简介
论文地址:https://arxiv.org/pdf/2106.01342.pdf
代码地址:https://github.com/somepago/saint
使用自监督和半监督来对表格型的数据进行神经网络的预训练
并且在论文TabTransformer上的基础上,设计了一个交叉注意力的网络
SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training
论文介绍
##TabTransformer
在介绍SAINT之前首先简短的介绍一下TabTransformer
TabTransformer是一个将transformer中的编码器应用在tabular数据上的方法,TabTransformer总体结构如下:
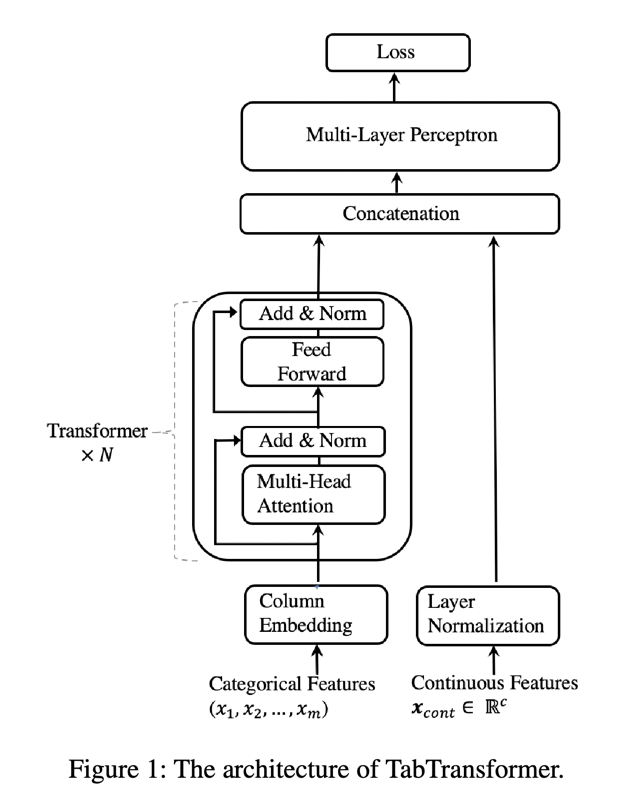
大概的步骤就是,先将tabular数据中的特征分成分类特征和连续值特征,如图中的左边为分类特征,右边为连续值特征。
然后将分类特征接入一个transformer模型中,得到的结果与连续值特征拼接起来,最后将拼接的结果接入一个多层全连接网络,得到输出。
在TabTransformer论文中作者还使用了一些自监督学习和半监督学习来对网络进行预训练,其主要思想来自VIME
关于在tabular训练的时候使用自监督学习和半监督学习,可以参考VIME
在TabTransformer中主要使用了两种预训练处理,分别是:
masked language modeling (MLM)
随机遮住一些内容然后视图回复,从而来进行对模型预处理
the replaced token detection (RTD)
随机替换掉一些数据,然后用多个不共享的判别器来分别判断特征是否被替换,一个特征一个判别器,从而来对模型进行预处理。
SAINT
1 针对TabTransformer中只是将类别特征放入transformer,然后将结果与连续值特征拼接起来,SAINT作者觉得这样做类别特征和 连续值特征之间一些相关的信息丢失。所以SAINT作者设计了一个网络,首先让分类特征数据和连续值数据分别映射到一个高维空间,然后 让他们同时经过transformer块,从而使得模型有更好的效果。
2 通常将数据放入transformer,注意力机制只会作用在特征之间,比如我们将一句话(”这是个很大的大学”)放入transformer中,那么transformer中的 自注意力机制就会去计算每个字与其他字之间的关系,然后再计算得到每个字的输出。在处理tabular数据的时候,每一条样本数据的不同特征就是相当于一个字, 然后transformer关注每个特征之间的关系,然后计算每个特征的输出,得到\(X(a)_1\),然后将其当作下一个transformer块的输入。本文的 作者提出一个multi-head intersample attention(MISA)的机制,在将 \(X(a)_1\)放入下一个transformer块之前,将\(X(a)_1\)转制一下, 再放入一个transformer块中得到结果\(X(a)_2\),也就是再将注意力机制关注到每个样本上,计算完成后 再将\(X(a)_2\)转制,放入下一个transformer块中。
SAINT中的MISA具体结构如下图:
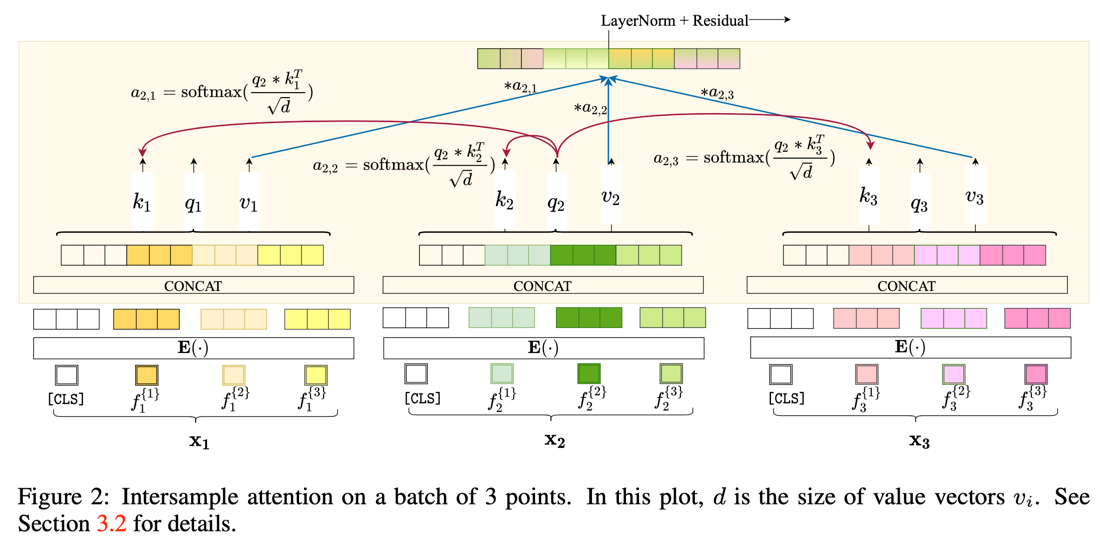
MISA可以用数学公式表示成如下:
![MISA_fomula]
其中E表示编码器,MSA表示multi-head self-attention block ,MISA表示multi-head intersample attention,FF表示全连接,LN表示层归一化。
MISA的伪代码如下:
# b: batch size , n: number of features , d: embedding dimension
# W_q , W_k , W_v are weight matrices of dimension dxd
# mm: matrix -matrix multiplication
def self_attention(x):
# x is bxnxd
q, k, v = mm(W_q ,x), mm(W_k ,x), mm(W_v ,x) #q,k,v are bxnxd
attn = softmax(mm(q,np.transpose(k, (0, 2, 1)))/sqrt(d)) # bxnxn
out = mm(attn, v) #out is bxnxd
return out
def intersample_attention(x):
# x is bxnxd
b,n,d = x.shape # as mentioned above
x = reshape(x, (1,b,n*d)) # reshape x to 1xbx(n*d)
x = self_attention(x) # the output x is 1xbx(n*d)
out = reshape(x,(b,n,d)) # out is bxnxd
return out
通过伪代码我们可以看到首先将样本进行一下reshape,增加一个维度,然后将每行数据进行维度的拉伸,也就是说每个样本有n个特征,然后每个特征被编码成d个维度。 这样放入self_attention中的时候就相当于batch为1,然后n个样本,每个样本的数据为n*d个特征。 然后放入到self_attention。 最后再reshape回来。
而如果不reshape,那么就是1个batch中有b个样本,每个样本有n个特征,每个特征编码成d个维度,这样self-attention的时候,计算的是每个样本内部各个特征 之间的attention。而在intersample_attention中,计算的是b个样本之间的attention。
基于MISA作者就提出了SAINT网络模型,结构如下:
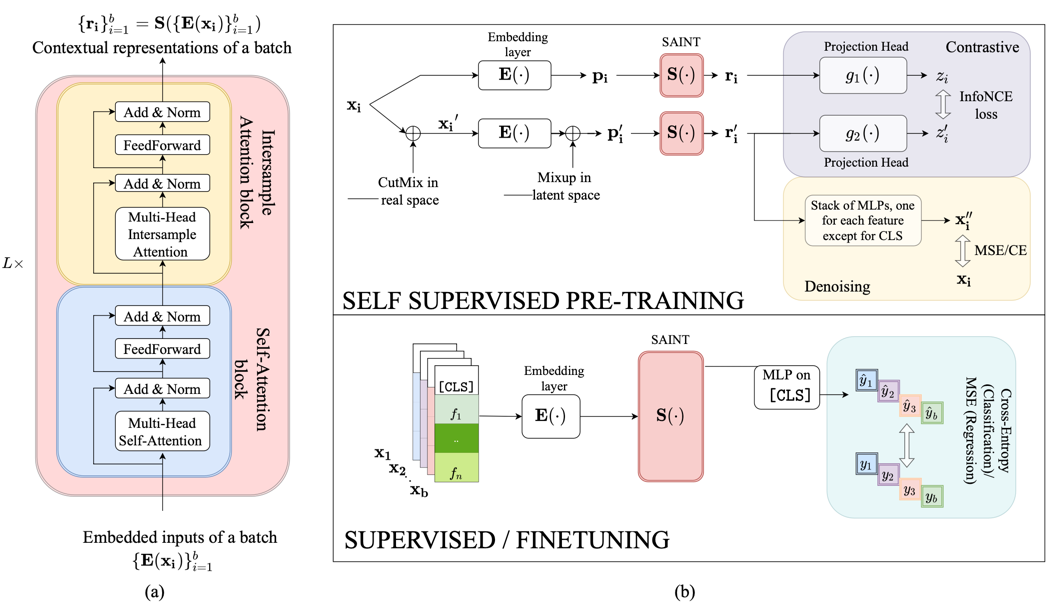
图中的(a)表示一个attention 的block,里面包含有两个小的block,一个是multi-head self-attention block (MSA)和 一个作者提出的multi-head intersample attention(MISA)
图中的(b)中上面表示自监督预训练的过程,下面表示有监督学习和调优的过程
然后作者还做了很多自监督的预训练,例如CutMix,mixup,来进行对比学习。
CutMix表示成如下:
![CutMix_architecture]
mixup表示成如下:
![mixup_architecture]
然后作者将这两种方法结合起来,一起来对模型进行预训练。
关于CutMix和mixup 可以参考这里
本文由 louis 创作,采用 知识共享署名4.0 国际许可协议进行许可
github 地址 https://github.com/7568/7568.github.io
最后编辑时间为:2022-10-28