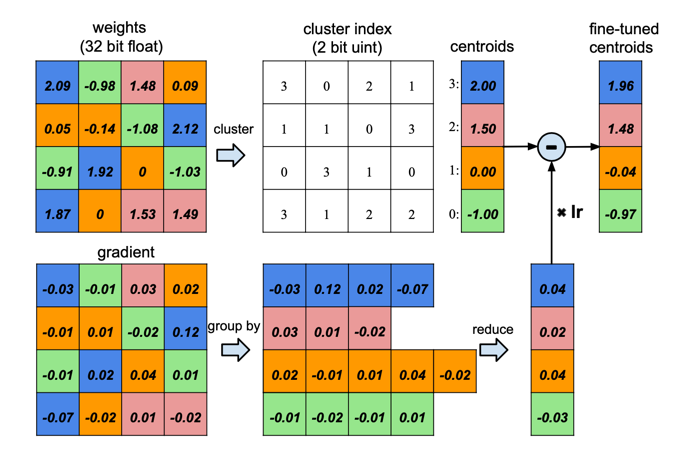 假设我们网络中的某一层的权重参数为4x4的矩阵,如图中左上方的矩阵,图中左下方的矩阵为对应的梯度矩阵,我们的量化处理的过程为:首先我们将权重进行聚类,如图所示,将权重参数分成了4类,然后用每一类的均值来代替该类,
于是我们4x4的矩阵就被压缩成了4x1的矩阵。对于梯度矩阵,我们将梯度矩阵中与权重矩阵中位置相同的地方标为一类,然后再将每一类进行相加,得到一个4x1的梯度矩阵,于是我们的梯度矩阵也被压缩成了4x1的大小。
最终我们使用压缩后的(权重矩阵)-(lr*梯度矩阵),得到微调之后的权重参数矩阵。通过该方法我们将AlexNet中的channel为256的卷积核进行权重共享,将它量化到8-bits的格式中,将channel为32的全连接的参数进行权重共享,将它量化到5-bits的格式中,而且没有任何的精度损失。
假设我们网络中的某一层的权重参数为4x4的矩阵,如图中左上方的矩阵,图中左下方的矩阵为对应的梯度矩阵,我们的量化处理的过程为:首先我们将权重进行聚类,如图所示,将权重参数分成了4类,然后用每一类的均值来代替该类,
于是我们4x4的矩阵就被压缩成了4x1的矩阵。对于梯度矩阵,我们将梯度矩阵中与权重矩阵中位置相同的地方标为一类,然后再将每一类进行相加,得到一个4x1的梯度矩阵,于是我们的梯度矩阵也被压缩成了4x1的大小。
最终我们使用压缩后的(权重矩阵)-(lr*梯度矩阵),得到微调之后的权重参数矩阵。通过该方法我们将AlexNet中的channel为256的卷积核进行权重共享,将它量化到8-bits的格式中,将channel为32的全连接的参数进行权重共享,将它量化到5-bits的格式中,而且没有任何的精度损失。
在上面的聚类中,假如我们给定聚类的类别k,那么我们只需要\(log_2(k)\)个bits来对索引进行编码。通常来说对于有n个连接的网络,每一个连接我们都用b个bits来表示,我们将连接限制到只有k个共享的权重中,从而我们计算压缩率的公式为:
\[r = \frac{n*b}{n*log_2(k) + k*b}\]例如在上面权重共享的图中,我们原始权重的大小为16,共享权重之后,大小为4。在原始权重中我们需要32 bits的大小来保存每个权重中的值,现在我们只有4个权重中的值需要32 bits的大小来保存,然后再用16个2 bits来保存聚类的索引,所以总的 压缩率为:\(\frac{16 * 32}{16*log_2(4) + 4 * 32}\)
WEIGHT SHARING
当我们的原始网络训练好之后,我们使用K-means的聚类方法来确定网络的每一层参数的共享权重,所以所有的聚类在同一类的网络都共享相同的权重参数。权重不会在网络层之间共享。例如我们将大小为n的原始权重\(W = {w_1, w_2, ..., w_n}\)聚类成k类\(C = {c_1, c_2, ..., c_k}\), \(n \gg k\),这个操作就像是最小化聚类内部的平方和(WCSS:within-cluster sum of squares),公式如下:
\[\mathop{\arg\min}\limits_{C} \displaystyle\sum_{i=1}^k\sum_{w\in c_i}|w-c_i|^2\]2015年的时候 Chen 等人发表的方法HashNet ,其中也有关于权重共享的方法,它的具体做法是在网络未经过任何训练之前,通过hash的方法来决定权重的共享。我们的方法与该方法不同, 我们的做法是先让网络进行训练完成,然后再来决定权重的共享,所以我们的共享权重与原始网络中的权重是相近的。
INITIALIZATION OF SHARED WEIGHTS
K-means中k个中心的初始化选择会影响聚类的质量进而影响网络预测的准确率。我们测试了三种初始化方法,分别是:随机的选择(Forgy方法), 基于密度的选择(density-based), 和线性初始化(linear initialization)。 在图4中我们展示了AlexNet中的第三层卷积的原始权重分布的累计分布函数CDF(cumulative distribution function),蓝线表示,概率密度函数PDF(probability density function),红线表示。在经过网络剪枝之后, 网络形成了双峰的分布。在图的底部展示的是三种不同的初始化方法所产生的关于权重的初始化中心点。在图中的例子中,我们使用的是\(k=13\)
随机的选择(Forgy方法):假设我们要将我们的数据集聚类成k类,那么Forgy方法就是随机的选择k个点作为初始化中心点。如上图中的黄色的点。因为双峰分布有两个峰,所以Forgy方法倾向于将初始点聚焦在双峰的附近。
基于密度的选择(density-based):首先将权重的CDF相对于y轴进行等分,然后找到等分点的水平线与CDF的交点,最后找到交点的垂直线与x轴的交点,将这些x轴上的点作为初始化点。如图中的蓝色的点所示。 该方法能让产生的初始化点集中在双峰附近,但是比Forgy方法分散一些。
线性初始化(linear initialization):该方法首先找到权重中的最大值max和最小值min,然后在[min,max]之间进行等分,从而形成初始化中心点。该方法相对于前面的两个方法是最分散的。
我们认为大的权重的值会比小的权重的值更加重要,但是大的权重的值往往很少。因此对于 Forgy 初始化和 density-based 初始化,非常少的中心点会有绝对大的值,从而导致对于那些只有很少的大的值的权重的表示会很差,而Linear初始化就没有这种问题。 在实验部分我们比较了不同的初始化方法在在经过聚类和微调之后的精确度,结果显示使用Linear初始化效果最好。
FEED-FORWARD AND BACK-PROPAGATION
在1维的K-means聚类中,中心点是权重共享的。于是在前向传播阶段和反向传播阶段查找权重表就有点不直接。每一层连接都保存有权重共享表中的索引,在反向传播阶段,通过计算和使用共享权重的梯度来更新共享权重, 该过程在图3中有展示。
我们使用\(\ell\)来表示损失,第\(i\)列,第\(j\)行的权重记为\(W_{ij}\),\(W_{ij}\)所属的聚类的中心点的元素记为\(I_{ij}\),该层中第\(k\)个聚类中心点记为\(C_k\), 通过使用指示函数\(\mathbb{1(.)}\),那么在该层中,聚类中心点的梯度计算公式如下:
\[\frac{\partial \ell}{\partial C_k} = \displaystyle\sum_{i,j}\frac{\partial \ell}{\partial W_{ij}}\frac{\partial W_{ij}}{\partial C_k} = \displaystyle\sum_{i,j}\frac{\partial \ell}{\partial W_{ij}}\mathbb{1}(I_{ij}=k)\]HUFFMAN CODING
Huffman 编码是一种被广泛使用的低失真的最优压缩编码。它使用一组可变长度的编码字来对原始符号进行编码。通过计算原始数据中每个符号出现的次数,来生成一个关于编码符号的对应表。出现次数越多的符号,会使用越小的编码字符来对它进行编码,从而使得原始数据存储的时候所需要的空间变小。
EXPERIMENTS
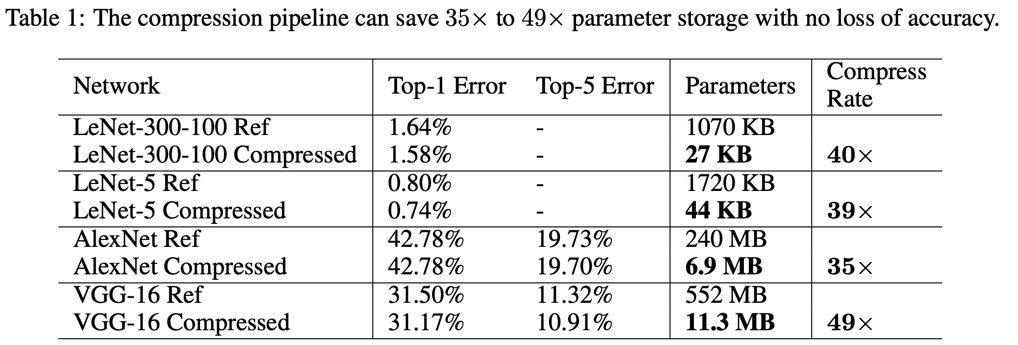
我们分别对四个网络进行了剪枝,量化,和Huffman编码,分别是两个用于MNIST数据集和ImageNet数据集。在表1中我们展示了剪枝前后的网络参数和精确度。我们的管道式的压缩方法,使得不同的网络的存储容量 减少有35到49倍,而且还不损失精度。AlexNet的整体大小从240MB 降低到了 6.9MB,从而使得它能够倍放入到单片机上运行,解除了之前需要存放到耗能很到的DRAM内存上的限制。
我们使用的是Caffe框架来进行训练。通过在 blobs 上添加mask来对剪枝的网络进行遮住的方式更新,从而来实现剪枝操作。通过维持 codebook 的结构来保存共享网络,再进行聚类操作,然后再计算每一层的梯度,从而实现量化的权重共享。 所有的梯度计算出来后,会被放到一起,用来更新每一个权重。Huffman编码不需要训练,在所有的微调完成之后再进行离线操作即可。
这部分的 blobs 和 codebook,以及梯度如何放到一起来更新共享权重还不是很懂,以后弄懂之后再更新
LENET-300-100 AND LENET-5 ON MNIST
下面我们我们展示在 MNIST 数据集上的不同模型的的实验效果,LeNet-300-100 是一个全连接模型,LeNet-5 是卷积神经网络模型。
下面的表1展示的是不同模型的压缩率和准确率:
下面的表2展示的是在模型 LeNet-300-100 上的消融实验 P: 表示剪枝, Q:表示量化, H:表示 Huffman 编码
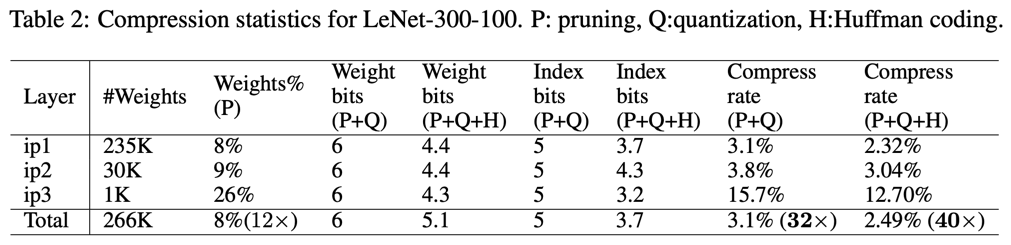
下面的表3展示的是在模型 LeNet-5 上的消融实验 P: 表示剪枝, Q:表示量化, H:表示 Huffman 编码
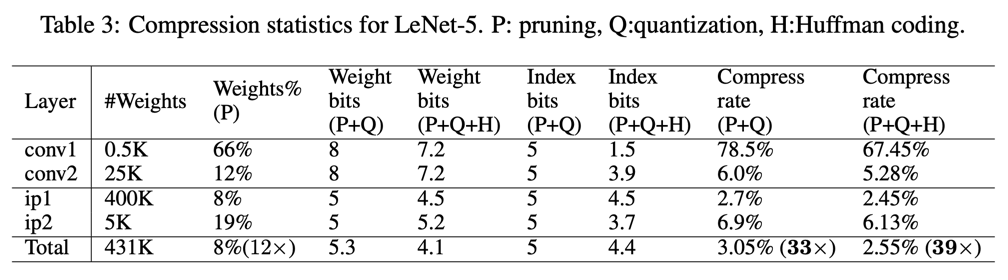
ALEXNET ON IMAGENET
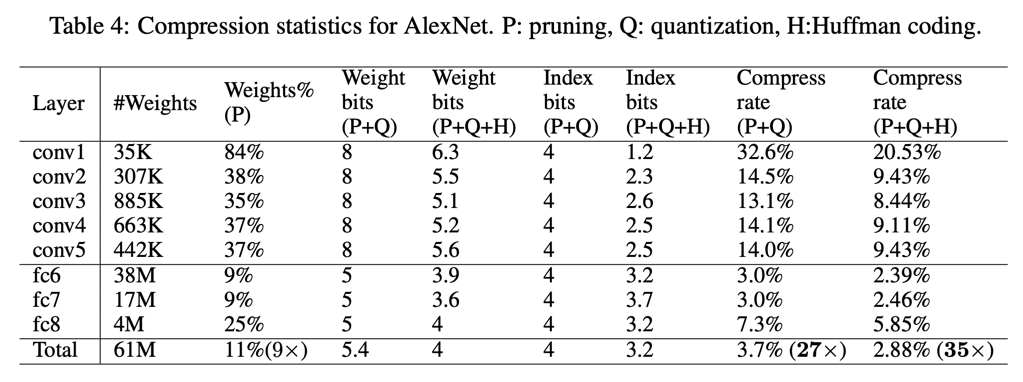
下面的表4展示的是在 IMAGENET 数据集上 ALEXNET 的消融实验结果。
VGG-16 ON IMAGENET
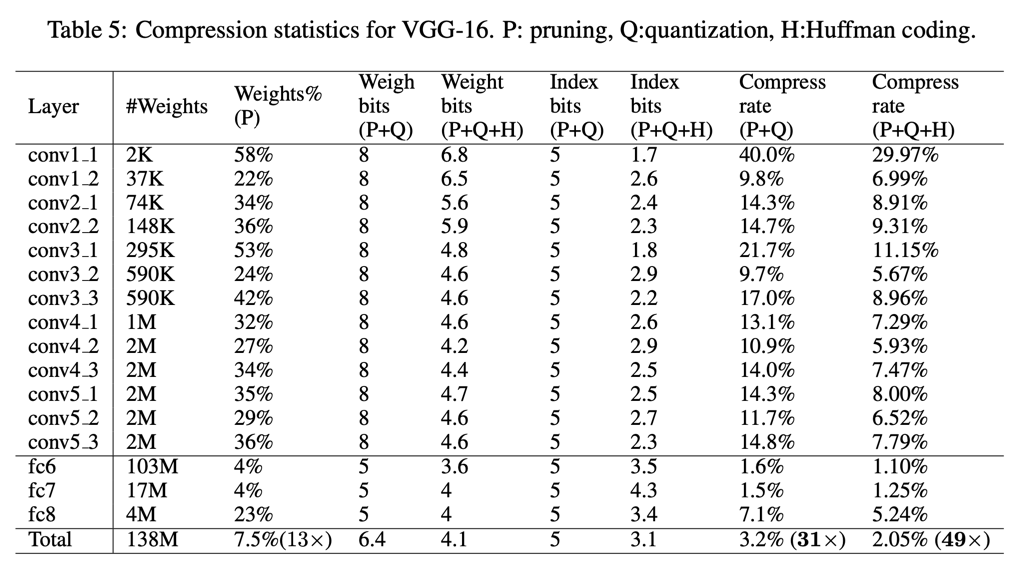
下面的表5展示的是在 IMAGENET 数据集上 VGG-16 的不同层的消融实验结果。
DISCUSSIONS
PRUNING AND QUANTIZATION WORKING TOGETHER
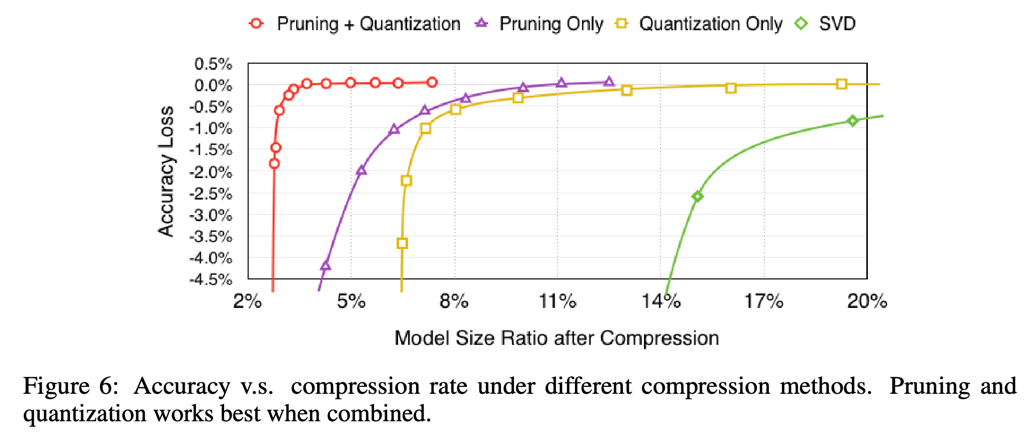
下面的图6展示的是剪枝和量化单独或者一起作用在不同压缩率下的准确率。我们还比较了使用SVD的方法进行压缩。最终得出还是我们的组合方法最好。
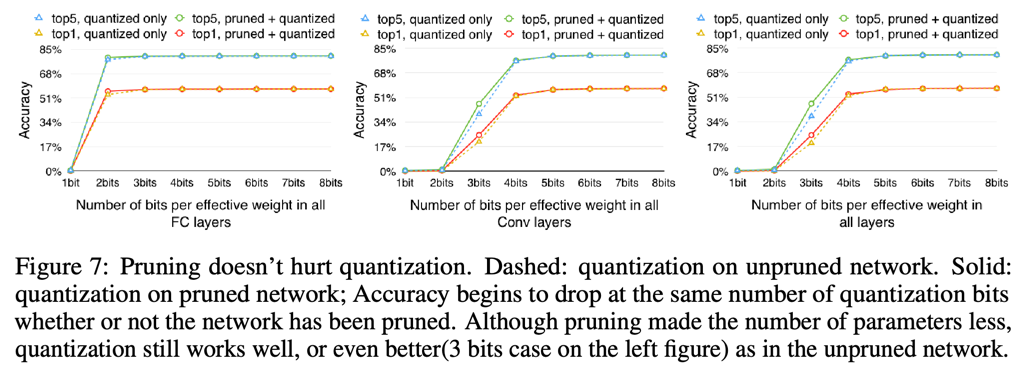
下面的图7展示的是剪枝和量化并不会对准确率有影响。
CENTROID INITIALIZATION
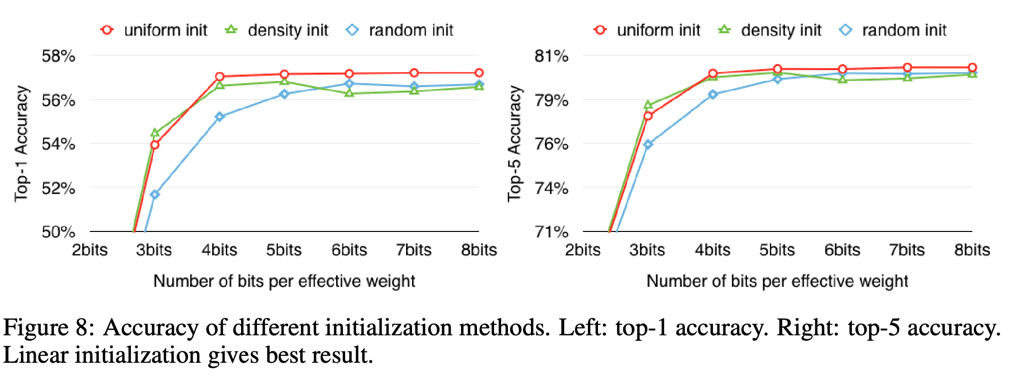
下面的图8展示了当选择不同的方法来初始化聚类中心点对准确率的影响。
SPEEDUP AND ENERGY EFFICIENCY
深度压缩的目标是对延迟记为敏感的手机应用程序,这些程序通常需要实时的得到结果,例如使用嵌入在自动驾驶汽车上的处理器来进行路上行人检测。对于这些任务, 等待一个组装好的batch会大大增加延迟,所以当我们想在性能和能耗上有所突破的话,我们需要考虑 batch 为1的情况。
在网络中,全连接层占了主要的大小(通常超过90%),也是Deep Compression中压缩得最多的地方。在一些主流的物品检测算法如fast R-CNN 中,没有压缩的全连接层占了整体运行 时间的38%,所以很有意思的基准点在全连接层上,就可以看出 Deep Compression 在性能和能耗上的影响。于是我们将我们的基准点设置在AlexNet 和 VGG-16的第6,7,8个 全连接层上。在没有batch的情况下,激活矩阵就是一个只有一列的向量,所以计算量归结起来分别就是原始数据和剪枝后的数据对应的密集和稀疏向量的乘法。 由于当前 CPU 和 GPU 上的 BLAS 库不支持间接查找和相对索引,所以我们没有对量化模型进行基准测试。
我们比较了三种不同的现成硬件:分别是NVIDIA GeForce GTX Titan X,Intel Core i7 5930K两个桌面电脑处理器和NVIDIA Tegra K1手机处理器。为了运行GPU 上的基准点,我们使用 cuBLAS GEMV 作为原始的密集层。对于剪枝后的稀疏层,我们将稀疏矩阵储存成CSR(compressed sparse row)格式,下面有对该格式的介绍,和使用cuSPARSE CSRMV核, 将优化后的核来进行GPU上的矩阵向量乘法。为了在cpu上运行基准测试,我们使用 MKL CBLAS GEMV 来运行原始的密集矩阵模型,使用 MKL SPBLAS CSRMV 来运行剪枝后的稀疏矩阵模型。
CSR(compressed sparse row)
CSR(compressed sparse row)格式是一种稀疏矩阵的存储另一种方法,它将一个稀疏矩阵存储成3个向量。假设矩阵的所有值,行索引,列索引分别记为:Value,COL_INDEX,ROW_INDEX。
例如对于如下矩阵:
\(\begin{pmatrix}
10 & 20 & 0 & 0 & 0 & 0 \\
0 & 30 & 0 & 40 & 0 & 0 \\
0 & 0 & 50 & 60 & 70 & 0 \\
0 & 0 & 0 & 0 & 0 & 80
\end{pmatrix}\)
那么它的 Value 就是所有的非 0 元素组成的向量,所以\(Value = [ 10 ,20, 30,40 ,50 ,60, 70, 80 ]\)
ROW_INDEX 指的是每一行的非 0 元素所在的行的索引,所以\(ROW\_INDEX\)为 (10, 20) (30, 40) (50, 60, 70) (80)所在的行的索引。
所以\(ROW\_INDEX = [ 0 , 0, 1 , 1 , 2 , 2 , 2 ,3 ]\)
COL_INDEX 指的是每一行的非 0 元素所在的列的索引,所以\(COL\_INDEX\)为 (10, 20,...) (0,30, 0,40,...) (...,50, 60, 70,...) (...,80)所在的列的索引。
所以\(COL\_INDEX = [ 0 , 1 , 1 , 3 , 2 , 3 ,4 , 5 ]\)
所以对于正常的用索引来存储矩阵的方法中,上面的矩阵的存储格式为
Value = [10 20 30 40 50 60 70 80]
ROW_INDEX = [0 0 1 1 2 2 2 3]
COL_INDEX = [0 1 1 3 2 3 4 5]
对于 CSR(compressed sparse row)这种压缩格式,它并不是直接存储行索引和列索引,而是列索引和 INDPTR , INDPTR 指的是每一行的前面所有行的元素的个数。 例如在上面的例子中,INDPTR的第0个值是第0行元素的前面所有行的元素的个数只和,由于第0行前面没有元素,所以个数为0。依次类推,所以 INDPTR 的值为\([0, 2 ,4 ,7, 8]\), 这样存储的大小就比上面使用行索引和列索引所使用的空间要小一些。
所以对于上面的矩阵,它的 CSR(compressed sparse row)格式为:
Value = [10 20 30 40 50 60 70 80]
COL_INDEX = [0 1 1 3 2 3 4 5]
INDPTR = [0 2 4 7 8]
在字符计算的时候,存储使用率会随着是否使用batch不同而不同,当数据是有batch形式的矩阵的时候,运算就变成了矩阵相乘,性能就会有提升。也会对缓存更加匹配,同时也可以提高重复使用的效率。 在这种情况下,存储空间复杂度为\(O(n^2)\),计算复杂度为\(O(n^3)\),存储空间复杂度与计算复杂度的比为:\(1/n\)。
在实际应用场景中,当不能使用batch的时候,输入是一个单个的向量,此时的计算就变成了矩阵与向量的乘法,在这种情况下,存储空间复杂度为\(O(n^2)\),计算复杂度为\(O(n^2)\),存储空间复杂度与计算复杂度相同。 标明矩阵向量(MV)的操作比矩阵矩阵(MM)的操作需要绑定更多的存储。所以减少存储是不使用batch的时候的关键。
在一些可以容忍低延迟的任务中,使用batch是更好的选择。此时网络剪枝不再在存储容量上具有优势。
RATIO OF WEIGHTS, INDEX AND CODEBOOK
剪枝操作使得权重矩阵变得稀疏,对于那些非0的元素就需要额外的空间来存储他们的索引。量化操作增加了对codebook存储空间。在上面的实验部分已经包含了这两种存储的介绍。图11展示了四种网络在量化的时候不同
成份的比例。因为平均来说权重和稀疏索引都是使用5bits来编码的,所以他们的存储比例是一半对一半。codebook的比例非常小,往往可以忽略。
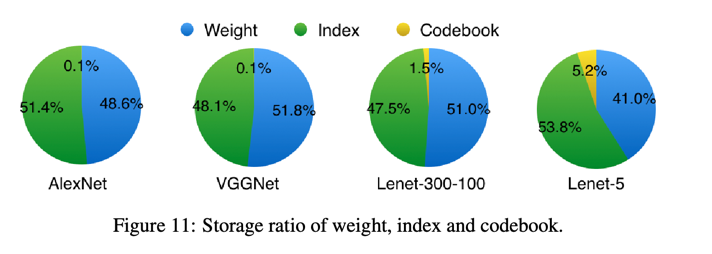
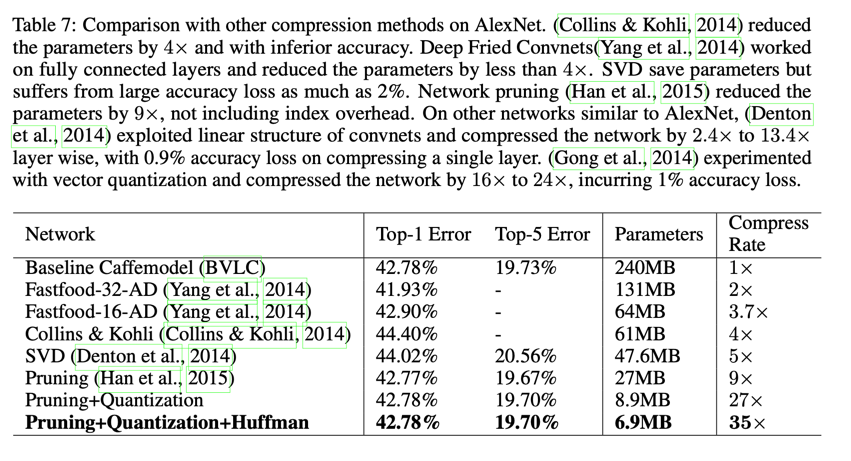
表7展示了使用不同的方法对AlexNet进行压缩,他们的准确率和压缩率的比较。
更多关于深度压缩的论文可以看这里 https://github.com/memoiry/Awesome-model-compression-and-acceleration
本文由 louis 创作,采用 知识共享署名4.0 国际许可协议进行许可
github 地址 https://github.com/7568/7568.github.io
最后编辑时间为:2022-10-28